
Spark原始碼解析(一):Spark執行流程和指令碼
Spark帶註釋原始碼
對於整個Spark原始碼分析系列,我將帶有註釋的Spark原始碼和分析的檔案放在我的GitHub上Spark原始碼剖析歡迎大家fork和star
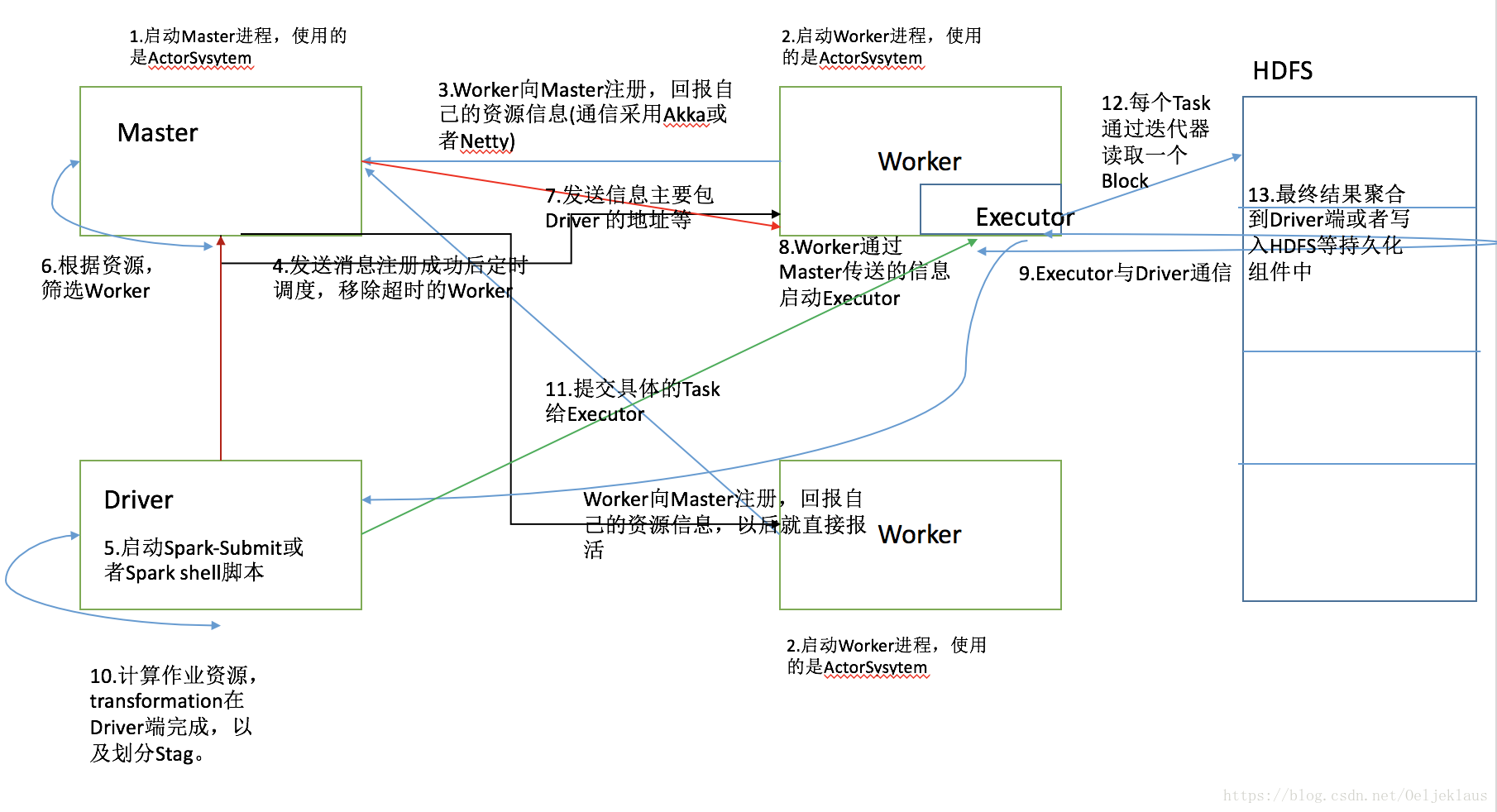
過程描述:
1.通過Shell指令碼啟動Master,Master類繼承Actor類,通過ActorySystem建立並啟動。
2.通過Shell指令碼啟動Worker,Worker類繼承Actor類,通過ActorySystem建立並啟動。
3.Worker通過Akka或者Netty傳送訊息向Master註冊並彙報自己的資源資訊(記憶體以及CPU核數等),以後就是定時彙報,保持心跳。
4.Master接受訊息後儲存(原始碼中通過持久化引擎持久化)併發送訊息表示Worker註冊成功,並且定時排程,移除超時的Worker。
5.通過Spark-Submit提交作業或者通過Spark Shell指令碼連線叢集,都會啟動一個Spark程序Driver。
6.Master拿到作業後根據資源篩選Worker並與Worker通訊,傳送資訊,主要包含Driver的地址等。
7.Worker進行收到訊息後,啟動Executor,Executor與Driver通訊。
8.Driver端計算作業資源,transformation在Driver 端完成,劃分各個Stage後提交Task給Executor。
9.Exectuor針對於每一個Task讀取HDFS檔案,然後計算結果,最後將計算的最終結果聚合到Driver端或者寫入到持久化元件中。
Spark啟動Shell指令碼
1.start-all.sh

可以中指令碼檔案看出,spark啟動事首選啟動spark-config.sh,然後啟動start-master.sh 最後啟動指令碼
2.start-master.sh指令碼
${SPARK_HOME}/sbin"/spark-daemon.sh start $CLASS1 \ --ip $SPARK_MASTER_IP--port $SPARK_MASTER_PORT--webui-port $SPARK_MASTER_WEBUI_PORT\ $ORIGINAL_ARGS
start-master.sh指令碼主要執行的是這一塊邏輯,主要使用spark-daemon.sh利用傳入的引數啟動Spark。
3.spark-daemon.sh指令碼
