
Python爬蟲爬取51job招聘網站
阿新 • • 發佈:2019-01-09
最近學習爬蟲,做了一個python爬蟲工具寫在這裡記錄一下。
# python爬51job工具,稍微改改就可以爬其他網站 # edit by mengqi Date:2018-07-11 # encoding:uft-8 import csv # 爬下來的資料要寫到csv檔案中,所以要引入這個模組 from urllib import request, error from lxml import etree # 元素樹用來進行xpath語法解析時, import random # 這裡我構造了五個瀏覽器的user-agent,防止被檢測出來 # 1. get_html()這個函式是將給定url和encode方式,返回為html的字串形式 def get_html(url,encode='utf-8'): try: ua_value1 = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) " \ "Gecko/20100101 Firefox/61.0" ua_value2 = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 ' \ '(KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36' ua_value3 = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 ' \ '(KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11' ua_value4 = 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US)' \ ' AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16' ua_value5 = 'Mozilla/5.0 (Windows NT 6.1; WOW64)' \ ' AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER' # 建立user-agent集合,模擬瀏覽器登陸 ua = (ua_value1, ua_value2, ua_value3, ua_value4, ua_value5) # 元組裡面的東西不能隨便被修改 req = request.Request(url) # 3.構建爬蟲請求物件 req.add_header("User-Agent", random.choice(ua)) # 4.在請求頭中新增Uer-Agent response = request.urlopen(req) # 5.傳送請求並獲取伺服器的響應物件response html_str2 = response.read().decode(encode) # 6.從響應物件中讀取網頁中的原始碼(響應正文) except error.URLError: # 拋異常,如果是url錯誤的話執行這個 print('url 請求錯誤') except error.HTTPError: print('請求錯誤') except Exception: print('程式錯誤') return html_str2 def crawl_onepage(html_str1): # 這個方法用來將獲取到的str格式的html進行xpath解析到rows這個列表中 html_ = etree.HTML(html_str1) # 將html字串結構轉換成html文件結構 html = etree.ElementTree(html_) # 將html文件結構轉換成元素樹結構 # 使用xpath語法進行資料清洗 div_el = html.xpath('//div[@id="resultList"]/div[@class="el"]') # 獲取id=“resultlist‘ 內所有的class=’el‘的div,div的列表 rows = list() # 通過for迴圈尋找每一行el資料 for index, el in enumerate(div_el): # el資料型別是html文件型別 el = etree.ElementTree(el) # 同上:需要將html文件結構再轉換成元素樹的格式(節點) title = el.xpath('/div/p/span/a/@title') # 職位名 title = title[0] if title else None link = el.xpath('/div/p/span/a/@href') # 進入詳情頁的地址 link = link[0] if link else None company = el.xpath('/div/span[@class="t2"]/a/@title') # 公司 company = company[0] if company else None city = el.xpath('/div/span[@class="t3"]/text()') # 工作地點 city = city[0] if city else None salary = el.xpath('/div/span[@class="t4"]/text()') # 薪水 salary = salary[0] if salary else None time = el.xpath('/div/span[@class="t5"]/text()') # 釋出時間 time = time[0] if time else None child_str = get_html(link, 'gbk') child_ = etree.HTML(child_str) child = etree.ElementTree(child_) # 元素樹(只有節點才能使用xpath語法) exp = child.xpath('//div[@class="jtag inbox"]/div/span/em[@class="i1"]/parent::span/text()') exp = exp[0] if exp else None degree = child.xpath('//div[@class="jtag inbox"]/div/span/em[@class="i2"]/parent::span/text()') degree = degree[0] if degree else None fuli = child.xpath('//div[@class="jtag inbox"]/p/span/text()') fuli = fuli if fuli else None # 福利就是一個列表,需要將列表轉成字串 row = (title, company, city, salary, time, exp, degree, fuli) # 將每一行資料封裝到元祖中 # print(row) rows.append(row) # 每次獲取到的職位相關資訊,放入到空列表中 return rows def csv_write(filename,mode,content): # 用於寫入csv檔案的方法 with open(filename, mode, newline ="",encoding ='utf-8') as job: # 用指定的mode方式開啟filename檔案,指定了編碼格式 file = csv.writer(job) if mode == 'w': # 寫的方式,覆蓋寫 file.writerow(content) if mode == 'a': #append方式寫,不覆蓋 file.writerows(content) def crawl_manypage(keyword,start,end): # 爬取多頁資料,第一個引數表示關鍵字,第二個是開始頁,第三個是結束頁 head = ('職位', '公司', '工作地點', '薪資', '釋出時間', '工作經驗', '學歷', '福利') # 第一行資料表頭 csv_write('{}.csv'.format(keyword), 'w', head) # 呼叫剛才的csv_write方法 for page in range(start, end+1): # page變數是頁數 url1 = 'https://search.51job.com/list/010000,000000,0000,00,9,99,{},2,{}.html?' \ 'lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99' \ '&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=' \ '&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='.format(keyword,page) html_str = get_html(url1,'gbk') # 按照gbk的編碼格式獲取html字串 rows = crawl_onepage(html_str) # 呼叫函式爬取一頁資料 csv_write('{}.csv'.format(keyword), 'a', rows) # 寫入到csv檔案中 # 51job通過協程實現併發爬蟲 crawl_manypage('python',1,3)
然後開啟pycharm中的python.csv檔案右鍵選擇file encoding,選擇gbk,就可以用excel開啟看到了:
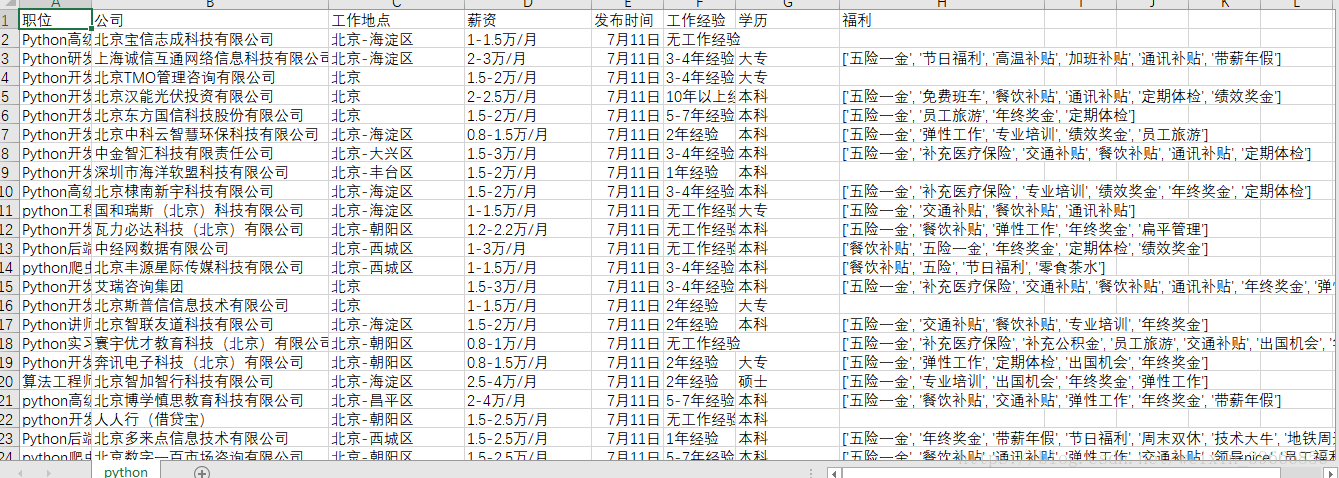
下一篇會對這個爬蟲進行優化,並將爬蟲結果做簡要分析