
logistic迴歸演算法原理及python實現
1 logistic迴歸與sigmoid函式
考慮如下線性函式:
輸出
但是,單位階躍函式不連續,不利於求解權值,構建模型。於是sigmoid函式(對數機率函式,logistic function)出現了,他單調可微,並且形似階躍函式,其公式描述如下所示:
sigmoid曲線如下圖所示:
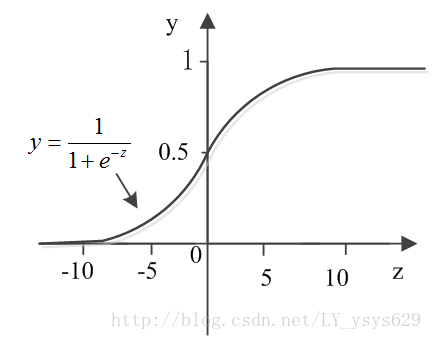
令
2 二項邏輯斯蒂迴歸模型與引數估計
由式(3)可得二項邏輯斯蒂迴歸模型如下所示:
其中,
學習模型的關鍵是對權值
極大似然函式的假設
一種學習方法的假設很重要,合理、科學的假設代表了學習方法的正確方向,在該假設條件下,得出的模型往往能夠達到預期效果。
設訓練樣本
相關推薦
logistic迴歸演算法原理及python實現
1 logistic迴歸與sigmoid函式 考慮如下線性函式: y=wwTxx+b(1) 輸出y為連續的實值,如何讓輸出成為二值來完成二分類任務?即y∈{0,1},最理想的是單位階躍函式即: y=⎧⎩⎨⎪⎪0,z<00.5,z=01,z>0
寫程式學ML:Logistic迴歸演算法原理及實現(三)
2.2 利用Logistic演算法預測病馬死亡率 由於採集資料是諸多原因,採集的資料有可能不完整。但有時候資料相當昂貴,扔掉和重新獲取都是不可取的,所以必須採用一些方法來解決這個問題。 處理資料中缺失值的做法: 1> 使用可用特徵的均值來填補缺失值; 2&g
寫程式學ML:Logistic迴歸演算法原理及實現(一)
[題外話]近期申請了一個微信公眾號:平凡程式人生。有興趣的朋友可以關注,那裡將會涉及更多更新機器學習、OpenCL+OpenCV以及影象處理方面的文章。 1、Logistic迴歸演算法的原理 假設現在有一些資料點,我們用一條直線對這些點進行擬合(該線稱為最佳擬合直線),這個
寫程式學ML:Logistic迴歸演算法原理及實現(二)
2、Logistic迴歸演算法的實現 2.1 Logistic演算法的實現 首先,我們實現梯度上升演算法。 Sigmoid函式的定義如下: #sigmoid函式的實現 def sigmoid(inX): return 1.0 / (1 + exp(-inX))
邏輯迴歸演算法推導及Python實現
寫在前面: 1、好多邏輯迴歸的演算法推導要麼直接省略,要麼寫的比較難以看懂,比如寫成矩陣求導,繁難難懂,本文進行推導,會鏈式求導法則應當就能看懂 2、本文參考若干文章,寫在附註處,如果參考未寫引用,還望提出 2、本文後續可能不定時更新,如有錯誤,歡迎提出 一、最大似
SVM演算法原理及Python實現
Svm(support Vector Mac)又稱為支援向量機,是一種二分類的模型。當然如果進行修改之後也是可以用於多類別問題的分類。支援向量機可以分為線性核非線性兩大類。其主要思想為找到空間中的一個更夠將所有資料樣本劃開的超平面,並且使得本本集中所有資料到這個超平面的距離最
決策樹之CART演算法原理及python實現
1 CART演算法 CART 是在給定輸入X條件下輸出隨機變數Y的條件概率分佈的學習方法。CART二分每個特徵(包括標籤特徵以及連續特徵),經過最優二分特徵及其最優二分特徵值的選擇、切分,二叉樹生成,剪枝來實現CART演算法。對於迴歸CART樹選擇誤差平方和準
bandit演算法原理及Python實現
選一個(0,1)之間較小的數epsilon 每次以概率epsilon(產生一個[0,1]之間的隨機數,比epsilon小)做一件事:所有臂中隨機選一個。否則,選擇截止當前,平均收益最大的那個臂。 是不是簡單粗暴?epsilon的值可以控制對Exploit和Explore的偏好程度。越接近0,越保守
【機器學習】Apriori演算法——原理及程式碼實現(Python版)
Apriopri演算法 Apriori演算法在資料探勘中應用較為廣泛,常用來挖掘屬性與結果之間的相關程度。對於這種尋找資料內部關聯關係的做法,我們稱之為:關聯分析或者關聯規則學習。而Apriori演算法就是其中非常著名的演算法之一。關聯分析,主要是通過演算法在大規模資料集中尋找頻繁項集和關聯規則。
