
Kafka 設計與原理詳解
一、Kafka簡介
本文綜合了我之前寫的kafka相關文章,可作為一個全面瞭解學習kafka的培訓學習資料。
轉載請註明出處 : 本文連結
1.1 背景歷史
當今社會各種應用系統諸如商業、社交、搜尋、瀏覽等像資訊工廠一樣不斷的生產出各種資訊,在大資料時代,我們面臨如下幾個挑戰:
- 如何收集這些巨大的資訊
- 如何分析它
- 如何及時做到如上兩點
以上幾個挑戰形成了一個業務需求模型,即生產者生產(produce)各種資訊,消費者消費(consume)(處理分析)這些資訊,而在生產者與消費者之間,需要一個溝通兩者的橋樑-訊息系統。從一個微觀層面來說,這種需求也可理解為不同的系統之間如何傳遞訊息。
1.2 Kafka誕生
Kafka由 linked-in 開源
kafka-即是解決上述這類問題的一個框架,它實現了生產者和消費者之間的無縫連線。
kafka-高產出的分散式訊息系統(A high-throughput distributed messaging system)
1.3 Kafka現在
Apache kafka 是一個分散式的基於push-subscribe的訊息系統,它具備快速、可擴充套件、可持久化的特點。它現在是Apache旗下的一個開源系統,作為hadoop生態系統的一部分,被各種商業公司廣泛應用。它的最大的特性就是可以實時的處理大量資料以滿足各種需求場景:比如基於hadoop的批處理系統、低延遲的實時系統、storm/spark流式處理引擎。
二、Kafka技術概覽
2.1 Kafka的特性
- 高吞吐量、低延遲:kafka每秒可以處理幾十萬條訊息,它的延遲最低只有幾毫秒
- 可擴充套件性:kafka叢集支援熱擴充套件
- 永續性、可靠性:訊息被持久化到本地磁碟,並且支援資料備份防止資料丟失
- 容錯性:允許叢集中節點失敗(若副本數量為n,則允許n-1個節點失敗)
- 高併發:支援數千個客戶端同時讀寫
2.2 Kafka一些重要設計思想
下面介紹先大體介紹一下Kafka的主要設計思想,可以讓相關人員在短時間內瞭解到kafka相關特性,如果想深入研究,後面會對其中每一個特性都做詳細介紹。
- Consumergroup:各個consumer可以組成一個組,每個訊息只能被組中的一個consumer消費,如果一個訊息可以被多個consumer消費的話,那麼這些consumer必須在不同的組。
- 訊息狀態:在Kafka中,訊息的狀態被儲存在consumer中,broker不會關心哪個訊息被消費了被誰消費了,只記錄一個offset值(指向partition中下一個要被消費的訊息位置),這就意味著如果consumer處理不好的話,broker上的一個訊息可能會被消費多次。
- 訊息持久化:Kafka中會把訊息持久化到本地檔案系統中,並且保持極高的效率。
- 訊息有效期:Kafka會長久保留其中的訊息,以便consumer可以多次消費,當然其中很多細節是可配置的。
- 批量傳送:Kafka支援以訊息集合為單位進行批量傳送,以提高push效率。
- push-and-pull : Kafka中的Producer和consumer採用的是push-and-pull模式,即Producer只管向broker push訊息,consumer只管從broker pull訊息,兩者對訊息的生產和消費是非同步的。
- Kafka叢集中broker之間的關係:不是主從關係,各個broker在叢集中地位一樣,我們可以隨意的增加或刪除任何一個broker節點。
- 負載均衡方面: Kafka提供了一個 metadata API來管理broker之間的負載(對Kafka0.8.x而言,對於0.7.x主要靠zookeeper來實現負載均衡)。
- 同步非同步:Producer採用非同步push方式,極大提高Kafka系統的吞吐率(可以通過引數控制是採用同步還是非同步方式)。
- 分割槽機制partition:Kafka的broker端支援訊息分割槽,Producer可以決定把訊息發到哪個分割槽,在一個分割槽中訊息的順序就是Producer傳送訊息的順序,一個主題中可以有多個分割槽,具體分割槽的數量是可配置的。分割槽的意義很重大,後面的內容會逐漸體現。
- 離線資料裝載:Kafka由於對可拓展的資料持久化的支援,它也非常適合向Hadoop或者資料倉庫中進行資料裝載。
- 外掛支援:現在不少活躍的社群已經開發出不少外掛來拓展Kafka的功能,如用來配合Storm、Hadoop、flume相關的外掛。
2.3 kafka 應用場景
- 日誌收集:一個公司可以用Kafka可以收集各種服務的log,通過kafka以統一介面服務的方式開放給各種consumer,例如hadoop、Hbase、Solr等。
- 訊息系統:解耦和生產者和消費者、快取訊息等。
- 使用者活動跟蹤:Kafka經常被用來記錄web使用者或者app使用者的各種活動,如瀏覽網頁、搜尋、點選等活動,這些活動資訊被各個伺服器釋出到kafka的topic中,然後訂閱者通過訂閱這些topic來做實時的監控分析,或者裝載到hadoop、資料倉庫中做離線分析和挖掘。
- 運營指標:Kafka也經常用來記錄運營監控資料。包括收集各種分散式應用的資料,生產各種操作的集中反饋,比如報警和報告。
- 流式處理:比如spark streaming和storm
- 事件源
2.4 Kafka架構元件
Kafka中釋出訂閱的物件是topic。我們可以為每類資料建立一個topic,把向topic釋出訊息的客戶端稱作producer,從topic訂閱訊息的客戶端稱作consumer。Producers和consumers可以同時從多個topic讀寫資料。一個kafka叢集由一個或多個broker伺服器組成,它負責持久化和備份具體的kafka訊息。
- topic:訊息存放的目錄即主題
- Producer:生產訊息到topic的一方
- Consumer:訂閱topic消費訊息的一方
- Broker:Kafka的服務例項就是一個broker

2.5 Kafka Topic&Partition
訊息傳送時都被髮送到一個topic,其本質就是一個目錄,而topic由是由一些Partition Logs(分割槽日誌)組成,其組織結構如下圖所示:

我們可以看到,每個Partition中的訊息都是有序的,生產的訊息被不斷追加到Partition log上,其中的每一個訊息都被賦予了一個唯一的offset值。
