
用python爬取網貸之家p2p平臺數據
阿新 • • 發佈:2019-01-09
網貸之家中的p2p平臺數據比較容易獲取,重要的就是如何分析網頁的原始碼然後從裡面提取自己需要的資訊,也不需要使用者登入,該網站的爬蟲比較簡單,主要用了urllib包來獲取網頁資訊,用BeautifulSoup來解析網頁,最後用正則表示式提取資料。這裡就直接上原始碼了:
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 8 18:22:26 2018
@author: 95647
"""
import urllib
from urllib.request import urlopen
from bs4 import BeautifulSoup
import 寫該程式碼之前,還沒有學習panda的用法,所以簡單粗暴的用列表和字典來解決問題,會使用pandas的朋友可以用pandas來進行優化。爬蟲執行過程如下:

該爬蟲執行速度很快,我爬取了100個正常運營平臺的資訊,才用了5分鐘左右,部分爬蟲結果如下:
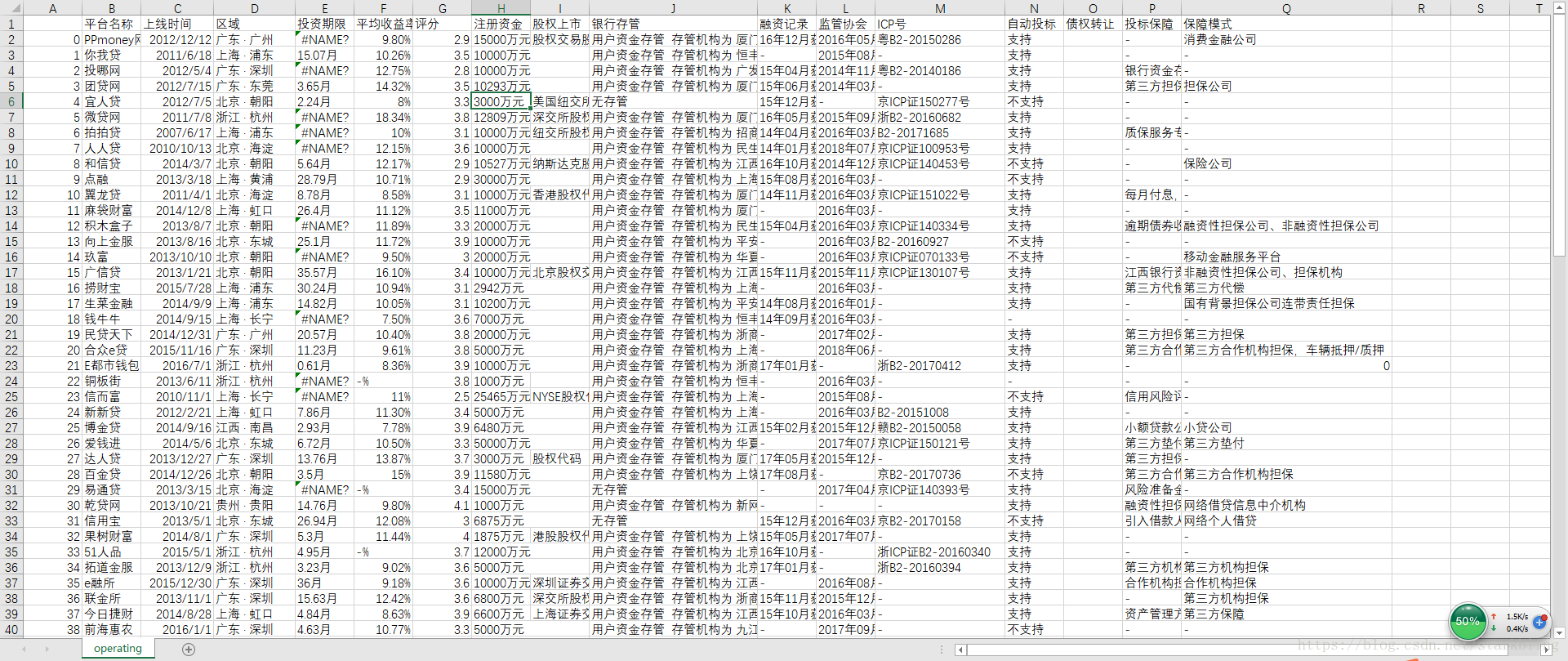
有問題的和其他想法的朋友,歡迎加QQ:956471511交流,這裡還有一篇關於如何爬取人人貸網站資料的博文,有興趣的朋友可以看一下。手把手教你用python爬取人人貸借款人資料