nohup nice -n"$SPARK_NICENESS""${SPARK_HOME}"/bin/spark-class $command"[email protected]">> "$log"2>&1 < /dev/null &指令碼中啟動執行的主要指令碼命令是上述程式碼,主要通過${SPARK_HOME}/bin/spark-class啟動,接下來我們看一下spark-class
4.spark-class檔案
done< <("$RUNNER"-cp"$LAUNCH_CLASSPATH"org.apache.spark.launcher.Main "[email protected]") exec "${CMD[@]}" //這裡是$RUNNER代表的含義 if[ -n"${JAVA_HOME}"]; then RUNNER="${JAVA_HOME}/bin/java" else if[ `command -v java`]; then RUNNER="java" else echo"JAVA_HOME is not set">&2 exit1 fi fi //這裡是$LAUNCH_CLASSPATH表示的含義 SPARK_ASSEMBLY_JAR= if[ -f"${SPARK_HOME}/RELEASE"]; then ASSEMBLY_DIR="${SPARK_HOME}/lib" else ASSEMBLY_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION" fi SPARK_ASSEMBLY_JAR="${ASSEMBLY_DIR}/${ASSEMBLY_JARS}" LAUNCH_CLASSPATH="$SPARK_ASSEMBLY_JAR"
從上面的程式碼可以看出主要是通過獲取Java環境然後啟動Spark程式
Spark Submit指令碼
關於作業提交的主要指令碼是spark-submit指令碼,主要執行的程式碼是
exec "$SPARK_HOME"/bin/spark-class org.apache.spark.deploy.SparkSubmit "${ORIG_ARGS[@]}"這裡主要的用到的類是org.apache.spark.deploy.SparkSubmit,接下來我們將要看SparkSubmit程式碼,這裡的Spark程式碼基於Spark1.3.1
SparkSubmit類