Kafka叢集會儲存所有的訊息,不管訊息有沒有被消費;我們可以設定訊息的過期時間,只有過期的資料才會被自動清除以釋放磁碟空間。比如我們設定訊息過期時間為2天,那麼這2天內的所有訊息都會被儲存到叢集中,資料只有超過了兩天才會被清除。
Kafka需要維持的元資料只有一個–消費訊息在Partition中的offset值,Consumer每消費一個訊息,offset就會加1。其實訊息的狀態完全是由Consumer控制的,Consumer可以跟蹤和重設這個offset值,這樣的話Consumer就可以讀取任意位置的訊息。
把訊息日誌以Partition的形式存放有多重考慮,第一,方便在叢集中擴充套件,每個Partition可以通過調整以適應它所在的機器,而一個topic又可以有多個Partition組成,因此整個叢集就可以適應任意大小的資料了;第二就是可以提高併發,因為可以以Partition為單位讀寫了。
三、Kafka 核心元件
3.1 Replications、Partitions 和Leaders
通過上面介紹的我們可以知道,kafka中的資料是持久化的並且能夠容錯的。Kafka允許使用者為每個topic設定副本數量,副本數量決定了有幾個broker來存放寫入的資料。如果你的副本數量設定為3,那麼一份資料就會被存放在3臺不同的機器上,那麼就允許有2個機器失敗。一般推薦副本數量至少為2,這樣就可以保證增減、重啟機器時不會影響到資料消費。如果對資料持久化有更高的要求,可以把副本數量設定為3或者更多。
Kafka中的topic是以partition的形式存放的,每一個topic都可以設定它的partition數量,Partition的數量決定了組成topic的log的數量。Producer在生產資料時,會按照一定規則(這個規則是可以自定義的)把訊息釋出到topic的各個partition中。上面將的副本都是以partition為單位的,不過只有一個partition的副本會被選舉成leader作為讀寫用。
關於如何設定partition值需要考慮的因素。一個partition只能被一個消費者消費(一個消費者可以同時消費多個partition),因此,如果設定的partition的數量小於consumer的數量,就會有消費者消費不到資料。所以,推薦partition的數量一定要大於同時執行的consumer的數量。另外一方面,建議partition的數量大於叢集broker的數量,這樣leader partition就可以均勻的分佈在各個broker中,最終使得叢集負載均衡。在Cloudera,每個topic都有上百個partition。需要注意的是,kafka需要為每個partition分配一些記憶體來快取訊息資料,如果partition數量越大,就要為kafka分配更大的heap space。
3.2 Producers
Producers直接傳送訊息到broker上的leader partition,不需要經過任何中介一系列的路由轉發。為了實現這個特性,kafka叢集中的每個broker都可以響應producer的請求,並返回topic的一些元資訊,這些元資訊包括哪些機器是存活的,topic的leader partition都在哪,現階段哪些leader partition是可以直接被訪問的。
Producer客戶端自己控制著訊息被推送到哪些partition。實現的方式可以是隨機分配、實現一類隨機負載均衡演算法,或者指定一些分割槽演算法。Kafka提供了介面供使用者實現自定義的分割槽,使用者可以為每個訊息指定一個partitionKey,通過這個key來實現一些hash分割槽演算法。比如,把userid作為partitionkey的話,相同userid的訊息將會被推送到同一個分割槽。
以Batch的方式推送資料可以極大的提高處理效率,kafka Producer 可以將訊息在記憶體中累計到一定數量後作為一個batch傳送請求。Batch的數量大小可以通過Producer的引數控制,引數值可以設定為累計的訊息的數量(如500條)、累計的時間間隔(如100ms)或者累計的資料大小(64KB)。通過增加batch的大小,可以減少網路請求和磁碟IO的次數,當然具體引數設定需要在效率和時效性方面做一個權衡。
Producers可以非同步的並行的向kafka傳送訊息,但是通常producer在傳送完訊息之後會得到一個future響應,返回的是offset值或者傳送過程中遇到的錯誤。這其中有個非常重要的引數“acks”,這個引數決定了producer要求leader partition 收到確認的副本個數,如果acks設定數量為0,表示producer不會等待broker的響應,所以,producer無法知道訊息是否傳送成功,這樣有可能會導致資料丟失,但同時,acks值為0會得到最大的系統吞吐量。
若acks設定為1,表示producer會在leader partition收到訊息時得到broker的一個確認,這樣會有更好的可靠性,因為客戶端會等待直到broker確認收到訊息。若設定為-1,producer會在所有備份的partition收到訊息時得到broker的確認,這個設定可以得到最高的可靠性保證。
Kafka 訊息有一個定長的header和變長的位元組陣列組成。因為kafka訊息支援位元組陣列,也就使得kafka可以支援任何使用者自定義的序列號格式或者其它已有的格式如Apache Avro、protobuf等。Kafka沒有限定單個訊息的大小,但我們推薦訊息大小不要超過1MB,通常一般訊息大小都在1~10kB之前。
3.3 Consumers
Kafka提供了兩套consumer api,分為high-level api和sample-api。Sample-api 是一個底層的API,它維持了一個和單一broker的連線,並且這個API是完全無狀態的,每次請求都需要指定offset值,因此,這套API也是最靈活的。
在kafka中,當前讀到訊息的offset值是由consumer來維護的,因此,consumer可以自己決定如何讀取kafka中的資料。比如,consumer可以通過重設offset值來重新消費已消費過的資料。不管有沒有被消費,kafka會儲存資料一段時間,這個時間週期是可配置的,只有到了過期時間,kafka才會刪除這些資料。
High-level API封裝了對叢集中一系列broker的訪問,可以透明的消費一個topic。它自己維持了已消費訊息的狀態,即每次消費的都是下一個訊息。
