
(三)Multi-class Classification and Neural Networks[多分類問題和神經網路]
這次打算以程式碼為主線,適當補充。
問題:
手寫數字識別。
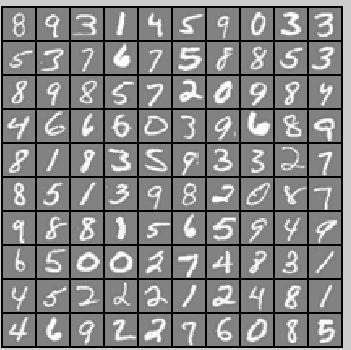
方法一:邏輯迴歸
for c = 1:num_labels
initial_theta = zeros(n + 1, 1);
% Set options for fminunc
options = optimset('GradObj', 'on', 'MaxIter', 50);
[theta] = fmincg (@(t)(lrCostFunction(t, X, (y == c), lambda)), ...
initial_theta, options);
all_theta(c, :) = theta';
end 上面的意思就是採用梯度下降的方法,迭代50次(呼叫50次lrCostFunction計算lrCostFunction又是何方神聖呢?下面就是lrcostFunction的主要內容
h = sigmoid(X * theta);
J = 1/m * ( -y' * log(h) -(1-y)' * log(1-h)) + lambda/(2*m) * (theta(2:end)' * theta(2:end));
G = theta;
G(1) = 0;
grad = 1/m * X' * (h-y) + lambda/m .* G;
這裡
得到了
pre = X * all_theta';
[maxVal, p] = max(pre, [], 2);
在訓練集上的準確率94.96%。
方法二:神經網路
什麼是神經網路?
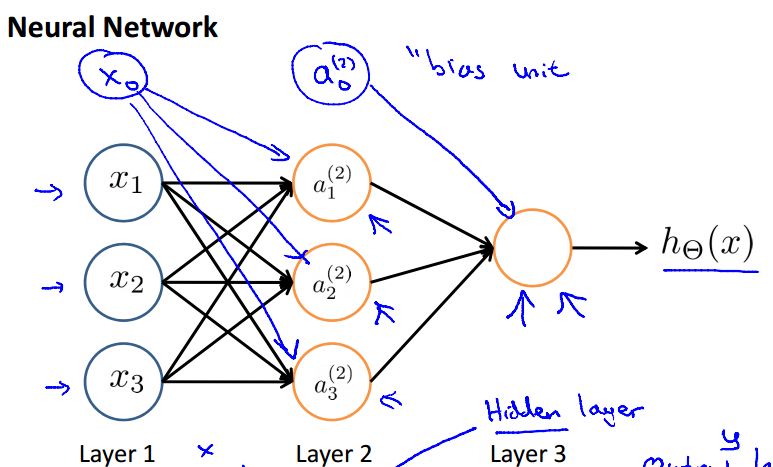
像這個樣子,有好幾層,中間是隱藏層,輸入層,輸出層。
目前看到的例子是用於分類,那麼它和邏輯迴歸有什麼異同點呢?
我是這麼理解的,可以認為是一群邏輯迴歸,一層一層的。比如對於邏輯迴歸,計算出
下面按照演算法步驟講解,首先要做的就是隨機初始化
function W = randInitializeWeights(L_in, L_out)
W = zeros(L_out, 1 + L_in);
epsilon_init = 0.12;
W = rand(L_out, 1 + L_in) * 2 * epsilon_init - epsilon_init;
end
這裡將
initial_nn_params = [initial_Theta1(:) ; initial_Theta2(:)];
下面是核心步驟:
options = optimset('MaxIter', 50);
costFunction = @(p) nnCostFunction(p, ...
input_layer_size, ...
hidden_layer_size, ...
num_labels, X, y, lambda);
[nn_params, cost] = fmincg(costFunction, initial_nn_params, options);
首先設定終止條件,迭代50次,接著定義nnCostFunction這裡面計算了fmincg傳入了三個引數,意思是利用初始的costFunction50次,這裡迭代次數為終止條件,所以nnCostFunction裡面究竟是什麼,其實它的目的就是計算
%% 首先把Theta1, Theta2還原
Theta1 = reshape(nn_params(1:hidden_layer_size * (input_layer_size + 1)), ...
hidden_layer_size, (input_layer_size + 1));
Theta2 = reshape(nn_params((1 + (hidden_layer_size * (input_layer_size + 1))):end), ...
