
論文閱讀 | A Deep Relevance Matching Model for Ad-hoc Retrieval
阿新 • • 發佈:2018-11-10
A Deep Relevance Matching Model for Ad-hoc Retrieval
(2016 CIKM)
模型細節
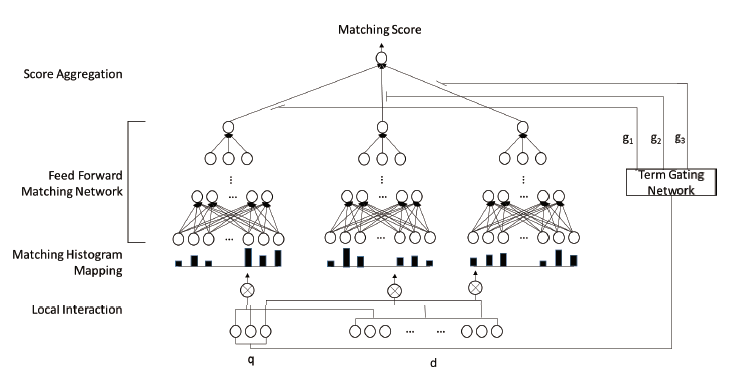
1.對於query中的每個詞建立mapping直方圖
輸入:
query中的每個詞和doc所有詞產生term pair,對於每一個pair使用相似度計算(論文中使用了cos距離),考慮到位置對於匹配問題其實沒有影響,此處不用位置資訊,而是將每個pair的相似度進行分級(即文中說的直方圖)- 例如:將餘弦相似度[-1, 1]分為五個區間{[-1,-0.5), [-0.5,-0), [0,0.5), [0.5,1), [1,1]} 。給定query中的一個詞“car”以及一篇文件(car, rent, truck, bump, injunction, runway), 得到對應的區域性互動空間為(1, 0.2, 0.7, 0.3, -0.1, 0.1),最後我們用基於計數的直方圖方法得到的直方圖為[0,1, 3, 1, 1]。
對於直方圖的生成有三種形式:

直方圖相對於matching matrix的優點:
1.通過直方圖,區別不同的匹配訊號,而不像matching matrix所有匹配訊號都混雜在一起
2.不需要zero padding,在matching matrix 中對於短文字需要進行padding,從而對其造成影響
2.輸入到前饋神經網路
對於query的每個詞形成的直方圖輸入到前饋神經網路
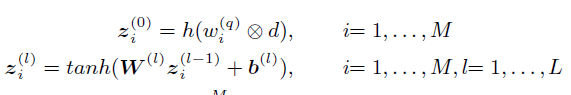
表示了對每個query生成直方圖的過程
表示輸入前饋神經網路的過程
3.產生最後的匹配分數
對於每個query詞產生的
,最後通過一個gating network
生成最後的分數,類似於注意力機制
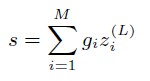
其中,

此處有兩種方式:
(1)TV:
為query embedding,
為與embeding同等維度的weight vector
(2)IDF:
為query的idf,
為一個標量需要學習
結果分析
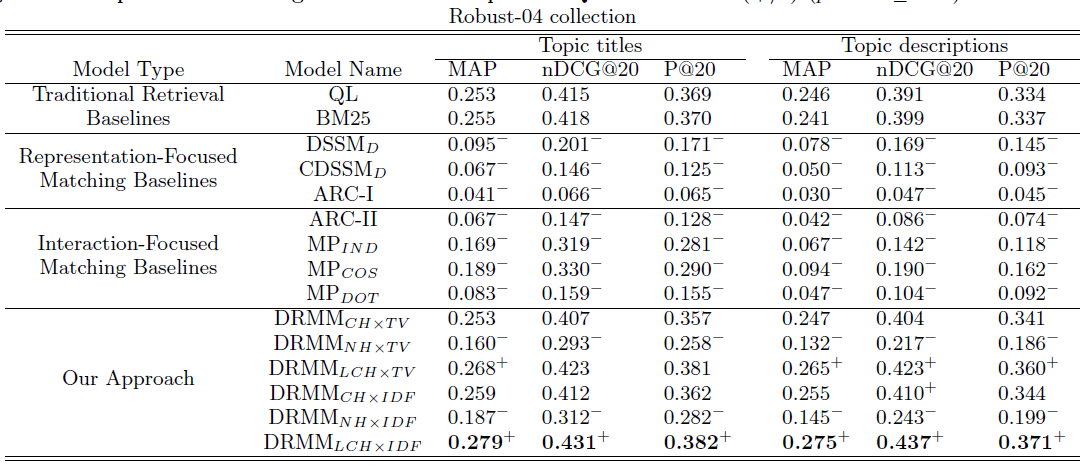
(1)加入idf非常有用
(2)NH方法效果很差,可能因為失去了doc長度,而doc長度在匹配問題中其實很有用