
大資料入門之Spark快速入門及匯入資料,求平均值
執行環境
本文的具體執行環境如下:
- CentOS 7.6
- Spark 2.4
- Hadoop 2.6.0
- Java JDK 1.8
- Scala 2.10.5
一、下載安裝
首先在官網
https://spark.apache.org/downloads.html
下載對應版本的Spark
丟到你的伺服器上 自己的路徑 比如 /user/hadoop/My_Spark
解壓
tar -xvf XXX.tar.gz(你的壓縮包名稱)
然後 記錄你的 路徑 /user/hadoop/My_Spark/spark-2.4.0-bin-hadoop2.7
配置spark使用者許可權
sudo chown -R hadoop:hadoop ./spark # 此處的 hadoop 為你的使用者名稱 ./spark為你的路徑名
安裝後,需要在 ./conf/spark-env.sh 中修改 Spark 的 Classpath,執行如下命令拷貝一個配置檔案:
- cd /user/hadoop/My_Spark/spark-2.4.0-bin-hadoop2.7
- cp ./conf/spark-env.sh.template ./conf/spark-env.sh
編輯 ./conf/spark-env.sh(vim ./conf/spark-env.sh
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
儲存後,Spark 就可以啟動運行了。
當然 還少不了設定環境變數
vi ~/.bash_profile
在最後加入
# spark
export SPARK_HOME= (你的Spark路徑)
export PATH=$PATH:$SPARK_HOME/bin
執行 Spark 示例
注意,必須安裝 Hadoop 才能使用 Spark,但如果使用 Spark 過程中沒用到 HstudentS,不啟動 Hadoop 也是可以的。此外,接下來教程中出現的命令、目錄,若無說明,則一般以 Spark 的安裝目錄(/usr/local/spark)為當前路徑,請注意區分。
在 ./examples/src/main 目錄下有一些 Spark 的示例程式,有 Scala、Java、Python、R 等語言的版本。我們可以先執行一個示例程式 SparkPi(即計算 π 的近似值),執行如下命令:
- cd /user/hadoop/My_Spark/spark-2.4.0-bin-hadoop2.7 #你的路徑
- ./bin/run-example SparkPi
通過 Spark Shell 進行互動分析
Spark shell 提供了簡單的方式來學習 API,也提供了互動的方式來分析資料。Spark Shell 支援 Scala 和 Python,本教程選擇使用 Scala 來進行介紹。
ScalaScala 是一門現代的多正規化程式語言,志在以簡練、優雅及型別安全的方式來表達常用程式設計模式。它平滑地集成了面向物件和函式語言的特性。Scala 運行於 Java 平臺(JVM,Java 虛擬機器),併兼容現有的 Java 程式。
Scala 是 Spark 的主要程式語言,如果僅僅是寫 Spark 應用,並非一定要用 Scala,用 Java、Python 都是可以的。使用 Scala 的優勢是開發效率更高,程式碼更精簡,並且可以通過 Spark Shell 進行互動式實時查詢,方便排查問題。
執行如下命令啟動 Spark Shell:
- ./bin/spark-shell
啟動成功後如圖所示,會有 “scala >” 的命令提示符。
成功啟動Spark Shell

基礎操作
Spark 的主要抽象是分散式的元素集合(distributed collection of items),稱為RDD(Resilient Distributed Dataset,彈性分散式資料集),它可被分發到叢集各個節點上,進行並行操作。RDDs 可以通過 Hadoop InputFormats 建立(如 HstudentS),或者從其他 RDDs 轉化而來。
