
大資料(四)
阿新 • • 發佈:2019-01-09
MapReduce不擅長什麼
實時計算
像MySQL一樣,在毫秒級或者秒級內返回結果
流式計算
MapReduce的輸入資料集是靜態的,不能動態變化
MapReduce自身的設計特點決定了資料來源必須是靜態的
DAG計算
多個應用程式存在依賴關係,後一個應用程式的輸入為前一個的輸出
MapReduce程式設計模型
MapReduce將作業job的整個執行過程分為兩個階段:Map階段和Reduce階段
Map階段由一定數量的Map Task
MapReduce程式設計模型—內部邏輯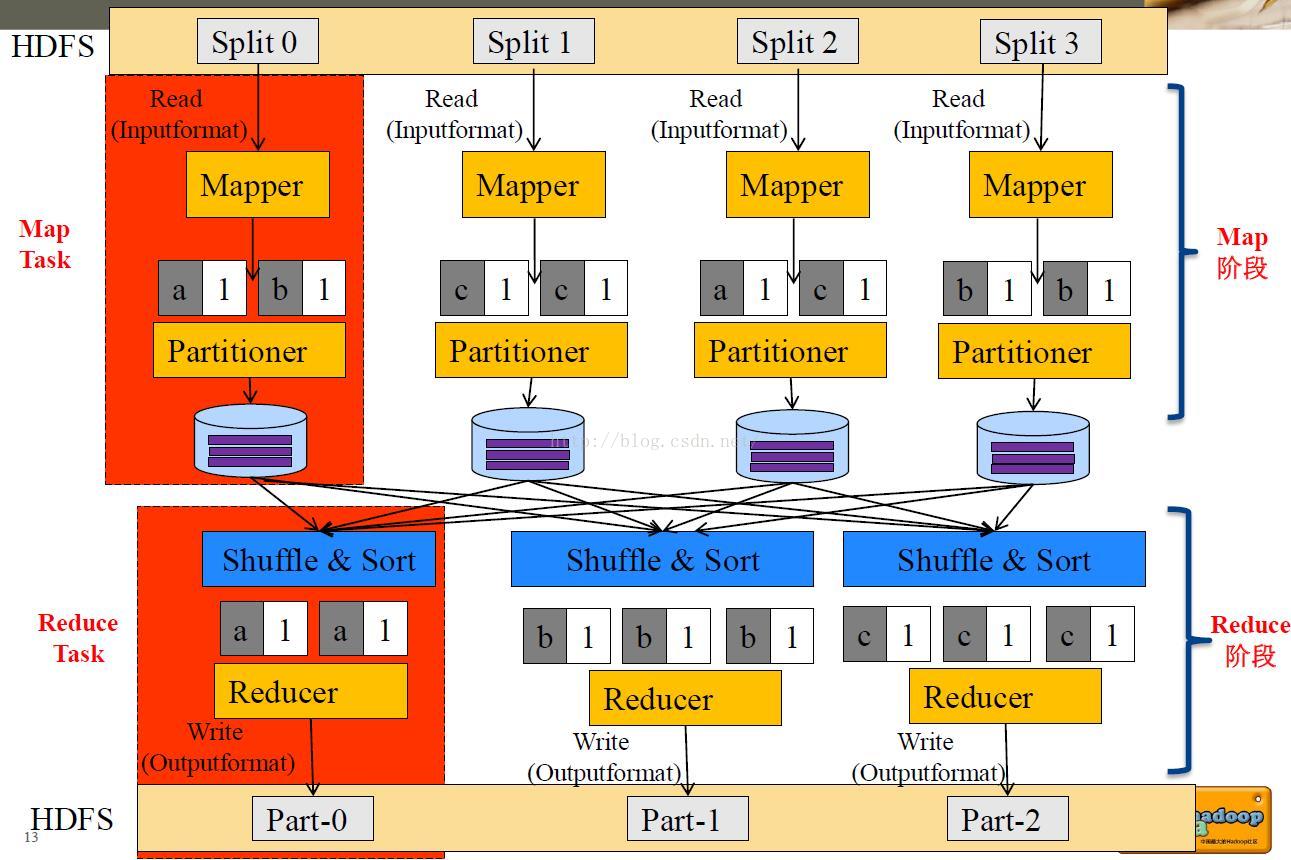

MapReduce 2.0架構
Client 與MapReduce 1.0的Client類似,使用者通過Client與YARN互動,提交MapReduce作業,查詢作業執行狀態,管理作業等。 MRAppMaster 功能類似於 1.0中的JobTracker,但不負責資源管理; 功能包括:任務劃分、資源申請並將之二次分配個Map Task和Reduce Task、任務狀態監控和容錯。 MapReduce 2.0容錯性 MRAppMaster容錯性 一旦執行失敗,由YARN的ResourceManager負責重新啟動,最多重啟次數可由使用者設定,預設是2次。一旦超過最高重啟次數,則作業執行失敗。 Map Task/Reduce Task Task週期性向MRAppMaster彙報心跳; 一旦Task掛掉,則MRAppMaster將為之重新申請資源,並執行之。最多重新執行次數可由使用者設定,預設4次。 資料本地性 什麼是資料本地性(data locality) 如果任務執行在它將處理的資料所在的節點,則稱該任務具有“資料本地性” 本地性可避免跨節點或機架資料傳輸,提高執行效率 資料本地性分類 同節點(node-local) 同機架(rack-local) 其他(off-switch) 推測執行機制 作業完成時間取決於最慢的任務完成時間 一個作業由若干個Map任務和Reduce任務構成 因硬體老化、軟體Bug等,某些任務可能執行非常慢 推測執行機制 發現拖後腿的任務,比如某個任務執行速度遠慢於任務平均速度 為拖後腿任務啟動一個備份任務,同時執行 誰先執行完,則採用誰的結果 不能啟用推測執行機制 任務間存在嚴重的負載傾斜 特殊任務,比如任務向資料庫中寫資料 常見MapReduce應用場景 簡單的資料統計,比如網站pv、uv統計 搜尋引擎建索引 (mapreduce產生的原因) 海量資料查詢 複雜資料分析演算法實現 聚類演算法 分類演算法 推薦演算法 圖演算法
MapReduce程式設計模型—內部邏輯
MapReduce 2.0架構
Client 與MapReduce 1.0的Client類似,使用者通過Client與YARN互動,提交MapReduce作業,查詢作業執行狀態,管理作業等。 MRAppMaster 功能類似於 1.0中的JobTracker,但不負責資源管理; 功能包括:任務劃分、資源申請並將之二次分配個Map Task和Reduce Task、任務狀態監控和容錯。 MapReduce 2.0容錯性 MRAppMaster容錯性 一旦執行失敗,由YARN的ResourceManager負責重新啟動,最多重啟次數可由使用者設定,預設是2次。一旦超過最高重啟次數,則作業執行失敗。 Map Task/Reduce Task Task週期性向MRAppMaster彙報心跳; 一旦Task掛掉,則MRAppMaster將為之重新申請資源,並執行之。最多重新執行次數可由使用者設定,預設4次。 資料本地性 什麼是資料本地性(data locality) 如果任務執行在它將處理的資料所在的節點,則稱該任務具有“資料本地性” 本地性可避免跨節點或機架資料傳輸,提高執行效率 資料本地性分類 同節點(node-local) 同機架(rack-local) 其他(off-switch) 推測執行機制 作業完成時間取決於最慢的任務完成時間 一個作業由若干個Map任務和Reduce任務構成 因硬體老化、軟體Bug等,某些任務可能執行非常慢 推測執行機制 發現拖後腿的任務,比如某個任務執行速度遠慢於任務平均速度 為拖後腿任務啟動一個備份任務,同時執行 誰先執行完,則採用誰的結果 不能啟用推測執行機制 任務間存在嚴重的負載傾斜 特殊任務,比如任務向資料庫中寫資料 常見MapReduce應用場景 簡單的資料統計,比如網站pv、uv統計 搜尋引擎建索引 (mapreduce產生的原因) 海量資料查詢 複雜資料分析演算法實現 聚類演算法 分類演算法 推薦演算法 圖演算法