High-level API還支援以組的形式消費topic,如果consumers有同一個組名,那麼kafka就相當於一個佇列訊息服務,而各個consumer均衡的消費相應partition中的資料。若consumers有不同的組名,那麼此時kafka就相當與一個廣播服務,會把topic中的所有訊息廣播到每個consumer。

四、Kafka核心特性
4.1 壓縮
我們上面已經知道了Kafka支援以集合(batch)為單位傳送訊息,在此基礎上,Kafka還支援對訊息集合進行壓縮,Producer端可以通過GZIP或Snappy格式對訊息集合進行壓縮。Producer端進行壓縮之後,在Consumer端需進行解壓。壓縮的好處就是減少傳輸的資料量,減輕對網路傳輸的壓力,在對大資料處理上,瓶頸往往體現在網路上而不是CPU(壓縮和解壓會耗掉部分CPU資源)。
那麼如何區分訊息是壓縮的還是未壓縮的呢,Kafka在訊息頭部添加了一個描述壓縮屬性位元組,這個位元組的後兩位表示訊息的壓縮採用的編碼,如果後兩位為0,則表示訊息未被壓縮。
4.2訊息可靠性
在訊息系統中,保證訊息在生產和消費過程中的可靠性是十分重要的,在實際訊息傳遞過程中,可能會出現如下三中情況:
- 一個訊息傳送失敗
- 一個訊息被髮送多次
- 最理想的情況:exactly-once ,一個訊息傳送成功且僅傳送了一次
有許多系統聲稱它們實現了exactly-once,但是它們其實忽略了生產者或消費者在生產和消費過程中有可能失敗的情況。比如雖然一個Producer成功傳送一個訊息,但是訊息在傳送途中丟失,或者成功傳送到broker,也被consumer成功取走,但是這個consumer在處理取過來的訊息時失敗了。
從Producer端看:Kafka是這麼處理的,當一個訊息被髮送後,Producer會等待broker成功接收到訊息的反饋(可通過引數控制等待時間),如果訊息在途中丟失或是其中一個broker掛掉,Producer會重新發送(我們知道Kafka有備份機制,可以通過引數控制是否等待所有備份節點都收到訊息)。
從Consumer端看:前面講到過partition,broker端記錄了partition中的一個offset值,這個值指向Consumer下一個即將消費message。當Consumer收到了訊息,但卻在處理過程中掛掉,此時Consumer可以通過這個offset值重新找到上一個訊息再進行處理。Consumer還有許可權控制這個offset值,對持久化到broker端的訊息做任意處理。
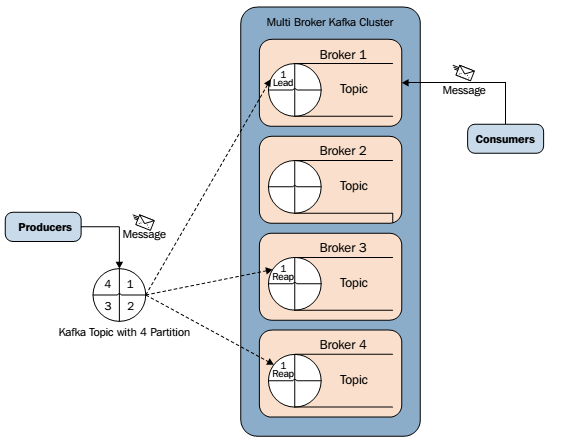
4.3 備份機制
備份機制是Kafka0.8版本的新特性,備份機制的出現大大提高了Kafka叢集的可靠性、穩定性。有了備份機制後,Kafka允許叢集中的節點掛掉後而不影響整個叢集工作。一個備份數量為n的叢集允許n-1個節點失敗。在所有備份節點中,有一個節點作為lead節點,這個節點儲存了其它備份節點列表,並維持各個備份間的狀體同步。下面這幅圖解釋了Kafka的備份機制:
4.4 Kafka高效性相關設計
4.4.1 訊息的持久化
Kafka高度依賴檔案系統來儲存和快取訊息,一般的人認為磁碟是緩慢的,這導致人們對持久化結構具有競爭性持懷疑態度。其實,磁碟遠比你想象的要快或者慢,這決定於我們如何使用磁碟。
一個和磁碟效能有關的關鍵事實是:磁碟驅動器的吞吐量跟尋到延遲是相背離的,也就是所,線性寫的速度遠遠大於隨機寫。比如:在一個6 7200rpm SATA RAID-5 的磁碟陣列上線性寫的速度大概是600M/秒,但是隨機寫的速度只有100K/秒,兩者相差將近6000倍。線性讀寫在大多數應用場景下是可以預測的,因此,作業系統利用read-ahead和write-behind技術來從大的資料塊中預取資料,或者將多個邏輯上的寫操作組合成一個大寫物理寫操作中。更多的討論可以在ACMQueueArtical中找到,他們發現,對磁碟的線性讀在有些情況下可以比記憶體的隨機訪問要快一些。
為了補償這個效能上的分歧,現代作業系統都會把空閒的記憶體用作磁碟快取,儘管在記憶體回收的時候會有一點效能上的代價。所有的磁碟讀寫操作會在這個統一的快取上進行。
此外,如果我們是在JVM的基礎上構建的,熟悉java記憶體應用管理的人應該清楚以下兩件事情:
- 一個物件的記憶體消耗是非常高的,經常是所存資料的兩倍或者更多。
- 隨著堆內資料的增多,Java的垃圾回收會變得非常昂貴。
基於這些事實,利用檔案系統並且依靠頁快取比維護一個記憶體快取或者其他結構要好——我們至少要使得可用的快取加倍,通過自動訪問可用記憶體,並且通過儲存更緊湊的位元組結構而不是一個物件,這將有可能再次加倍。這麼做的結果就是在一臺32GB的機器上,如果不考慮GC懲罰,將最多有28-30GB的快取。此外,這些快取將會一直存在即使服務重啟,然而程序內快取需要在記憶體中重構(10GB快取需要花費10分鐘)或者它需要一個完全冷快取啟動(非常差的初始化效能)。它同時也簡化了程式碼,因為現在所有的維護快取和檔案系統之間內聚的邏輯都在作業系統內部了,這使得這樣做比one-off in-process attempts更加高效與準確。如果你的磁碟應用更加傾向於順序讀取,那麼read-ahead在每次磁碟讀取中實際上獲取到這人快取中的有用資料。
以上這些建議了一個簡單的設計:不同於維護儘可能多的記憶體快取並且在需要的時候重新整理到檔案系統中,我們換一種思路。所有的資料不需要呼叫重新整理程式,而是立刻將它寫到一個持久化的日誌中。事實上,這僅僅意味著,資料將被傳輸到核心頁快取中並稍後被重新整理。我們可以增加一個配置項以讓系統的使用者來控制資料在什麼時候被重新整理到物理硬碟上。
4.4.2 常數時間效能保證
訊息系統中持久化資料結構的設計通常是維護者一個和消費佇列有關的B樹或者其它能夠隨機存取結構的元資料資訊。B樹是一個很好的結構,可以用在事務型與非事務型的語義中。但是它需要一個很高的花費,儘管B樹的操作需要O(logN)。通常情況下,這被認為與常數時間等價,但這對磁碟操作來說是不對的。磁碟尋道一次需要10ms,並且一次只能尋一個,因此並行化是受限的。
直覺上來講,一個持久化的佇列可以構建在對一個檔案的讀和追加上,就像一般情況下的日誌解決方案。儘管和B樹相比,這種結構不能支援豐富的語義,但是它有一個優點,所有的操作都是常數時間,並且讀寫之間不會相互阻塞。這種設計具有極大的效能優勢:最終系統性能和資料大小完全無關,伺服器可以充分利用廉價的硬碟來提供高效的訊息服務。
