
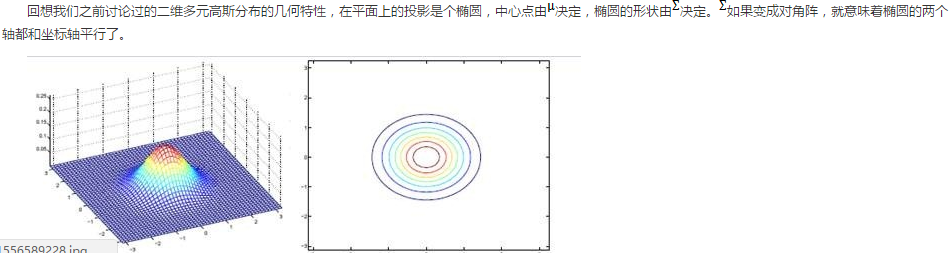
機器學習:Factor analysis因子分析
這部分內容還是挺奇怪的,學生的時候感覺不難啊,但是把覆盤的時候,總是各種難以明說的困惑,不知道是不是因為戒菸,注意力不夠專注,總之,學的不是很容易。
說歸來因子分析,解決的是維度高,樣本不足的情況下,模型建立的問題。我們之前講的混合高斯模型裡都是維度數遠小於樣本數的情況,如果維度是遠大於樣本數的話,我們仍然用以前的方法建立混合高斯模型會遇到問題,因為在這種情況,協方差會等於0,也就是說我們無法表示出高斯混合模型對應的概率密度。
對於這種情況,我們需要對協方差矩陣進行一些限定。有兩種限定方式。
第一種:我們假設各個特徵變數是獨立,也就是說協方差矩陣是一個對角矩陣,對角線上的值都不為零
第二種:相比於第一種是更強的假設

但這種假設,他的問題在於,他完全消除了變數之間的關聯性,而這個顯然是不符合實際的。我們因子分析要解決的就是怎樣估計出一個 合理的,非奇異協方差矩陣。
在我們介紹因子分析方法之前,我們需要對 邊緣分佈 和 條件分佈有一些基本的瞭解。因為在因子分析EM演算法中,要用到這部分的知識。
在這裡我們假設 x1和x2的聯合分佈是一個多維高斯分佈模型
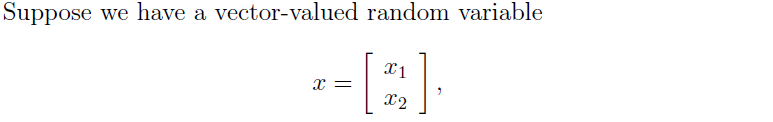
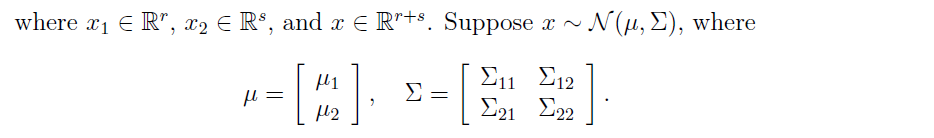
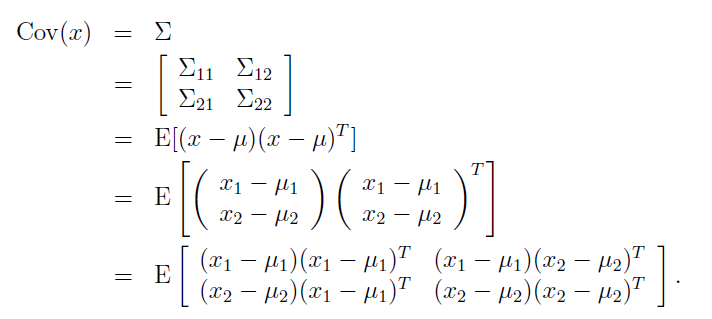
我們有了上述的協方差矩陣表示之後,我們就可以求出條件分佈。
這一步就是套公式嗎!對吧?


有了以上的概念之後,我們就正式來介紹因子分析,以及他的EM演算法,我們要尤其注意,**他是怎麼估計協方差矩陣的?**因為我們都知道,我們之所以用因子分析,是因為他對協方差矩陣估計的時候,充分考慮到變數之間的相關性,那我們要在接下來的演算法尤其要注重這點,這也是理解這個演算法模型的重點! 唉!!!!!
The Factor analysis model
在因子模型中,我們是這樣假設的。
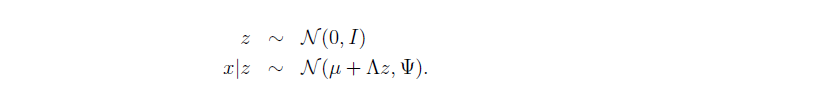
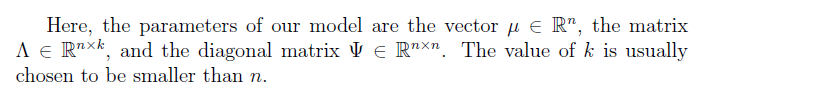

接下來我們想算出來,z,x組成的聯合高斯分佈到底是什麼樣的? 之所以要這麼做事因為,我們是最終想知道x的分佈是什麼樣的,想想我們一直想做的事情不就是想用引數擬合一個樣本資料嗎?