層次聚類演算法的原理及python實現
層次聚類(Hierarchical Clustering)是一種聚類演算法,通過計算不同類別資料點間的相似度來建立一棵有層次的巢狀聚類樹。在聚類樹中,不同類別的原始資料點是樹的最低層,樹的頂層是一個聚類的根節點。 聚類樹的建立方法:自下而上的合併,自上而下的分裂。(這裡介紹第一種) 1.2 層次聚類的合
經典排序演算法,氣泡排序,選擇排序,直接插入排序,希爾排序,快速排序,歸併排序,二分查詢。原理及python實現。
1.氣泡排序 氣泡排序 1.比較相鄰的元素,如果第一個比第二個大(升序),就交換他們兩個 2.對每一對相鄰的元素做同樣的工作,從開始到結尾的最後一對 這步做完後,最後的元素會是最大的數 3.針對所有的元素重複以上的步驟,除了最
機器學習——隨機森林演算法randomForest——原理及python實現
參考: http://blog.csdn.net/nieson2012/article/details/51279332 http://www.cnblogs.com/wentingtu/archive/2011/12/22/2297405.html http://www.
快速匹配字串演算法BK樹 原理及python實現
BK樹或者稱為Burkhard-Keller樹,是一種基於樹的資料結構。用於快速查詢近似字串匹配,比方說拼寫糾錯,或模糊查詢,當搜尋”aeek”時能返回與其最相似的字串”seek”和”peek”。 在構建BK樹之前,我們需要定義一種用於比較字串相似度的度量方法。通常都是採用
logistic regression演算法原理及實現
邏輯迴歸所要學習的函式模型為y(x),由x->y,x為樣本,y為目標類別,即總體思想是任意給出一個樣本輸入,模型均能將其正確分類。實際運用中比如有郵箱郵件分類,對於任意一封郵件,經過模型後可將其判別為是否是垃圾郵件。 假如我們知道某類資料的條件概率分佈函
常見的查找算法的原理及python實現
put arch img 字典 python實現 需要 技術 () one 順序查找 二分查找 練習 一、順序查找 data=[1,3,4,5,6] value=1 def linear_search(data,value): flag=False
短時傅裏葉變換(Short Time Fourier Transform)原理及 Python 實現
src 參考 函數 ade block return 技術 數學公式 def 原理 短時傅裏葉變換(Short Time Fourier Transform, STFT) 是一個用於語音信號處理的通用工具.它定義了一個非常有用的時間和頻率分布類, 其指定了任意信號隨時間
線程池原理及python實現
source 實例 以及 代碼 let range python實現 queue 上界 https://www.cnblogs.com/goodhacker/p/3359985.html 為什麽需要線程池 目前的大多數網絡服務器,包括Web服務器、Email服務器以
FFM演算法解析及Python實現
1. 什麼是FFM? 通過引入field的概念,FFM把相同性質的特徵歸於同一個field,相當於把FM中已經細分的feature再次進行拆分從而進行特徵組合的二分類模型。 2. 為什麼需要FFM? 在傳統的線性模型中,每個特徵都是獨立的,如果需要考慮特徵與特徵之間的相互作用,可能需要人工對特徵進行交叉
【ML_Algorithm 1】線性迴歸——演算法推導及程式碼實現
::::::::線性迴歸:::::::: 第一式 第二式 從式一到式二,需要新增一個
DeepFM演算法解析及Python實現 FFM演算法解析及Python實現 FM演算法解析及Python實現 詞嵌入的那些事兒(一)
1. DeepFM演算法的提出 由於DeepFM演算法有效的結合了因子分解機與神經網路在特徵學習中的優點:同時提取到低階組合特徵與高階組合特徵,所以越來越被廣泛使用。 在DeepFM中,FM演算法負責對一階特徵以及由一階特徵兩兩組合而成的二階特徵進行特徵的提取;DNN演算法負責對由輸入的一階特徵進行全連線