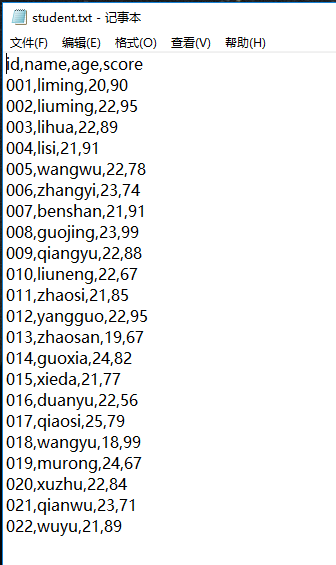
我們從本地路徑讀取一個預先準備好的student.txt檔案
student.txt 檔案內容如下 有四個欄位 id name age score
在互動式視窗中輸入
import org.apache.spark.sql.types._
import org.apache.spark.sql.SparkSession
val spark=SparkSession.builder().getOrCreate()
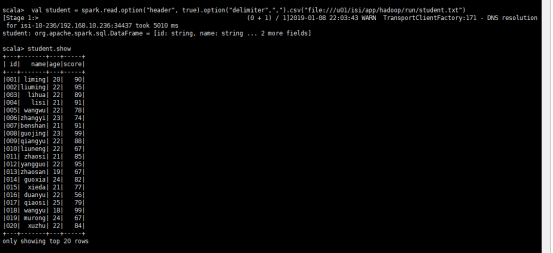
val student = spark.read.option("header", true).option("delimiter",",").csv("file:///user/hadoop/run/student.txt")
這裡student是 spark的一個DataFrameReader 也就是RDD DataFrame 通過讀取本地檔案獲得的。
整個相當於一個臨時的表
我們這裡以CSV格式讀入 分隔符為 , 然後首行開啟
程式碼中通過 “file://” 字首指定讀取本地檔案。Spark shell 預設是讀取 HstudentS 中的檔案,需要先上傳檔案到 HstudentS 中,否則會有“org.apache.hadoop.mapred.InvalidInputException: Input path does not exist:”的錯誤。
DataFrame基本動作運算
show展示資料
可以用show() 方法來展示資料,show有以下幾種不同的使用方式:
show():顯示所有資料
show(n) :顯示前n條資料
show(true): 最多顯示20個字元,預設為true
show(false): 去除最多顯示20個字元的限制
show(n, true):顯示前n條並最多顯示20個自負
student.show() student.show(3) student.show(true) student.show(false) student.show(3,true)
輸入
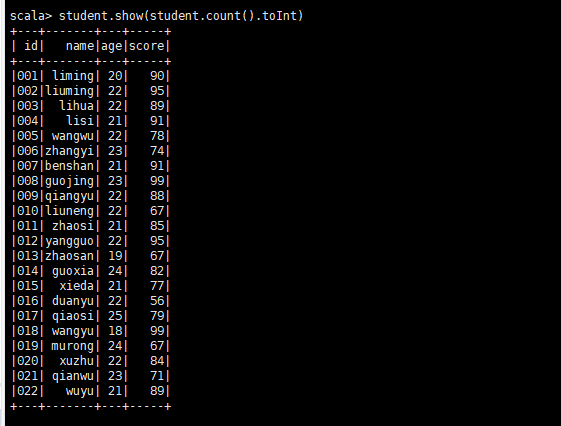
student.show(student.count().toInt)
按成績倒序排序輸出
輸入student.sort(student("score").desc).show(student.count().toInt)
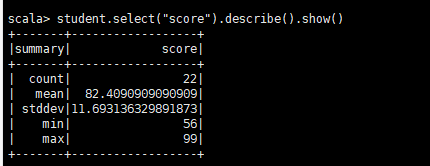
describe(cols: String*):獲取指定欄位的統計資訊
這個方法可以動態的傳入一個或多個String型別的欄位名,結果仍然為DataFrame物件,用於統計數值型別欄位的統計值,比如count, mean, stddev, min, max等。

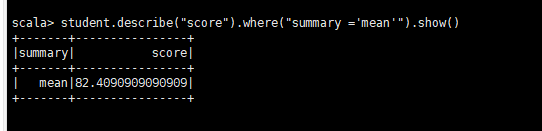
求平均分數並輸出
單個DataFrame操作
使用where篩選條件
where(conditionExpr: String):SQL語言中where關鍵字後的條件 ,傳入篩選條件表示式,可以用and和or。得到DataFrame型別的返回結果, 比如我們想得到使用者1或者使用助手1的操作記錄:
student.where("user=1 or type ='助手1'").show()
或者如上圖
student.describe("score").where("summary ='mean'").show()
select:獲取指定欄位值
根據傳入的String型別欄位名,獲取指定欄位的值,以DataFrame型別返回,比如我們想要查詢user和type兩列:
student.select("user","type").show()
其他的常用操作自己看文件就行,女加微信男自強。本次教程暫時到此結束。
退出
:quit