也就是說接下來我們要求這樣幾個值,zz得協方差矩陣,zx的協方差矩陣,xx的協方差矩陣。
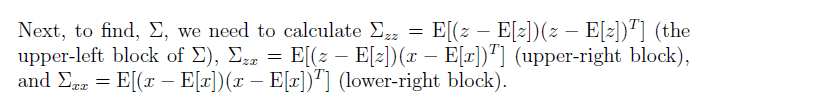
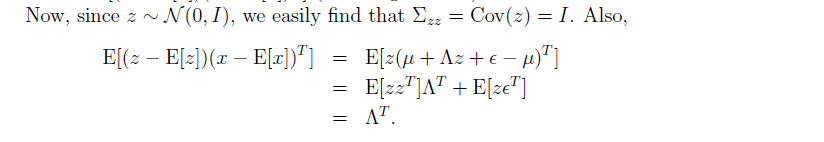
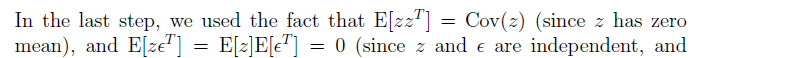
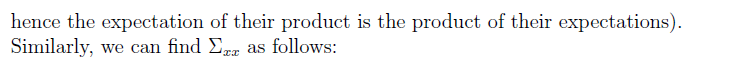
通過上述,我們就求出了協方差矩陣,我們也就可以把z,x的分佈給表示出來,如下:
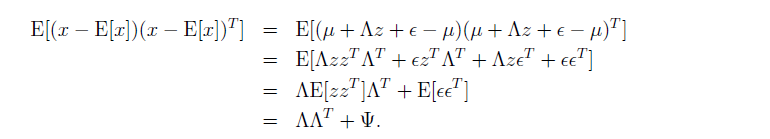
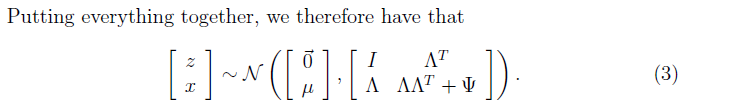
有了這個方程的表示,我們要做的就是對他進行最大似然,我們會看到,如果直接求得會比較麻煩,我們需要用EM演算法
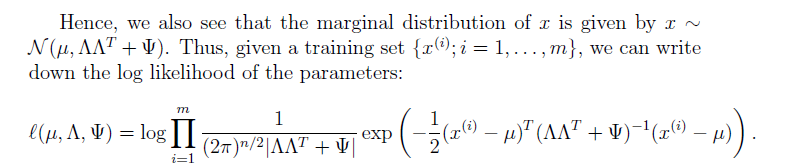
在EM演算法中,我們首先要計算x條件下z的概率Q(z),根據我們之前的條件概率表示方法,我可以得出Q(z)


接下就是M步驟,也好理解了。
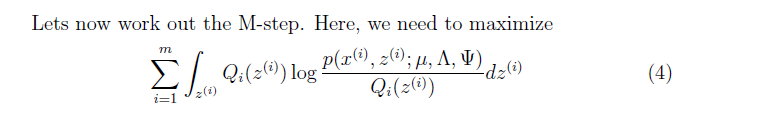


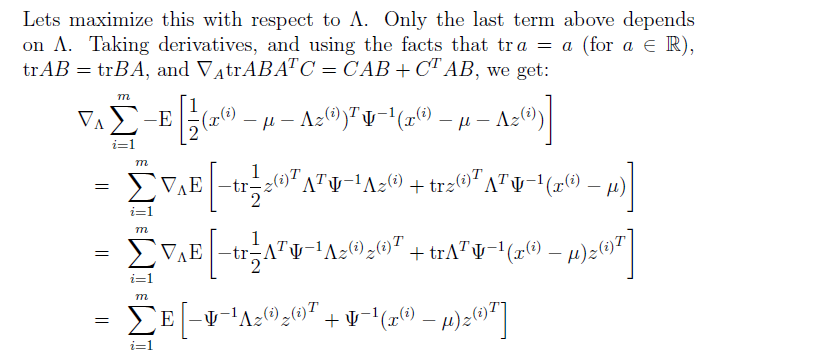
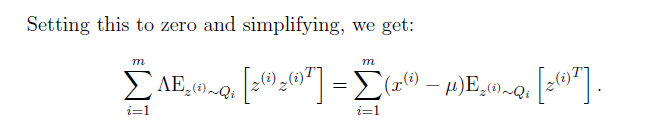
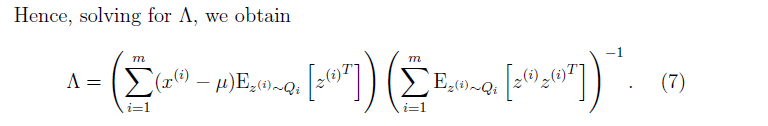

在這裡我們能看到,我們因子分析模型同高斯模型的不同點,因子模型中,在更新引數的時候是把z的協方差考慮在內了。
以上是給出了算出其他兩個引數的方法
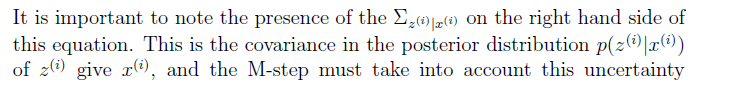


cry!cry! 好艱難,寫這篇部落格,煙也戒掉了,我是在戒菸的時間裡寫了這篇部落格,注意力不集中,實在是痛苦,整整用了6天時間
如果你看到這裡,請掃以下我得支付寶紅包
