
Python爬蟲爬取網站新聞
網站分析
爬取過程
獲取新聞連結地址
使用requests包讀取新聞列表頁面,然後使用正則表示式提取出其中的新聞頁面連結,返回urls列表
def getList(url):
li = requests.get(url)
res = r'url":"http:.*?.html'
urls = re.findall(res,li.text)
for i in range(len(urls)):
urls[i] = urls[i][6:]
return urls獲取新聞內容
使用requests獲取到新聞頁面的內容,然後使用BeautifulSoup包解析web內容。
def getNews(url):
url = url[:-5]+"_0.html"
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser")
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
type = soup.find("div","position lBlue").contents[3].string.encode('utf-8' 手機簡版新聞通常把一個新聞分成幾個頁面顯示,導致爬取內容很麻煩。經過分析發現,在新聞連結地址後加_0即可顯示全部新聞內容,所以先處理一下連結地址。然後使用requests獲取web頁面,再用BeautifulSoup提取新聞的標題,時間,類別和內容。
將結果儲存
def saveAsTxt(news):
file = open('E:/news.txt' 執行程式
程式程式碼
# encoding: utf-8
import requests
import re
from bs4 import BeautifulSoup
import time
class News:
def __init__(self,title,time,type,content):
self.title = title #新聞標題
self.time = time #新聞時間
self.type = type #新聞類別
self.content = content #新聞內容
def getList(url): #獲取新聞連結地址
li = requests.get(url)
res = r'url":"http:.*?.html' #正則表示式獲取連結地址
urls = re.findall(res,li.text)
for i in range(len(urls)):
urls[i] = urls[i][6:]
return urls
def getNews(url): #獲取新聞內容
url = url[:-5]+"_0.html" #處理連結獲取全文
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser") #獲取新聞內容,注意編碼
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
# type = soup.find("div","position lBlue").contents[3].string.encode('utf-8')
content = soup.find("div","content").get_text()[1:-1].encode('utf-8')
news = News(title,time,type,content)
return news
def saveAsTxt(news): #儲存新聞內容
file = open('E:/news.txt','a')
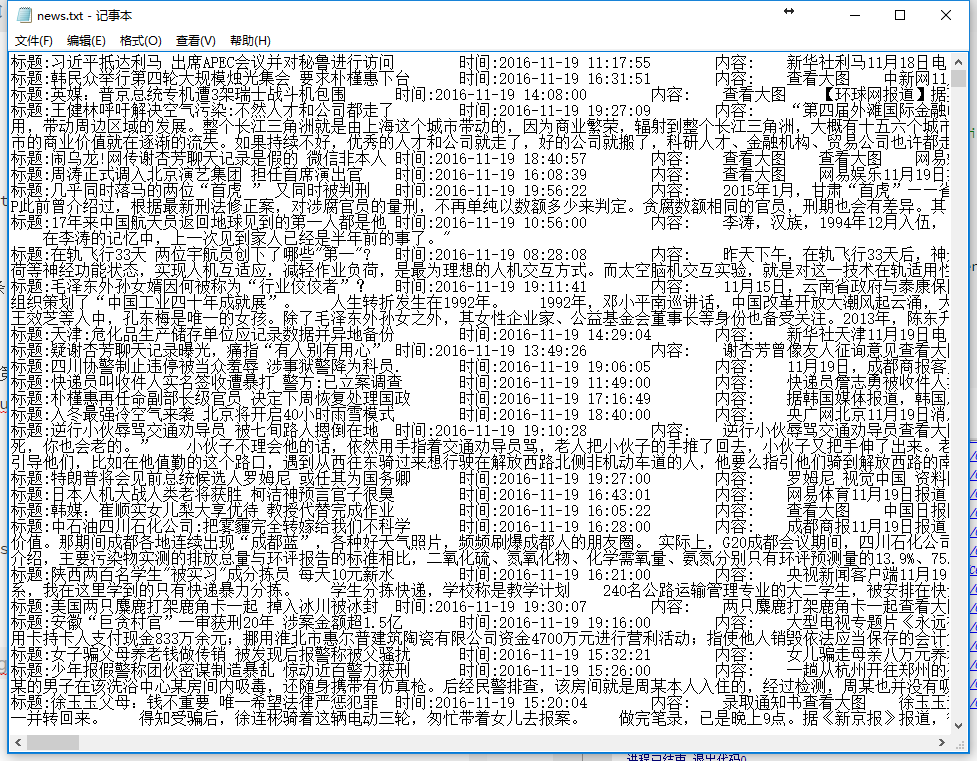
file.write("標題:" + news.title +
"\t時間:" + news.time +
# "\t型別:"+ news.type +
"\t內容:"+ news.content +
"\"\n")
start = time.clock()
sum = 0
for i in range(1,40):