事實上還有一點,磁碟空間的無限增大而不影響效能這點,意味著我們可以提供一般訊息系統無法提供的特性。比如說,訊息被消費後不是立馬被刪除,我們可以將這些訊息保留一段相對比較長的時間(比如一個星期)。
4.4.3 進一步提高效率
我們已經為效率做了非常多的努力。但是有一種非常主要的應用場景是:處理Web活動資料,它的特點是資料量非常大,每一次的網頁瀏覽都會產生大量的寫操作。更進一步,我們假設每一個被髮布的訊息都會被至少一個consumer消費,因此我們更要怒路讓消費變得更廉價。
通過上面的介紹,我們已經解決了磁碟方面的效率問題,除此之外,在此類系統中還有兩類比較低效的場景:
- 太多小的I/O操作
- 過多的位元組拷貝
為了減少大量小I/O操作的問題,kafka的協議是圍繞訊息集合構建的。Producer一次網路請求可以傳送一個訊息集合,而不是每一次只發一條訊息。在server端是以訊息塊的形式追加訊息到log中的,consumer在查詢的時候也是一次查詢大量的線性資料塊。訊息集合即MessageSet,實現本身是一個非常簡單的API,它將一個位元組陣列或者檔案進行打包。所以對訊息的處理,這裡沒有分開的序列化和反序列化的上步驟,訊息的欄位可以按需反序列化(如果沒有需要,可以不用反序列化)。
另一個影響效率的問題就是位元組拷貝。為了解決位元組拷貝的問題,kafka設計了一種“標準位元組訊息”,Producer、Broker、Consumer共享這一種訊息格式。Kakfa的message log在broker端就是一些目錄檔案,這些日誌檔案都是MessageSet按照這種“標準位元組訊息”格式寫入到磁碟的。
維持這種通用的格式對這些操作的優化尤為重要:持久化log 塊的網路傳輸。流行的unix作業系統提供了一種非常高效的途徑來實現頁面快取和socket之間的資料傳遞。在Linux作業系統中,這種方式被稱作:sendfile system call(Java提供了訪問這個系統呼叫的方法:FileChannel.transferTo api)。
為了理解sendfile的影響,需要理解一般的將資料從檔案傳到socket的路徑:
- 作業系統將資料從磁碟讀到核心空間的頁快取中
- 應用將資料從核心空間讀到使用者空間的快取中
- 應用將資料寫回核心空間的socket快取中
- 作業系統將資料從socket快取寫到網絡卡快取中,以便將資料經網路發出
這種操作方式明顯是非常低效的,這裡有四次拷貝,兩次系統呼叫。如果使用sendfile,就可以避免兩次拷貝:作業系統將資料直接從頁快取傳送到網路上。所以在這個優化的路徑中,只有最後一步將資料拷貝到網絡卡快取中是需要的。
我們期望一個主題上有多個消費者是一種常見的應用場景。利用上述的zero-copy,資料只被拷貝到頁快取一次,然後就可以在每次消費時被重得利用,而不需要將資料存在記憶體中,然後在每次讀的時候拷貝到核心空間中。這使得訊息消費速度可以達到網路連線的速度。這樣以來,通過頁面快取和sendfile的結合使用,整個kafka叢集幾乎都已以快取的方式提供服務,而且即使下游的consumer很多,也不會對整個叢集服務造成壓力。
關於sendfile和zero-copy,請參考:zero-copy
五、Kafka叢集部署
5.1 叢集部署
為了提高效能,推薦採用專用的伺服器來部署kafka叢集,儘量與hadoop叢集分開,因為kafka依賴磁碟讀寫和大的頁面快取,如果和hadoop共享節點的話會影響其使用頁面快取的效能。
Kafka叢集的大小需要根據硬體的配置、生產者消費者的併發數量、資料的副本個數、資料的儲存時長綜合確定。
磁碟的吞吐量尤為重要,因為通常kafka的瓶頸就在磁碟上。
Kafka依賴於zookeeper,建議採用專用伺服器來部署zookeeper叢集,zookeeper叢集的節點採用偶數個,一般建議用3、5、7個。注意zookeeper叢集越大其讀寫效能越慢,因為zookeeper需要在節點之間同步資料。一個3節點的zookeeper叢集允許一個節點失敗,一個5節點叢集允許2個幾點失敗。
5.2 叢集大小
有很多因素決定著kafka叢集需要具備儲存能力的大小,最準確的衡量辦法就是模擬負載來測算一下,Kafka本身也提供了負載測試的工具。
如果不想通過模擬實驗來評估叢集大小,最好的辦法就是根據硬碟的空間需求來推算。下面我就根據網路和磁碟吞吐量需求來做一下估算。
我們做如下假設:
- W:每秒寫多少MB
- R :副本數
- C :Consumer的數量
一般的來說,kafka叢集瓶頸在於網路和磁碟吞吐量,所以我們先評估一下叢集的網路和磁碟需求。
對於每條訊息,每個副本都要寫一遍,所以整體寫的速度是W*R。讀資料的部分主要是叢集內部各個副本從leader同步訊息讀和叢集外部的consumer讀,所以叢集內部讀的速率是(R-1)*W,同時,外部consumer讀的速度是C*W,因此:
- Write:W*R
- Read:(R-1)*W+C*W
需要注意的是,我們可以在讀的時候快取部分資料來減少IO操作,如果一個叢集有M MB記憶體,寫的速度是W MB/sec,則允許M/(W*R) 秒的寫可以被快取。如果叢集有32GB記憶體,寫的速度是50MB/s的話,則可以至少快取10分鐘的資料。
5.3 Kafka效能測試
5.4 Kafka在zookeeper中的資料結構
六、Kafka主要配置
6.1 Broker Config
| 屬性 | 預設值 | 描述 |
|---|---|---|
| broker.id | 必填引數,broker的唯一標識 | |
| log.dirs | /tmp/kafka-logs | Kafka資料存放的目錄。可以指定多個目錄,中間用逗號分隔,當新partition被建立的時會被存放到當前存放partition最少的目錄。 |
| port | 9092 | BrokerServer接受客戶端連線的埠號 |
| zookeeper.connect | null | Zookeeper的連線串,格式為:hostname1:port1,hostname2:port2,hostname3:port3。可以填一個或多個,為了提高可靠性,建議都填上。注意,此配置允許我們指定一個zookeeper路徑來存放此kafka叢集的所有資料,為了與其他應用叢集區分開,建議在此配置中指定本叢集存放目錄,格式為:hostname1:port1,hostname2:port2,hostname3:port3/chroot/path 。需要注意的是,消費者的引數要和此引數一致。 |