/bin/spark-submit \ --classcn.edu.hust.WordCount \ --masterspark://207.184.161.138:7077 \ --executor-memory20G \ --total-executor-cores100\ /path/to/examples.jar \ 1000
下面是SparkSubmit類的時序圖:
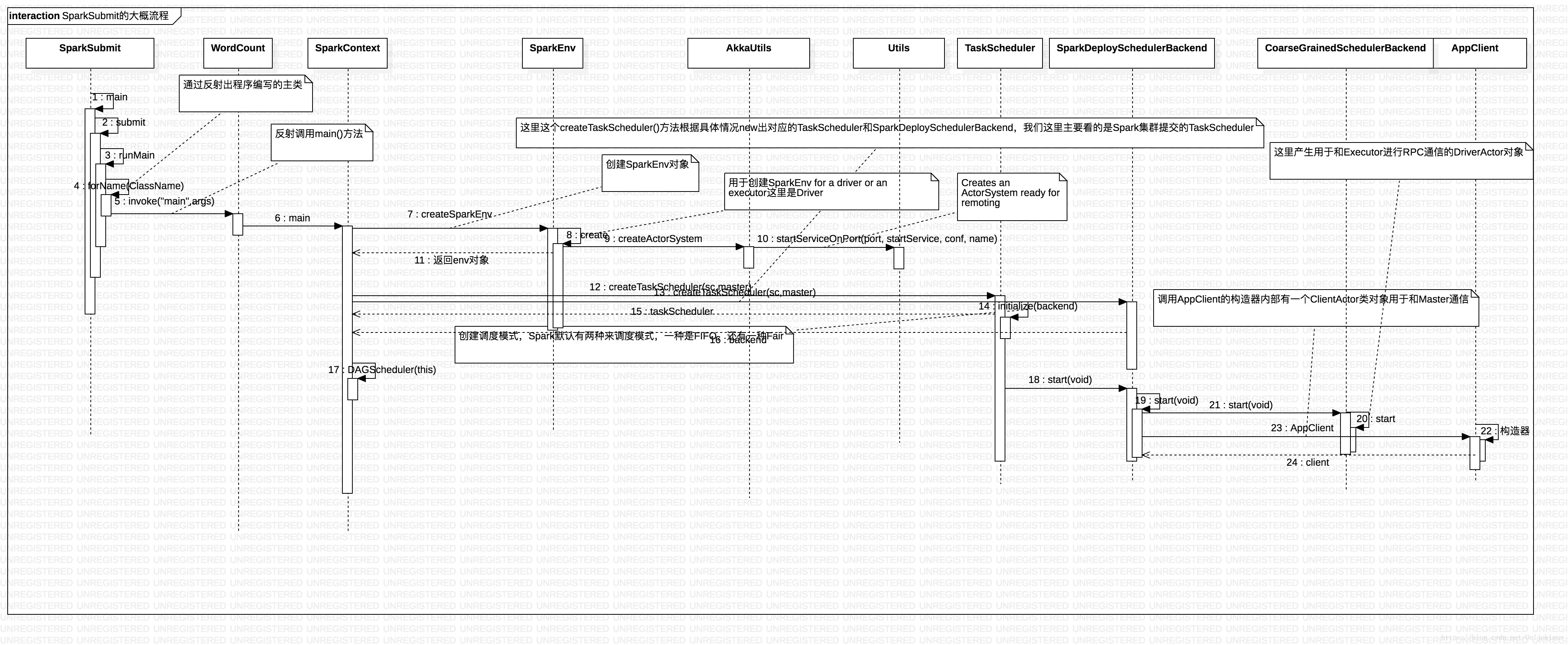
具體敘述流程如下 :
2.在WordCount類中,main()方法裡有呼叫SparkContext,SparkContext構造器使用createSparkEnv()方法,這個方法使用SparkEnv.createDriverEnv(conf, isLocal, listenerBus)方法建立SparkEnv物件;在SparkEnv類,呼叫create()方法來進行建立SparkEnv,在這個方法內部,有一個AkkaUtils.createActorSystem(actorSystemName, hostname, port, conf, securityManager)的呼叫過程,主要用來產生Akka中的ActorSystem以及得到繫結的埠號。
3.在建立SparkEnv物件後,SparkContext構造器使用程式碼SparkContext.createTaskScheduler(this, master)建立TaskScheduler物件,這裡根據實際的提交模式來進行建立TaskScheduler物件,提交模式有:local、Mesos、Zookeeper、Simr、Spark,這裡模們主要分析Spark叢集下的模式;然後還需要建立一個SparkDeploySchedulerBackend物件;在建立TaskScheduler物件呼叫initialize()方法,這裡選擇排程模式,主要有兩種模式,FIFO和FAIR,預設的排程模式;最後呼叫taskScheduler的start()方法,裡面主要呼叫SparkDeploySchedulerBackend物件的start()方法,首先呼叫父類的start()方法產生一個用於和Executor通訊的DriverActor物件,然後裡面主要建立一個AppClient物件內部有ClientActor類物件,用於Driver和Master進行RPC通訊。相關係列文章
微信公眾號
有興趣的同學可以關注一下小編喲!