num_labels, (hidden_layer_size + 1));
%% 樣本個數m
% Setup some useful variables
m = size(X, 1);
%% You need to return the following variables correctly
J = 0;
Theta1_grad = zeros(size(Theta1));
Theta2_grad = zeros(size(Theta2));
%% 正向傳播計算J
a1 = [ones(m, 1) X];
z2 = a1 * Theta1';
a2 = sigmoid(z2);
a2 = [ones(m, 1) a2];
z3 = a2 * Theta2';
a3 = sigmoid(z3);
Y = zeros(m, num_labels);
for i = 1:num_labels
Y(find(y == i), i) = 1;
end
% 計算J
Jc = (-Y .* log(a3) - (1-Y) .* log(1-a3));
J = 1/m .* sum( Jc(:) );
% 加上正則項
theta1 = Theta1;theta1(:,1) = 0;t1 = theta1 .^ 2;
theta2 = Theta2;theta2(:,1) = 0;t2 = theta2 .^ 2;
Regu = lambda/(2*m) * (sum(t1(:)) + sum(t2(:)));
J = J + Regu;
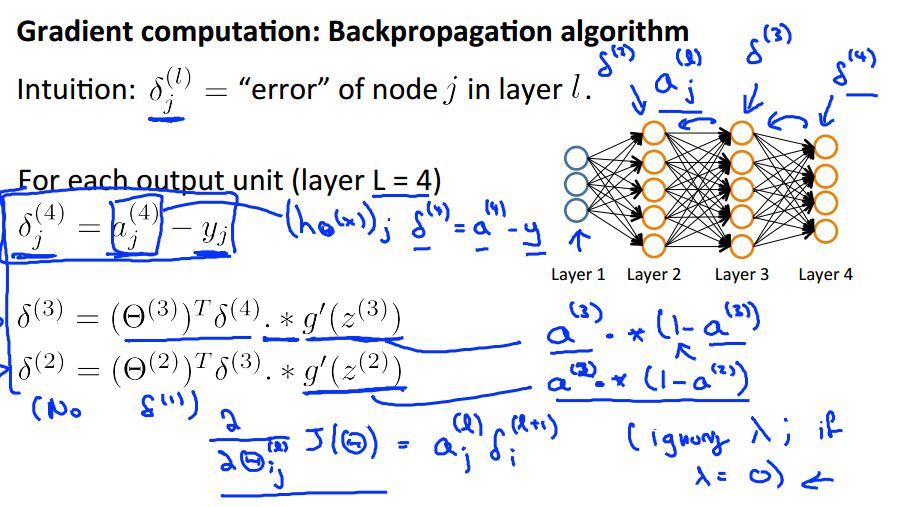
%% 反向傳播,為了計算Theta1, Theta2 的梯度
for t=1:m
delta3 = a3(t,:) - Y(t,:);
delta2 = delta3 * Theta2(:,2:end) .* sigmoidGradient(z2(t,:));
Theta2_grad = Theta2_grad + delta3' * a2(t,:);
Theta1_grad = Theta1_grad + delta2' * a1(t,:);
end
% 加上正則項
Theta1(:,1) = 0;Theta2(:,1) = 0;
Theta1_grad = 1/m .* Theta1_grad + lambda/m .* Theta1;
Theta2_grad = 1/m .* Theta2_grad + lambda/m .* Theta2;
% =========================================================================
% Unroll gradients
grad = [Theta1_grad(:) ; Theta2_grad(:)];
end
下面附上對應的數學公式:
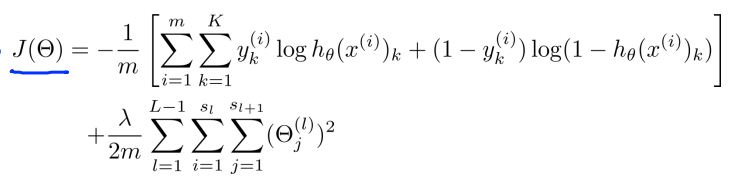

至此,正向(計算
梯度檢測Gradient checking
還剩下一點沒說,梯度檢測,梯度檢測就是為了看看

貼上程式碼看看:
nn_params = [Theta1(:) ; Theta2(:)];
costFunc = @(p) nnCostFunction(p, input_layer_size, hidden_layer_size, ...
num_labels, X, y, lambda);
[cost, grad] = costFunc(nn_params);
numgrad = computeNumericalGradient(costFunc, nn_params);
disp([numgrad grad]);
如果誤差很小,那麼就可以安心的training了!實際training的時候一般要註釋掉check的步驟,減少不必要的計算時間。
至此,關於數字識別的邏輯迴歸&神經網路算梳理複習完了,還是看著程式碼有一種更踏實的感覺,嘿嘿。