爬蟲實戰 -- (爬取證券期貨市場失信記錄平臺)
阿新 • • 發佈:2019-01-09
這裡我們要通過實際展示爬取證券期貨市場失信記錄平臺上的搜尋資料。
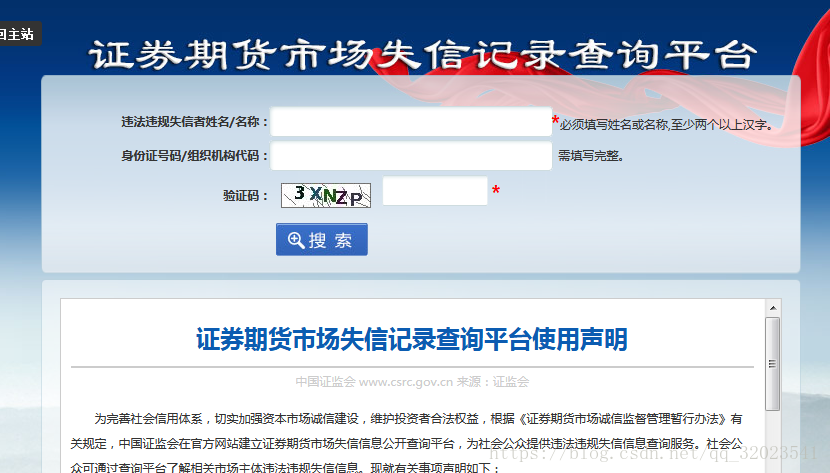
我們現在要通過爬蟲給定一個 姓名,機構程式碼 ,爬取獲得的結果。
這裡主要說明兩點:
1. 這是一個動態網頁,因此我採用 selenium 方法。
2.這裡的驗證碼圖片並不在原始碼內,因此前面的通過 css 選擇器直接下載的方式是不行的。並且給定的驗證碼圖片的連線即使一樣,生成的驗證碼也是隨機的,因此我們並不能通過原始碼中給定連結下載驗證碼這種方式。
驗證碼部分在原始碼解析如下:

這是一個連結,並且這個連結生成的驗證碼是會變動,並不能通過這個連結下載到我們要的驗證碼圖形。因此我的處理方案是直接截圖下來進行解析。解析採用 pytesseract 模組,但其實裡面原始碼就是呼叫 tesseract ,因此要安裝這個。
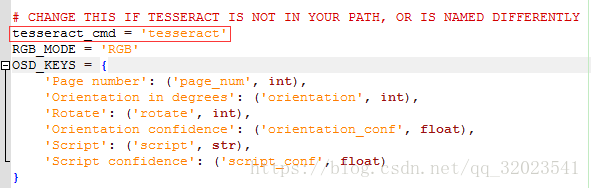
爬蟲完整程式碼如下:
# -*- coding:utf-8 -*- from PIL import Image import pytesseract from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains import sys reload(sys) sys.setdefaultencoding("utf-8") # 隱藏瀏覽器的顯式啟動,在除錯過程中不要隱藏 from selenium.webdriver.firefox.options import Options ff_option = Options() ff_option.add_argument('-headless') # 指定驅動程式 chromedriver = "C:\Program Files\Mozilla Firefox\geckodriver.exe" # 火狐驅動 driver = webdriver.Firefox(executable_path=chromedriver,firefox_options = ff_option) # 想要在選定的瀏覽器中載入網頁,可以呼叫 get() 方法,進入查詢網頁 driver.get("http://shixin.csrc.gov.cn/honestypub") # 定義解析驗證碼的函式 def parse_ycode(): # 先擷取整個頁面儲存為 screenshot.png driver.get_screenshot_as_file("screenshot.png") # 獲取驗證碼位置 captchaElem = driver.find_element_by_xpath('//*[@id="captcha_img"]') captchaX = int(captchaElem.location['x']) captchaY = int(captchaElem.location['y']) captchaWidth = captchaElem.size['width'] captchaHeight = captchaElem.size['height'] captchaRight = captchaX + captchaWidth captchaBottom = captchaY + captchaHeight # 開啟圖片並按照驗證碼的位置擷取驗證碼圖形 imgObject = Image.open("screenshot.png") im = imgObject.crop((captchaX, captchaY, captchaRight, captchaBottom)) # 處理驗證碼圖形便於解析 gray = im.convert('L') gray = gray.point(lambda x: 0 if x < 100 else 255,'1') yanzhengma = pytesseract.image_to_string(gray). \ strip(" ").replace(".","").replace("-","").replace("_","") # 驗證碼的長度應該是 5 ,否則就是解析錯誤了,所以返回 None if len(yanzhengma) == 5: return yanzhengma else: return None # 獲取驗證碼函式,主要是在解析結果為 None 時重新重新整理驗證碼進行解析 def get_ycode(name,card = ""): # 先 click,不要直接 send_keys,否則會重新整理驗證碼 driver.find_element_by_id("objName").click() driver.find_element_by_id("objName").clear() driver.find_element_by_id("objName").send_keys(name) driver.find_element_by_id("realCardNumber").click() driver.find_element_by_id("realCardNumber").clear() driver.find_element_by_id("realCardNumber").send_keys(card) print "驗證碼解析..." while True: ycode = parse_ycode() if ycode is None: # 如果解析錯誤,重新整理驗證碼重新解析 driver.find_element_by_id("captcha_img").click() else: break return ycode def reparse(): print "flush ycode again,because parse result is error" driver.find_element_by_id("captcha_img").click() return get_ycode() if __name__ == "__main__": while True: # 解析驗證碼 ycode = get_ycode("小明".decode("gbk"),card = "") # 輸入驗證碼 driver.find_element_by_id("ycode").click() driver.find_element_by_id("ycode").clear() driver.find_element_by_id("ycode").send_keys(ycode) # 模擬點選搜尋按鈕 點選 search driver.find_element_by_id("querybtn").click() # 獲取驗證碼輸入的結果 res = driver.find_element_by_css_selector(".search_bg > table:nth-child(2)\ > tbody:nth-child(1) > tr:nth-child(3) > td:nth-child(4)") res = res.text # 如果解析出錯,則重新重新整理驗證碼解析 if res.strip() == "驗證碼錯誤!".decode("gbk"): print "解析驗證碼不正確,重新重新整理驗證碼..." driver.find_element_by_id("captcha_img").click() continue else: print "驗證碼解析成功!" break # 驗證碼正確後獲取結果 result = driver.find_element_by_css_selector("#sorttab2") print result.text driver.close()
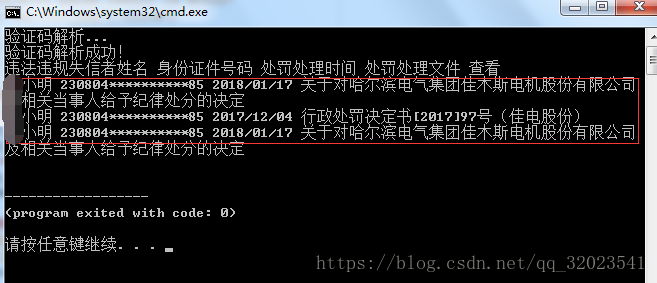
瀏覽器查詢結果如圖:
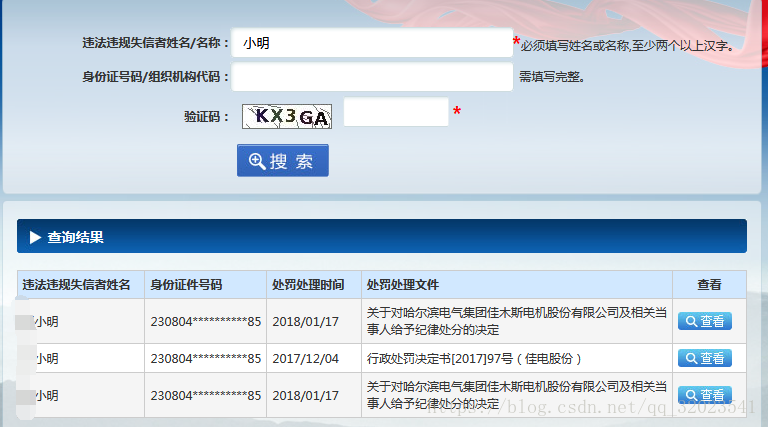
爬取結果如下: