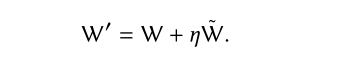DRN: A Deep Reinforcement Learning Framework for News Recommendation學習
阿新 • • 發佈:2019-01-09
歡迎轉載,請註明出處https://blog.csdn.net/ZJKL_Silence/article/details/85798935。
本文提出了(基於深度Q-learning 的推薦框架)基於強化學習的推薦系統框架來解決三個問題:
1)首先,使用DQN網路來有效建模新聞推薦的動態變化屬性,DQN可以將短期回報和長期回報進行有效的模擬。
2)將使用者活躍度(activeness score)作為一種新的反饋資訊,不僅僅考慮點選率作為回報。
3)使用Dueling Bandit Gradient Descent方法來進行有效的探索。
當前強化學習中已經提出增加一些隨機性到決策中,來尋找新的物品。e-greedy或者UCB主要作為多臂賭博方法,因為e-greedy可能給消費者推薦完全不相關的物品,然而,UCB只有對物品進行多次嘗試,才可以得到相對準確的回報估計。這兩種方法在短期內可能損害推薦的效能,這裡採取更加有效的探索。
本文用競爭賭博梯度下降方法進行探索。通過在當前推薦的鄰居候選物品中隨機選擇一些物品,這樣介意避免推薦完全不相關的物品,因此可以保持較好的推薦準確性。
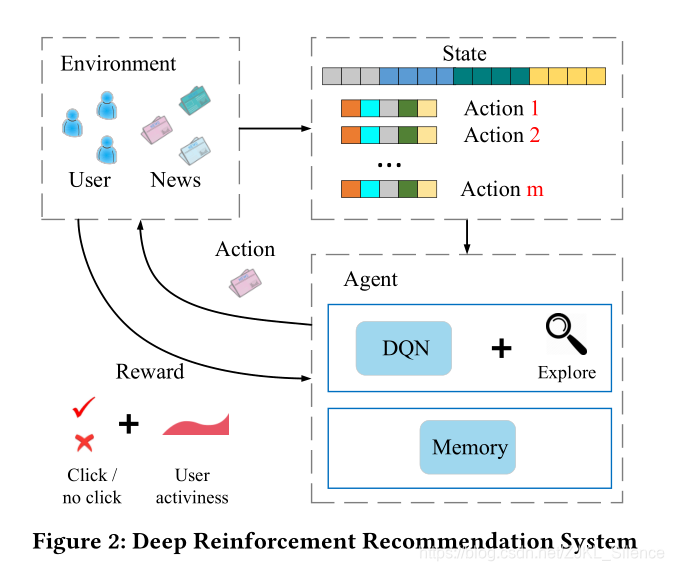
對於上圖,描述了強化學習的四個必要因素:
狀態:使用者的特徵
動作:物品(新聞)特徵
環境:使用者和物品池
回報:點選率和使用者的活躍度
強化過程
該框架優點:
1、可以處理高度動態的新聞推薦,由於可以線上更新DQN。同時,DQN網絡卡可以推斷使用者和物品之間將來的互動。
2、結合使用者的活躍度和來最使用者反饋的點選率作為 回報。
3、利用DBGD策略更改推薦多樣性。
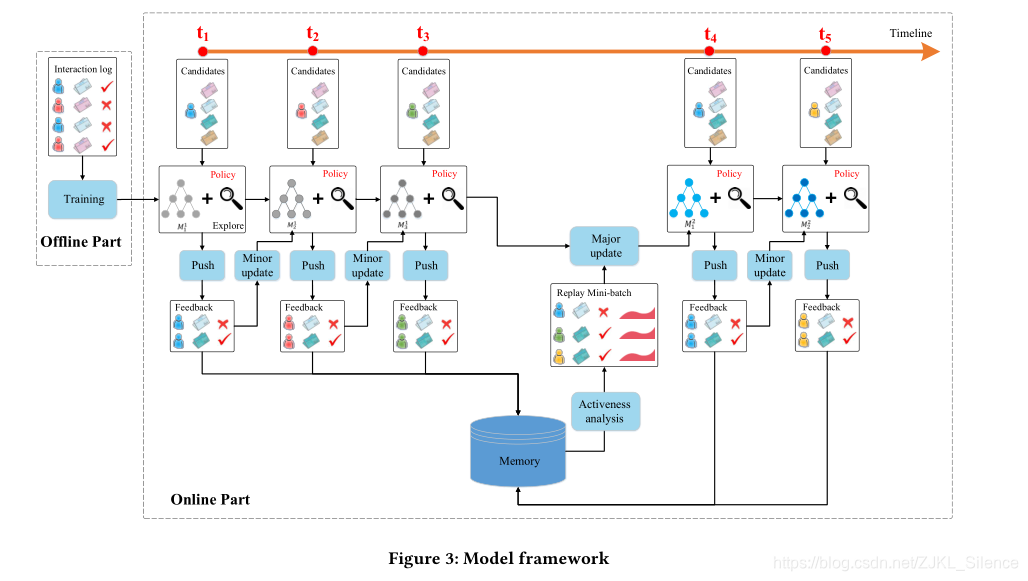
模型框架包括線下階段和線上階段:
線下階段:抽取使用者和物品的四種特徵。利用使用者和物品的點選記錄進行訓練該網路。
四種特徵:新聞特徵,進行one-hot編碼後的417維度特徵;使用者特徵413*5=2065;使用者新聞特徵:使用者和新聞之間的互動特徵25;上下文特徵32;
線上學習部分:我們推薦代理G將於使用者進行互動,並按照以下方式更新網路:
(1)push:在每個時間戳使用者像系統法師弓一個新聞請求,推薦代理G將當前使用者和候選的新聞的特徵表示作為DQN網路的輸入並生成新聞推薦列表L,L的產生是結合當前模型的利用和新穎物品的探索。
(2)反饋:使用者u將根據推薦新聞列表L,其點選率做為反饋
(3)次要更新:在每個時間戳之後,先前使用者的特徵表示,其推薦列表L,反饋B。代理G將通過利用Q網路和探索網路Q’比較推薦的效能。若Q’能夠給出較好的推薦,將當前網路朝著Q’網路更新,否則保持Q網路不變。
(4)主要更新:在經過一段時間T後,代理將利用使用者的反饋和儲存在記憶體中的使用者的活躍度和反饋更新Q網路。因此我們將利用
經驗重放技術
模型的整個回報
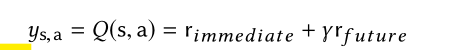
對於DDQN的reward:
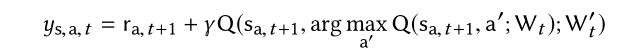
這裡t+1是因為回報總是延時;
使用者的活躍度
利用使用者的生存分析構建使用者的活躍度;

利用DBGD演算法進行探索

代理G使用當前Q網路產生推薦表L;利用探索網路Q’產生推薦列表L’;在原來Q網路的W基礎上,增加小的擾動到當前的Q網路中:
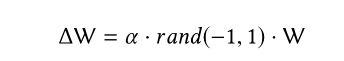
將使用概率交錯演算法演算法首先隨機的在L和L’選擇物品,假設L被選中,來自列表L的物品i,將通過在L中的排序以確定性的概率放入L’中。然後推薦列表L’作為使用者u的推薦列表,並得到反饋B。若利用探索網路Q’獲得比較好的反饋,代理將更新Q網路朝著Q’網路進行更新。引數更新如下: