
python爬蟲實戰(關於工作中遇到的問題)
主要是說一下大體的思路,在爬蟲網站的時候遇到樂一些困難,最後解決。
需要爬蟲的網站:http://www.jisilu.cn/
在這個網站中,需要對實時投資資料進行爬取,涉及到四個頁面分級A、分級B、母基金、分級套利。
主要是採集表格中的資料:
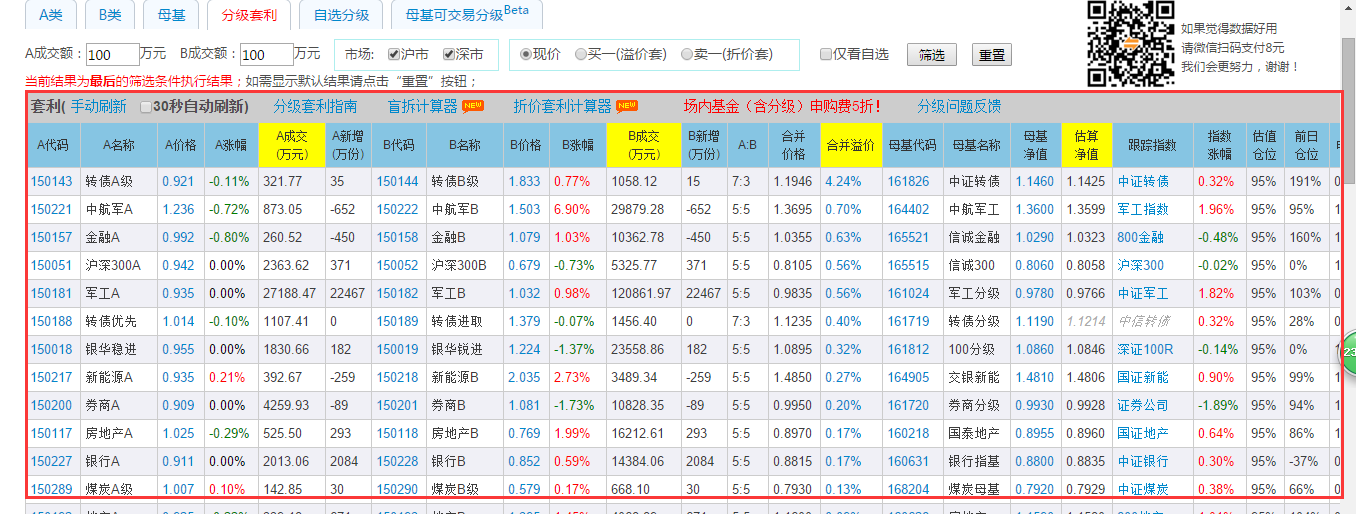
但是四個頁面有一些不同,分級套利介面需要登陸之後,才可以檢視當前的資料,而且四個頁面的資料都是js動態加載出來的,在前面對於分級A、分級B、母基金頁面的時候,採用了python的spynner+pyqt4採集技術,BeautifulSoup解析所採集到的頁面資料,這裡還是主要說spynner技術採集頁面,在採集分級套利介面的時候,頁面返回資訊提示,當前介面需要登陸才能訪問到資料。
理所當然,我百度了網路上登陸所需要的程式碼和工具。網路抓包工具推薦使用Fiddler4工具。
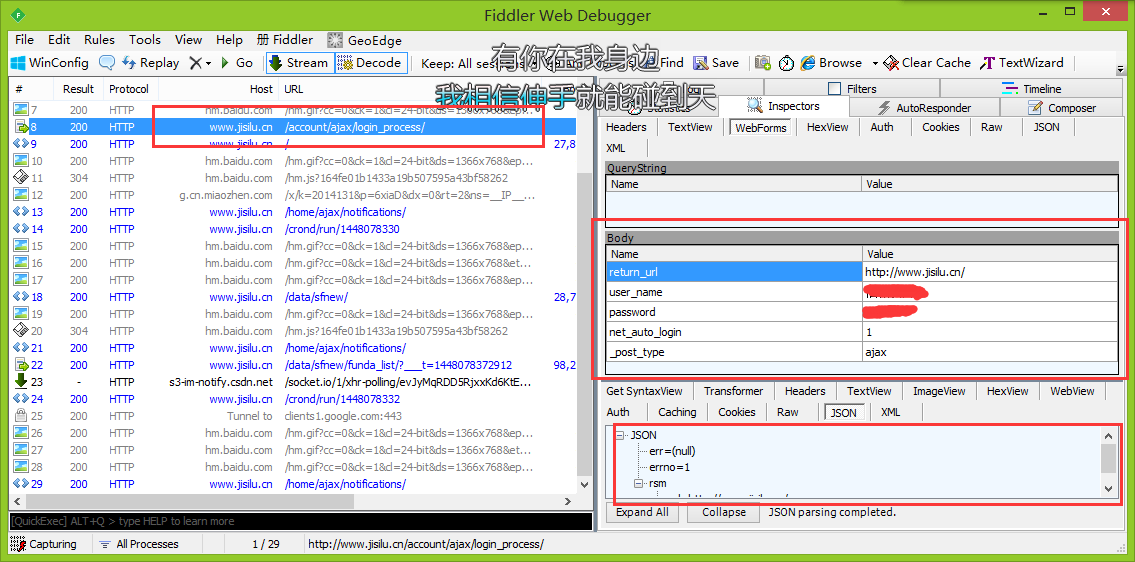
大家可以在左頁面獲取到url,右邊可以檢視post或者get資料,還有header頭資訊和獲取到的返回資料。
我當時在這邊主要碰到的問題是,我之前所採用的技術spynner是如何設定cookies的,我當時閱讀了spynner的原始碼,發現spynner中是存在設定cookies的方法:
原始碼:
@property
def cookiesjar(self):
"""Compat."""
return self.manager.cookieJar()
@property
def cookiejar 主要是set_cookies方法,傳入的值需要的格式沒有具體說明,一直都搞不明白,直到現在還是不清楚,應該傳入的格式,如果有知道的,希望能指點一下。
這個時候,使用urllib2實現了登陸,但是登陸完之後的js動態採集資料,urllib2是獲取不到的,用spynner+pyqt4是獲取的到js動態載入的資料,此時就產生了分歧,我當時的做法就是想把urllib2所獲取到的cookies設定進spynner中,這樣結合起來就可以實現登陸,獲取動態資料,但是由於spynner設定cookies的困難,使我陷入了進退兩難之間,也是這個想法讓我陷入的死衚衕。
說說我最後是如何採集到資料的,其實很簡單,最後在採集的時候已經實現了登陸,那麼就算是介面採用js動態載入,但是資料的獲取離不開url請求,介面只是負責資料的展現,我在觀察Fidder4中的連結,有一個連結是資料的獲取,然後我採用這個連結直接獲取資料來源,這樣就不用去獲取整個介面的頁面,然後解析。
附錄
spynner採集程式碼:
import spynner
def get_web_a():
url_a = "http://www.jisilu.cn/data/sfnew/#tlink_3"
br_a = spynner.Browser()
if br_a.load(url_a, load_timeout=30):
print br_a.html
soup = BeautifulSoup.BeautifulSoup(br_a.html)
tags = soup.findAll('tr')
print type(tags)
for tag in tags:
print tagurllib2登陸程式碼採集程式碼:
url_login = "http://www.jisilu.cn/account/ajax/login_process/"
url_data = "http://www.jisilu.cn/data/sfnew/arbitrage_vip_list/"
_post_type = "ajax"
net_auto_login = "1"
user_name = ""
password = ""
return_url = "http://www.jisilu.cn/data/sfnew/"
login_params = {
"user_name": user_name,
"password": password,
"return_url": return_url,
"net_auto_login": net_auto_login,
"_post_type": _post_type
}
headers = {
"Referer": "http://www.jisilu.cn/login/",
"Connection": "keep-alive",
"Accept": "application/json, text/javascript, */*; q=0.01",
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36"
}
cj = None
opener = None
req = None
response = None
operate = None
def get_cookielib():
global cj, opener
cj = cookielib.LWPCookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
def login():
global req, response, operate
req = urllib2.Request(url_login, urllib.urlencode(login_params), headers=headers)
response = urllib2.urlopen(req)
operate = opener.open(req)
thePage = response.read()
print thePage
import time
timestamp = "%d" % (time.time() * 1000)
req_data_params = {
"___t": str(timestamp)
}
req = urllib2.Request(url_data, urllib.urlencode(req_data_params), headers=headers)
response = urllib2.urlopen(req)
perate = opener.open(req)
thePage = response.read()
print thePage # 所需要的資料