
logistic regression演算法原理及實現
邏輯迴歸所要學習的函式模型為y(x),由x->y,x為樣本,y為目標類別,即總體思想是任意給出一個樣本輸入,模型均能將其正確分類。實際運用中比如有郵箱郵件分類,對於任意一封郵件,經過模型後可將其判別為是否是垃圾郵件。
假如我們知道某類資料的條件概率分佈函式P(y|x),則不管輸入x是什麼值,均能計算出輸出y為特定值的概率,根據概率的大小,也就可以將其正確分類。因此我們需要做的就是找到一個儘可能近似P(y|x)的分佈,使得對輸入的分類準確度接近真實分佈的準確度。
下面考慮二分類問題。
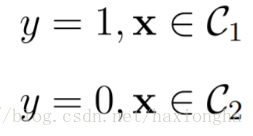
如果x屬於資料C1類,則其經過模型後輸出y為1的概率比y為0的概率要大,因此可將其歸為y=1類,如果x屬於資料C2類,則其經過模型後輸出y為0的概率比y為1的概率要大則將其歸為y=0類。即目標值只有0和1兩,也即是二分類。
考慮下圖
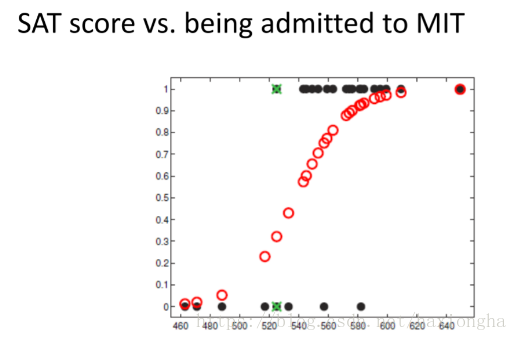
橫座標為學生分數,縱座標為是否被錄取,由圖中黑點可知,分數低的大部分沒有被錄取,分數高的大部分被錄取,其中個別資料為特殊情況,不予考慮。圖中紅色點就是我們的模型,其可根據不同的輸入輸出相應的值。
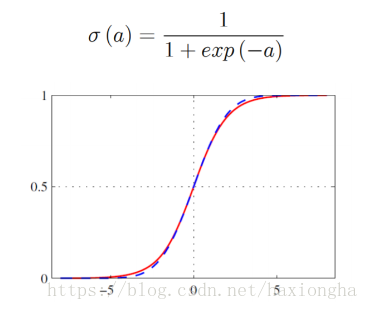
根據該曲線形狀和輸出範圍,可以將sigmoid函式作為函式模型,函式表示式及圖形如下:
因此
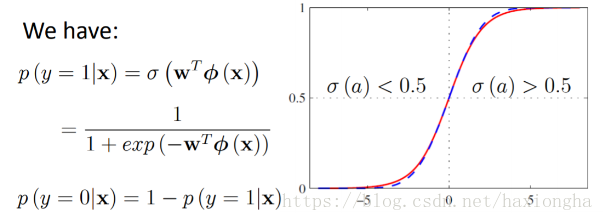
我們的目標值只有0和1,而該模型輸出為0到1之間的值,為實現分類問題,可做如下處理:
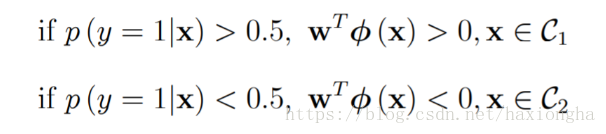
以上兩條公式的物理解釋為:因為概率的輸出範圍為[0,1]之間所有可能的值,而我們實際的分類問題只有兩類0和1,那麼現在就需要考慮實際樣本輸出的概率值為多大歸為0類或者1類呢?最好的方式就是取中間值0.5作為分界點,輸出目標值為1的概率大於0.5(說明其目標值接近1的概率更大)的歸為1類,小於0.5(說明其目標值接近0的概率更大)的歸為0類。
注意到函式模型中只有w為變數,那麼我們接下來需要求出w使得我們的模型
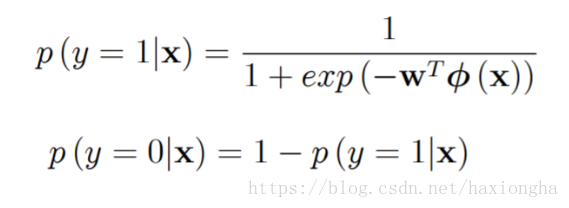
儘可能接近真實資料的分佈,但是我們並不知道真實資料的分佈,只知道由真實分佈產生的樣本資料,那麼怎麼根據樣本資料使得求出的w使得模型儘可能接近真實分佈呢?由此可以聯想到最大似然估計,為什麼最大似然估計就可以達到以上目的呢?似然函式表示式如下:
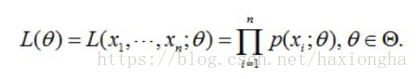
