
handoop job工作執行的機制與原理詳解
宣告:本博文的圖片來自於董西城《hadoop技術內幕》;HDFS原理以及MapReduce的簡單原理請移步我之前的部落格,也歡迎關注我的大資料專欄,這是我入門學習大資料的完整歷程,歡迎提出建議以及知識交流。
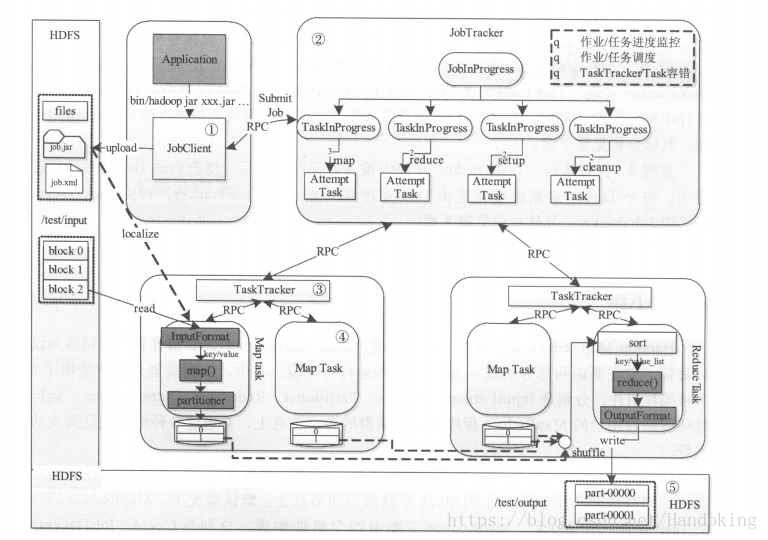
上圖是hadoop MapReduce的作業生命週期圖。
或者看一個更簡單的圖,下圖是MapReduce的架構圖
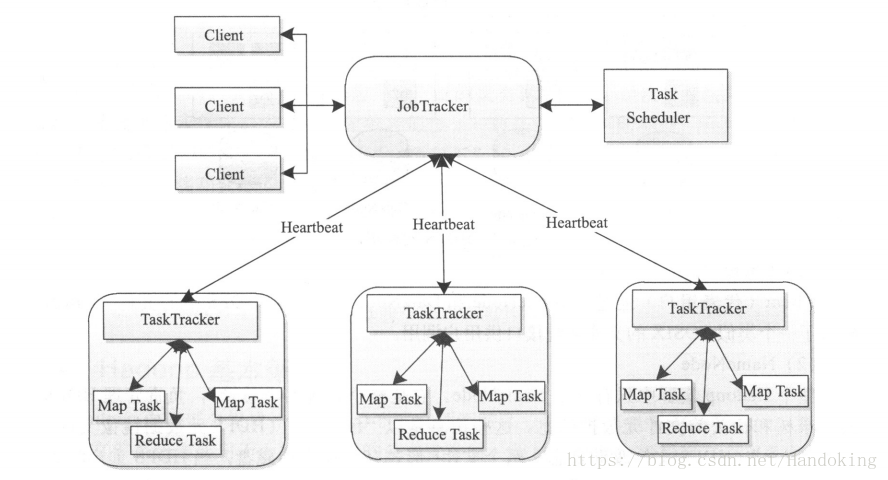
大致分為幾個步驟:
第一個階段:作業提交與初始化
使用者通過client提交MapReduce作業給JobTracker,這個client可以理解實現一般的客戶端的功能就是用來讓使用者和內部架構進行互動,不僅可以提交作業,還有可以client提供的一些藉口進行查詢作業的執行狀況。其實使用者並不是直接將作業提交給JobTracker。在提交給JobTracker前,使用者提交作業壓縮包jar,hadoop中Jobclient類根據內部的jar命令將作業通過Runjar中的main函式將壓縮包解壓,並配置環境,將其中的引數傳遞給MapReduce程式。除準備環境外,作業提交過程還需要獲取作業ID,建立HDFS目錄,上傳作業檔案到HDFS,生成split檔案等。(使用者編寫的MapReduce程式中已經配置了,Mapper類,Reducer類以及Reduce Task個數等)。經過以上步驟才將作業提交給JobTracker。第一張圖中已經寫出jobclient是通過RPC來通知JobTracker的。hadoop RPC框架—-remote procedure call遠端過程呼叫是一種分散式網路通訊協議,它實現了一臺計算機上的程式可以呼叫另一臺計算機上的子程式,同時將網路的細節部分封裝隱藏起來,使用者不需要再進行程式設計開發。(隨後會總結一下RPC的原理)。JobTracker就像名字所寫的那樣,就是負責資源監控和作業排程的。舉個例子,就是哪個節點資源空閒,資源使用情況,哪個作業健康有問題更換節點,作業的狀態和進度等,都歸它管,作業排程是由hadoop內部的排程器來配合完成的。JobTracker收到作業後,會對作業進行初始化,根據輸入資料的量和作業的配置引數分解若干個Map Task 和Reduce Task。但事實上JobTracker收到作業也沒有立即初始化,這是為了更好的利用資源以及更合適的分配任務,初始化是排程器TaskScheduler完成的,初始化後的作業才可以被排程。在初始化之前,JobTracker要盡職的各項引數是否符合,併為作業建立JobInProgress來完成監管任務。
第二階段 任務排程與監控
第一階段也提到了JobTracker的任務的排程與監控作用,具體實現過程是這樣的:如上圖展示的那樣,TaskTracker通過heartbeat週期性的向JobTracker彙報本節點的資源使用情況。這裡的heartbeat涉及的通訊模式叫做心跳接收和應答,它實際仍然是一個RPC函式,TaskTracker通過呼叫此函式來彙報各節點的資源利用情況以及任務的狀態。JobTracker與TaskTracker之間採用了pull模式,就是說JobTracker從來不主動釋出命令,而是通過TaskTracker的心跳應答來分配任務的。因此心跳的作用是向JobTracker證明TaskTracker還活著,週期性讓JobTracker獲取資訊,領取TaskTracker的任務。另一方面,心跳應答就是下達任務和下達彙報下次心跳的時間間隔。下達給TaskTracker的命令有重新初始化,執行新任務,殺死作業,提交任務。從下達的命令可以看出TaskTracker是有不錯的容錯機制的,主要包括超時機制,建立灰名單和黑名單。超時機制某個TaskTracker沒有在一定時間內彙報心跳(時間可以自己設定)就會因為超時被移除,但移除並不是簡單的刪除還有一個回收機制,這裡不仔細說了。灰名單就是被加入的TaskTracker還有機會被放出繼續執行任務,而進入黑名單則沒有機會復活。
第三階段:任務環境準備
這裡的環境準備是更巨集觀的環境,與第一階段的初始化前的環境準備不是一個層次。這裡由TaskTracker來實現,準備的是Java虛擬機器JVM,每個Task都有單獨的一個JVM,避免不同的JVM在執行時互相影響,同時也實現了資源隔離防止TaskTracker濫用資源。至於TaskTracker的執行就是第二階段描述的映象。
第四階段:任務執行
這個階段就是上篇博文中簡單描述的MapReduce的過程,當然這也裡面穿插著了TaskTracker不斷向JobTracker彙報情況的過程,直到所有的任務完成,將結果儲存在HDFS中。