wangzhi = "http://3g.163.com/touch/article/list/BA8J7DG9wangning/%s-40.html" %i
urls = getList(wangzhi)
sum = sum + len(urls)
# print "當前頁解析出 %s 條" %len(urls)
j = 1
for url in urls:
print "正在讀取第%s頁第%s/%s條:%s" %(i,j,len(urls),url.encode('utf-8'))
news = getNews(url)
saveAsTxt(news)
j = j + 1
end = time.clock()
print "共爬取%s條新聞,耗時%f s" %(sum,end - start)
執行結果
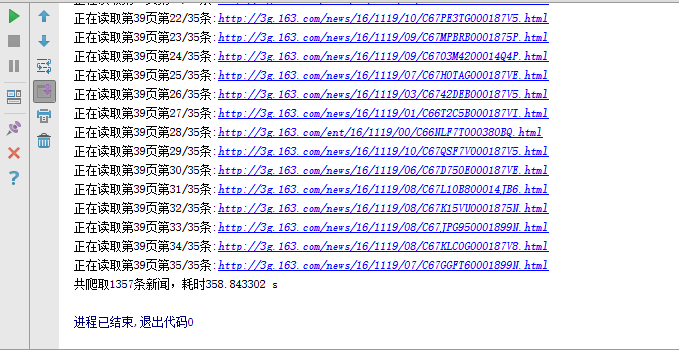
程式執行的時間主要和頁面開啟的速度有關,若網速理想的話程式執行還是挺快的。
注
該程式還屬於入門級的爬蟲,代理ip池以及多執行緒效率問題都沒有涉及到。但是如果附加上你需要這些後續處理,比如
有效地儲存(資料庫應該怎樣安排)
有效地判重(這裡指網頁判重,咱可不想把人民日報和抄襲它的大民日報都爬一遍)
有效地資訊抽取(比如怎麼樣抽取出網頁上所有的地址抽取出來,“朝陽區奮進路中華道”),搜尋引擎通常不需要儲存所有的資訊,比如圖片我存來幹嘛…
及時更新(預測這個網頁多久會更新一次)
如你所想,這裡每一個點都可以供很多研究者十數年的研究。(知乎:謝科)
附錄
相關推薦
Python爬蟲——爬取網站的例項化原始碼
缺點:1爬了一個網站好幾次以後不能再進行爬取。沒有解決這個問題 2在寫入資料的時候還是存在很大問題。以後多加練習這個檔案的儲存的相關工作 import re import urllib.request def function(): """需求:1 https://re
Python爬蟲 爬取網站上的圖片
Python爬蟲 爬取網站上的圖片
Python爬蟲爬取網站新聞
網站分析 爬取過程 獲取新聞連結地址 使用requests包讀取新聞列表頁面,然後使用正則表示式提取出其中的新聞頁面連結,返回urls列表 def getList(url): li = requests.get(url) re
python 爬蟲爬取 證券之星網站
爬蟲 周末無聊,找點樂子。。。#coding:utf-8 import requests from bs4 import BeautifulSoup import random import time #抓取所需內容 user_agent = ["Mozilla/5.0 (Windows NT 10.0
Python爬蟲爬取美劇網站
一直有愛看美劇的習慣,一方面鍛鍊一下英語聽力,一方面打發一下時間。之前是能在視訊網站上面線上看的,可是自從廣電總局的限制令之後,進口的美劇英劇等貌似就不在像以前一樣同步更新了。 但是,作為一個宅diao的我又怎甘心沒劇追呢,所以網上隨便查了一下就找到一個能用迅雷下載的美劇
python爬蟲爬取拉勾網站內容
本次主要內容是分享下拉勾網站模擬搜尋以及搜尋內容的爬取,這裡先引入一些用到的庫,由於網站本身的反爬蟲技術和網路原因,這裡使用了fake_useragent和多執行緒模式,當然如果有條件的話也可以使用代理池,這樣可以更加保險一點。由於我沒有弄那些收費的代理,而免費
python 爬蟲爬取某網站的漫畫
文章目錄 宣告 前言 思路 流程 程式 結果 宣告 為了表示對網站的尊重,已將網站地址隱藏,下載的漫畫之前我就看過了,所以也會刪掉,絕不侵犯網站的利益。 前言
Python爬蟲爬取古詩文網站專案分享
作為一個靠python自學入門的菜鳥,想和大家分享自己寫的第一個也是目前為止唯一一個爬蟲程式碼 寫爬蟲要具備的能力基礎:python入門基礎,html5基礎知識,然後這邊用的是scrapy框架,所以
Python爬蟲爬取51job招聘網站
最近學習爬蟲,做了一個python爬蟲工具寫在這裡記錄一下。# python爬51job工具,稍微改改就可以爬其他網站 # edit by mengqi Date:2018-07-11 # encoding:uft-8 import csv
使用python爬蟲爬取百度手機助手網站中app的資料
一、爬取程式流程圖 爬蟲程式流程圖如下: Created with Raphaël 2.1.0開始分析地址結構獲得app類別頁的url爬取app詳情頁url爬取App詳情頁的資料將爬取資料儲存到json檔案結束 二、具體步驟 1.分析
Python爬蟲-爬取糗事百科段子
hasattr com ima .net header rfi star reason images 閑來無事,學學python爬蟲。 在正式學爬蟲前,簡單學習了下HTML和CSS,了解了網頁的基本結構後,更加快速入門。 1.獲取糗事百科url http://www.qiu
python爬蟲爬取頁面源碼在本頁面展示
一個 nts ring 想要 strip code 空白 列表 ngs python爬蟲在爬取網頁內容時,需要將內容連同內容格式一同爬取過來,然後在自己的web頁面中顯示,自己的web頁面為django框架 首先定義一個變量html,變量值為一段HTML代碼 >&
python爬蟲爬取海量病毒文件
tle format nbsp contex logs request spl tde __name__ 因為工作需要,需要做深度學習識別惡意二進制文件,所以爬一些資源。 # -*- coding: utf-8 -*- import requests import re
用Python爬蟲爬取廣州大學教務系統的成績(內網訪問)
enc 用途 css選擇器 狀態 csv文件 表格 area 加密 重要 用Python爬蟲爬取廣州大學教務系統的成績(內網訪問) 在進行爬取前,首先要了解: 1、什麽是CSS選擇器? 每一條css樣式定義由兩部分組成,形式如下: [code] 選擇器{樣式} [/code
python爬蟲——爬取古詩詞
爬蟲 古詩詞 實現目標 1.古詩詞網站爬取唐詩宋詞 2.落地到本地數據庫頁面分析 通過firedebug進行頁面定位: 源碼定位: 根據lxml etree定位div標簽:# 通過 lxml進行頁面分析 response = etree.HTML(data
利用Python爬蟲爬取淘寶商品做數據挖掘分析實戰篇,超詳細教程
實戰 趨勢 fat sts AI top 名稱 2萬 安裝模塊 項目內容 本案例選擇>> 商品類目:沙發; 數量:共100頁 4400個商品; 篩選條件:天貓、銷量從高到低、價格500元以上。 項目目的 1. 對商品標題進行文本分析 詞雲可視化 2.
Python爬蟲 - 爬取百度html代碼前200行
http src mage bsp bubuko str 百度 爬蟲 圖片 Python爬蟲 - 爬取百度html代碼前200行 - 改進版, 增加了對字符串的.strip()處理 Python爬蟲 - 爬取百度html代碼前200行
簡易python爬蟲爬取boss直聘職位,並寫入excel
python爬蟲寫入excel1,默認城市是杭州,代碼如下#! -*-coding:utf-8 -*-from urllib import request, parsefrom bs4 import BeautifulSoupimport datetimeimport xlwt starttime = dat
Python 爬蟲爬取微信文章
微信爬蟲 爬取微信文章 爬取公眾號文章搜狗微信平臺為入口 地址:http://weixin.sogou.com/ --------------------------------------------------------------搜索關鍵詞“科技”對比網址變化情況查看網址http://wei
python爬蟲爬取QQ說說並且生成詞雲圖,回憶滿滿!
運維開發 網絡 分析 matplot 容易 jieba 編程語言 提示框 然而 Python(發音:英[?pa?θ?n],美[?pa?θɑ:n]),是一種面向對象、直譯式電腦編程語言,也是一種功能強大的通用型語言,已經具有近二十年的發展歷史,成熟且穩定。它包含了一組完善而且