| message.max.bytes | 1000000 | 伺服器可以接收到的最大的訊息大小。注意此引數要和consumer的maximum.message.size大小一致,否則會因為生產者生產的訊息太大導致消費者無法消費。 |
| num.io.threads | 8 | 伺服器用來執行讀寫請求的IO執行緒數,此引數的數量至少要等於伺服器上磁碟的數量。 |
| queued.max.requests | 500 | I/O執行緒可以處理請求的佇列大小,若實際請求數超過此大小,網路執行緒將停止接收新的請求。 |
| socket.send.buffer.bytes | 100 * 1024 | The SO_SNDBUFF buffer the server prefers for socket connections. |
| socket.receive.buffer.bytes | 100 * 1024 | The SO_RCVBUFF buffer the server prefers for socket connections. |
| socket.request.max.bytes | 100 * 1024 * 1024 | 伺服器允許請求的最大值, 用來防止記憶體溢位,其值應該小於 Java heap size. |
| num.partitions | 1 | 預設partition數量,如果topic在建立時沒有指定partition數量,預設使用此值,建議改為5 |
| log.segment.bytes | 1024 * 1024 * 1024 | Segment檔案的大小,超過此值將會自動新建一個segment,此值可以被topic級別的引數覆蓋。 |
| log.roll.{ms,hours} | 24 * 7 hours | 新建segment檔案的時間,此值可以被topic級別的引數覆蓋。 |
| log.retention.{ms,minutes,hours} | 7 days | Kafka segment log的儲存週期,儲存週期超過此時間日誌就會被刪除。此引數可以被topic級別引數覆蓋。資料量大時,建議減小此值。 |
| log.retention.bytes | -1 | 每個partition的最大容量,若資料量超過此值,partition資料將會被刪除。注意這個引數控制的是每個partition而不是topic。此引數可以被log級別引數覆蓋。 |
| log.retention.check.interval.ms | 5 minutes | 刪除策略的檢查週期 |
| auto.create.topics.enable | true | 自動建立topic引數,建議此值設定為false,嚴格控制topic管理,防止生產者錯寫topic。 |
| default.replication.factor | 1 | 預設副本數量,建議改為2。 |
| replica.lag.time.max.ms | 10000 | 在此視窗時間內沒有收到follower的fetch請求,leader會將其從ISR(in-sync replicas)中移除。 |
| replica.lag.max.messages | 4000 | 如果replica節點落後leader節點此值大小的訊息數量,leader節點就會將其從ISR中移除。 |
| replica.socket.timeout.ms | 30 * 1000 | replica向leader傳送請求的超時時間。 |
| replica.socket.receive.buffer.bytes | 64 * 1024 | The socket receive buffer for network requests to the leader for replicating data. |
| replica.fetch.max.bytes | 1024 * 1024 | The number of byes of messages to attempt to fetch for each partition in the fetch requests the replicas send to the leader. |
| replica.fetch.wait.max.ms | 500 | The maximum amount of time to wait time for data to arrive on the leader in the fetch requests sent by the replicas to the leader. |
| num.replica.fetchers | 1 | Number of threads used to replicate messages from leaders. Increasing this value can increase the degree of I/O parallelism in the follower broker. |
| fetch.purgatory.purge.interval.requests | 1000 | The purge interval (in number of requests) of the fetch request purgatory. |
| zookeeper.session.timeout.ms | 6000 | ZooKeeper session 超時時間。如果在此時間內server沒有向zookeeper傳送心跳,zookeeper就會認為此節點已掛掉。 此值太低導致節點容易被標記死亡;若太高,.會導致太遲發現節點死亡。 |
| zookeeper.connection.timeout.ms | 6000 | 客戶端連線zookeeper的超時時間。 |
| zookeeper.sync.time.ms | 2000 | H ZK follower落後 ZK leader的時間。 |
| controlled.shutdown.enable | true | 允許broker shutdown。如果啟用,broker在關閉自己之前會把它上面的所有leaders轉移到其它brokers上,建議啟用,增加叢集穩定性。 |
| auto.leader.rebalance.enable | true | If this is enabled the controller will automatically try to balance leadership for partitions among the brokers by periodically returning leadership to the “preferred” replica for each partition if it is available. |
| leader.imbalance.per.broker.percentage | 10 | The percentage of leader imbalance allowed per broker. The controller will rebalance leadership if this ratio goes above the configured value per broker. |
| leader.imbalance.check.interval.seconds | 300 | The frequency with which to check for leader imbalance. |
| offset.metadata.max.bytes | 4096 | The maximum amount of metadata to allow clients to save with their offsets. |
| connections.max.idle.ms | 600000 | Idle connections timeout: the server socket processor threads close the connections that idle more than this. |
| num.recovery.threads.per.data.dir | 1 | The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. |
| unclean.leader.election.enable | true | Indicates whether to enable replicas not in the ISR set to be elected as leader as a last resort, even though doing so may result in data loss. |
| delete.topic.enable | false | 啟用deletetopic引數,建議設定為true。 |
| offsets.topic.num.partitions | 50 | The number of partitions for the offset commit topic. Since changing this after deployment is currently unsupported, we recommend using a higher setting for production (e.g., 100-200). |
| offsets.topic.retention.minutes | 1440 | Offsets that are older than this age will be marked for deletion. The actual purge will occur when the log cleaner compacts the offsets topic. |
| offsets.retention.check.interval.ms | 600000 | The frequency at which the offset manager checks for stale offsets. |
| offsets.topic.replication.factor | 3 | The replication factor for the offset commit topic. A higher setting (e.g., three or four) is recommended in order to ensure higher availability. If the offsets topic is created when fewer brokers than the replication factor then the offsets topic will be created with fewer replicas. |
| offsets.topic.segment.bytes | 104857600 | Segment size for the offsets topic. Since it uses a compacted topic, this should be kept relatively low in order to facilitate faster log compaction and loads. |
| offsets.load.buffer.size | 5242880 | An offset load occurs when a broker becomes the offset manager for a set of consumer groups (i.e., when it becomes a leader for an offsets topic partition). This setting corresponds to the batch size (in bytes) to use when reading from the offsets segments when loading offsets into the offset manager’s cache. |
| offsets.commit.required.acks | -1 | The number of acknowledgements that are required before the offset commit can be accepted. This is similar to the producer’s acknowledgement setting. In general, the default should not be overridden. |
| offsets.commit.timeout.ms | 5000 | The offset commit will be delayed until this timeout or the required number of replicas have received the offset commit. This is similar to the producer request timeout. |
6.2 Producer Config
| 屬性 | 預設值 | 描述 |
|---|---|---|
| metadata.broker.list | 啟動時producer查詢brokers的列表,可以是叢集中所有brokers的一個子集。注意,這個引數只是用來獲取topic的元資訊用,producer會從元資訊中挑選合適的broker並與之建立socket連線。格式是:host1:port1,host2:port2。 | |
| request.required.acks | 0 | 參見3.2節介紹 |
| request.timeout.ms | 10000 | Broker等待ack的超時時間,若等待時間超過此值,會返回客戶端錯誤資訊。 |
| producer.type | sync | 同步非同步模式。async表示非同步,sync表示同步。如果設定成非同步模式,可以允許生產者以batch的形式push資料,這樣會極大的提高broker效能,推薦設定為非同步。 |
| serializer.class | kafka.serializer.DefaultEncoder | 序列號類,.預設序列化成 byte[] 。 |
| key.serializer.class | Key的序列化類,默認同上。 | |
| partitioner.class | kafka.producer.DefaultPartitioner | Partition類,預設對key進行hash。 |
| compression.codec | none | 指定producer訊息的壓縮格式,可選引數為: “none”, “gzip” and “snappy”。關於壓縮參見4.1節 |
| compressed.topics | null | 啟用壓縮的topic名稱。若上面引數選擇了一個壓縮格式,那麼壓縮僅對本引數指定的topic有效,若本引數為空,則對所有topic有效。 |
| message.send.max.retries | 3 | Producer傳送失敗時重試次數。若網路出現問題,可能會導致不斷重試。 |
| retry.backoff.ms | 100 | Before each retry, the producer refreshes the metadata of relevant topics to see if a new leader has been elected. Since leader election takes a bit of time, this property specifies the amount of time that the producer waits before refreshing the metadata. |
| topic.metadata.refresh.interval.ms | 600 * 1000 | The producer generally refreshes the topic metadata from brokers when there is a failure (partition missing, leader not available…). It will also poll regularly (default: every 10min so 600000ms). If you set this to a negative value, metadata will only get refreshed on failure. If you set this to zero, the metadata will get refreshed after each message sent (not recommended). Important note: the refresh happen only AFTER the message is sent, so if the producer never sends a message the metadata is never refreshed |
| queue.buffering.max.ms | 5000 | 啟用非同步模式時,producer快取訊息的時間。比如我們設定成1000時,它會快取1秒的資料再一次傳送出去,這樣可以極大的增加broker吞吐量,但也會造成時效性的降低。 |
| queue.buffering.max.messages | 10000 | 採用非同步模式時producer buffer 佇列裡最大快取的訊息數量,如果超過這個數值,producer就會阻塞或者丟掉訊息。 |
| queue.enqueue.timeout.ms | -1 | 當達到上面引數值時producer阻塞等待的時間。如果值設定為0,buffer佇列滿時producer不會阻塞,訊息直接被丟掉。若值設定為-1,producer會被阻塞,不會丟訊息。 |
| batch.num.messages | 200 | 採用非同步模式時,一個batch快取的訊息數量。達到這個數量值時producer才會傳送訊息。 |
| send.buffer.bytes | 100 * 1024 | Socket write buffer size |
| client.id | “” | The client id is a user-specified string sent in each request to help trace calls. It should logically identify the application making the request. |
6.3 Consumer Config
| 屬性 | 預設值 | 描述 |
|---|---|---|
