
Spark+Python+Pycharm在Windows下的配置
初次學習在大資料平臺下做資料分析和資料探勘,之前主要是在MATLAB上在一些資料分析,雖然很熟悉了,然而受速度和方便程度的影響,畢竟還是不太方便做實時的、叢集的、超大資料量的分析,因此決定放下用了6年的MATLAB,轉戰python+spark。
為何選擇python+spark?選擇spark是毋庸置疑的,目前最先進的大資料平臺,可是為什麼選擇python而不選擇spark同樣支援的scala、Java和R呢?這個純粹是個人愛好,目前還沒有找到具體的理由,也可能是最近看了幾個java開發的應用程式,覺得java的程式量非常大,對這一點沒有多少好感吧,而對Scala不熟悉,python和R的風格感覺跟MATLAB還是比較像的,個人覺得,python的適用範圍可能比R更加廣泛一些吧,因此就選擇了python+spark。
本系列的部落格我想寫一些我個人學習使用spark的一些親歷過程,可能有些是原創的,有些會是轉載修改的,如果有問題,歡迎大家給我郵件( - 選擇系統平臺
- python安裝
- pycharm安裝
- Hadoop和spark的安裝
現在來逐一分析,把這幾個問題分析和除錯做好了,環境也就搭建好了。
第一,在系統的選擇上我嘗試了三種:Linux系統、VM虛擬機器+Ubuntu和Windows7。很不幸,前兩種我都沒能在我的PC上搭建成功,第一種可能是我的電腦硬體不支援雙系統吧,安裝Linux的時候總是在關鍵的時候直接自動關機了;第二種下現在在Windows的安裝經驗下,是可以裝成功的,之前要裝什麼都不熟悉,而且對Linux的一些操作方式還不是很熟悉,折騰了很久也沒能成功,但留下了一些寶貴的經驗,僅供參考,可能有些我沒注意的地方會有問題,接受大家的指正——
1) sudo wget http://... 從網上獲取資源,即下載
2) sudo tar zxvf *.tar.gz 解壓縮檔案
3) sudo mv a/ b/ 將資料夾a重新命名為b
4) vi ~/ .bashrc 編輯環境變數(Vi的使用每次都出問題,感覺很不方便編輯,有好的方法希望大家推薦一下!)
5) 設定java的環境變數
sudo gedit /etc/profile 在檔案末尾加上 /home/ydq/spark/software/jdk1.7/jre
export JAVA_HOME=~/spark/software/jdk1.7/
export CLASSPATH=.:$JAVA_HOME 相信對於剛入門的人來說,還是隻對Windows熟悉的居多,因此建議在這個階段還是先在Windows下搭建,反正spark和python都是跨平臺的,轉過去也容易,這麼做不影響後面核心的演算法實現,想通了這一點我毫不猶豫的選擇了Windows7
第二,python在Windows下的安裝非常簡單,可以參照http://jingyan.baidu.com/article/8cdccae97f7d26315413cd88.html,後面需要學會用pip來安裝庫檔案,沒有強大的庫檔案,python可就不那麼好用了喲!比如安裝matplotlib
pip search matplotlib
pip install matplotlib
第三,在此也不贅述Pycharm的安裝了,都可以在官網上找到.exe或者.msi檔案,下載下來雙擊安裝即可,在Pycharm中選好直譯器為Python即可
第四步,Hadoop和spark的安裝。其實也是最重要的一步和最困惑我的一步,現在做好了其實這一步也是很簡單的。首先在官網上去下載這兩個壓縮包,解壓後都是免安裝的

HADOOP_HOME:G:\Windows_Spark\hadoop2.6_Win_x64-master
SPARK_HOME:G:\Windows_Spark\spark-1.6.2-bin-hadoop2.6
path:%HADOOP_HOME%\bin;G:\Windows_Spark\spark-1.6.2-bin-hadoop2.6\bin;
具體的HADOOP_HOME和SPARK_HOME是依賴於每個人在自己pc上解壓的位置而定的,不過千萬要注意
HOME目錄後面是沒有分號的,path目錄後面是有分號的!
HOME目錄後面是沒有分號的,path目錄後面是有分號的!
HOME目錄後面是沒有分號的,path目錄後面是有分號的!
重要的事情說三遍,我在這裡就出錯了,後面查錯用了兩天都沒有找到問題所在,還是走在路上的時候突然想到了這個小細節才改過來的,否則後面執行pyspark測試的時候是會報錯的哦。
做好了這一切就可以測試一下是否安裝成功了,在控制檯(windows+R,cmd)上輸入pyspark,如果出現瞭如下情況則表示spark環境搭建成功了。
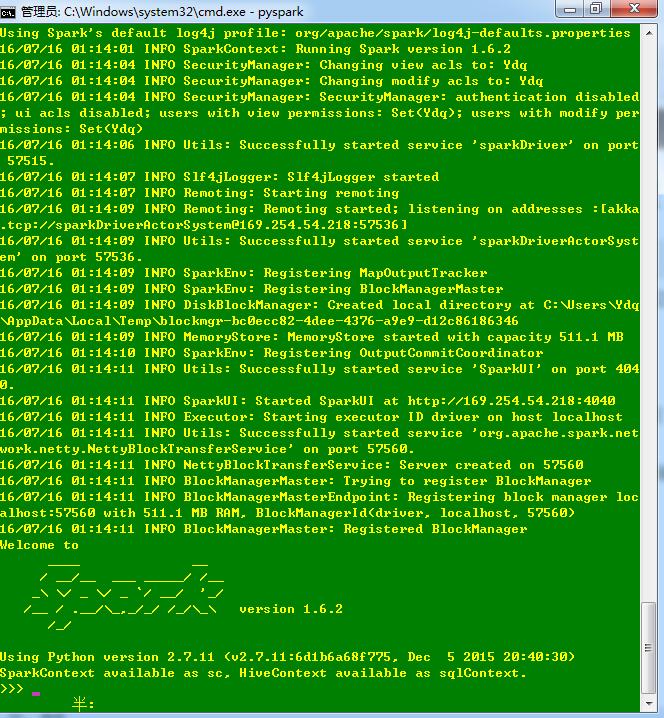
之後可以用pip install py4j命令在cmd控制檯下安裝相關外掛,然後就可以程式設計了。
順便說一下,如果習慣於java的話,也是可以配置eclipse,和maven,以及JDK。
接下來就是我在網上下載的一份簡單的spark程式碼,共勉學習!
from pyspark import SparkContext
sc = SparkContext('local')
doc = sc.parallelize([['a','b','c'],['b','d','d']])
words = doc.flatMap(lambda d:d).distinct().collect()
word_dict = {w:i for w,i in zip(words,range(len(words)))}
word_dict_b = sc.broadcast(word_dict)
def wordCountPerDoc(d):
dict={}
wd = word_dict_b.value
for w in d:
if dict.has_key(wd[w]):
dict[wd[w]] +=1
else:
dict[wd[w]] = 1
return dict
print doc.map(wordCountPerDoc).collect()
print "successful!"執行結果如下圖所示:

在此,就不一一分析本程式的程式碼了,後面我會寫一系列博文,來分析spark的程式碼。