注意到,似然函式為每個樣本的概率乘積,其中θ為似然函式變數,最大似然顧名思義就是求θ,使得似然函式L(θ)最大,換句話說,如果在特殊情況下,存在這麼一個θ值,其同時使得每個樣本的概率都為最大,那麼自然似然函式也就是最大,則該θ就是我們所求的目標θ。但實際情況是很少存在這麼一個θ值,使得所有樣本概率為最大值同時成立,所以現在要退而求其次,找到這麼一個θ值,使得總體概率為最大值,其中有部分樣本概率可能為最大,也可能為最小或者介於兩者之間,但他們總體的概率是最大的。
那麼為什麼最大似然估計可以估計真實分佈模型呢?我的理解是這樣的,從真實分佈中採集一組樣本,首先採集到的這組樣本本身就隱含了某些性質,比如在真實分佈中,這些樣本發生的概率就比那些沒有發生(即沒有采集到)的樣本概率一般更大,舉個形象的例子,一個袋子裡面有一個蘋果和49個橘子,閉上眼睛從袋子中隨便摸一個,毫無疑問,摸到橘子的概率會更大,如果將橘子當作一個樣本,摸到就是樣本發生,沒摸到就是樣本沒發生,那麼橘子這個樣本發生的概率肯定大於蘋果。換句話說,橘子這個樣本發生的可能性更大,所以發生了的樣本一般比沒發生的樣本概率更大。有了這個理解,接下來做更極端一點的假設,假設採集到的樣本就是真實分佈的所有樣本容量(因為沒采集到的概率很小,就忽略他們的存在),並且個數多於樣本種類,那麼必然會有樣本被重複採集到,毫無疑問,被重複採集到的樣本次數多的一般比那些採集次數少的更容易發生,即發生概率更大。
那麼由這些採集到的樣本就可以根據其頻率次數與總的樣本數比值確定相應樣本的概率,這樣就可以確定一個分佈(又稱之為經驗分佈),實際問題中我們就是將這個分佈近似為真實資料發分佈。 現在總結一下這裡就是 P(採集次數多)>P(採集次數少)>P(沒法生)。
現在回到我們邏輯迴歸問題,已知採集到的樣本比沒采集到的樣本發生概率更大,甚至可以近似真實資料分佈,那麼對於我們含有參變數w的數學模型,只要求得w使得所有樣本概率乘積最大,那麼這時的w就會使得數學模型最接近真實資料分佈。
考慮條件資料分佈似然函式
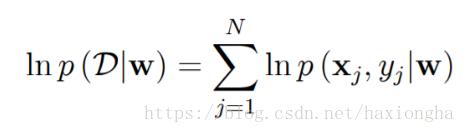
等式右邊w為資料分佈引數,大D為我們建立的資料分佈模型,條件概率表示在已知w的情況下,資料分佈模型也就相應的確定,現在就要找出這樣一個w使得條件似然函式最大,也就是大D最接近我們真實的資料分佈,等式右邊為所有樣本含參概率的積。根據概率鏈式法則,可將右邊做如下變形:
兩邊同時取對數可得:
所以資料分佈似然函式可化為如下等式:
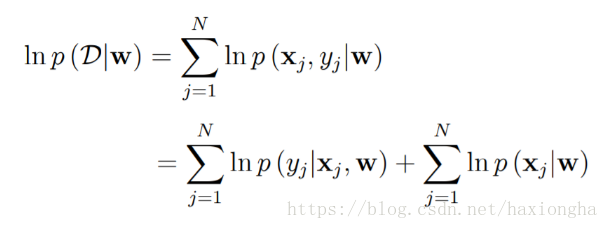
其中等式右邊第二項x和w之間並沒有聯絡,w的取值不會影響x,所以可將其看作一個常數,所以上式又可化為求如下最大似然值:
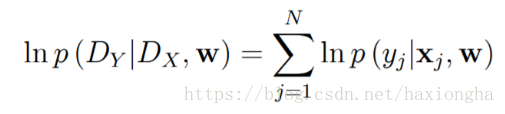
我們又已知:
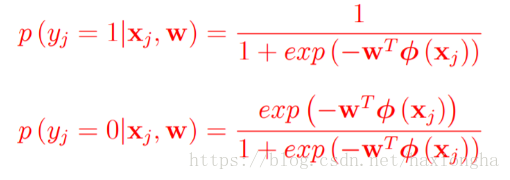
令
則有