| group.id | Consumer的組ID,相同goup.id的consumer屬於同一個組。 | |
| zookeeper.connect | Consumer的zookeeper連線串,要和broker的配置一致。 | |
| consumer.id | null | 如果不設定會自動生成。 |
| socket.timeout.ms | 30 * 1000 | 網路請求的socket超時時間。實際超時時間由max.fetch.wait + socket.timeout.ms 確定。 |
| socket.receive.buffer.bytes | 64 * 1024 | The socket receive buffer for network requests. |
| fetch.message.max.bytes | 1024 * 1024 | 查詢topic-partition時允許的最大訊息大小。consumer會為每個partition快取此大小的訊息到記憶體,因此,這個引數可以控制consumer的記憶體使用量。這個值應該至少比server允許的最大訊息大小大,以免producer傳送的訊息大於consumer允許的訊息。 |
| num.consumer.fetchers | 1 | The number fetcher threads used to fetch data. |
| auto.commit.enable | true | 如果此值設定為true,consumer會週期性的把當前消費的offset值儲存到zookeeper。當consumer失敗重啟之後將會使用此值作為新開始消費的值。 |
| auto.commit.interval.ms | 60 * 1000 | Consumer提交offset值到zookeeper的週期。 |
| queued.max.message.chunks | 2 | 用來被consumer消費的message chunks 數量, 每個chunk可以快取fetch.message.max.bytes大小的資料量。 |
| rebalance.max.retries | 4 | When a new consumer joins a consumer group the set of consumers attempt to “rebalance” the load to assign partitions to each consumer. If the set of consumers changes while this assignment is taking place the rebalance will fail and retry. This setting controls the maximum number of attempts before giving up. |
| fetch.min.bytes | 1 | The minimum amount of data the server should return for a fetch request. If insufficient data is available the request will wait for that much data to accumulate before answering the request. |
| fetch.wait.max.ms | 100 | The maximum amount of time the server will block before answering the fetch request if there isn’t sufficient data to immediately satisfy fetch.min.bytes. |
| rebalance.backoff.ms | 2000 | Backoff time between retries during rebalance. |
| refresh.leader.backoff.ms | 200 | Backoff time to wait before trying to determine the leader of a partition that has just lost its leader. |
| auto.offset.reset | largest | What to do when there is no initial offset in ZooKeeper or if an offset is out of range ;smallest : automatically reset the offset to the smallest offset; largest : automatically reset the offset to the largest offset;anything else: throw exception to the consumer |
| consumer.timeout.ms | -1 | 若在指定時間內沒有訊息消費,consumer將會丟擲異常。 |
| exclude.internal.topics | true | Whether messages from internal topics (such as offsets) should be exposed to the consumer. |
| zookeeper.session.timeout.ms | 6000 | ZooKeeper session timeout. If the consumer fails to heartbeat to ZooKeeper for this period of time it is considered dead and a rebalance will occur. |
| zookeeper.connection.timeout.ms | 6000 | The max time that the client waits while establishing a connection to zookeeper. |
| zookeeper.sync.time.ms | 2000 | How far a ZK follower can be behind a ZK leader |