
YOLOv2與YOLO9000演算法詳解
YOLOv2與YOLO9000演算法詳解
論文背景
論文全稱:YOLO9000: Better, Faster, Stronger
論文連結:https://arxiv.org/abs/1612.08242
論文日期:2016.12.25
首先在YOLO演算法的基礎上進行了改進,稱為 YOLOv2。
在YOLOv2演算法的基礎上,對資料集進行了融合,提出一個實時檢測演算法,能識別超過9000類物件,演算法被稱為YOLO9000。
本文提出了一種能聯合訓練目標檢測與分類的方法,這種聯合訓練允許YOLO9000預測沒有檢測資料標籤的物件類的檢測。
既能保證檢測速度,又能保證準確率:
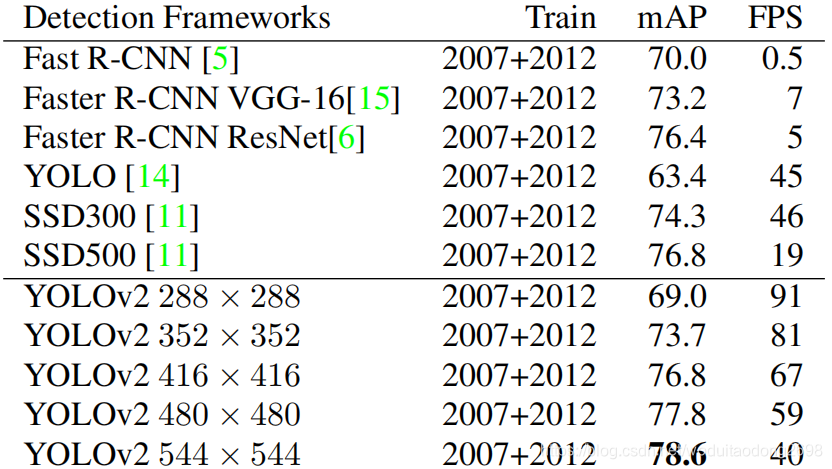
- At 67 FPS, YOLOv2 gets 76.8 mAP on VOC 2007.
- At 40 FPS, YOLOv2 gets 78.6 mAP。
演算法簡介
相對於分類任務,目標檢測任務的資料集圖片數目以及標籤更小,同時檢測的標籤圖片比分類的標籤圖片更昂貴。因此,我們不太可能在不久的將來看到與分類資料集具有相同規模的檢測資料集。
本文希望能提出一種新的方法,能利用原有的分類資料集來拓展檢測系統。因此使用一種目標分類問題中的分層觀念,這樣就允許將不同的資料集結合起來。
本文也提出一種聯合訓練的方法,在檢測與分類資料上均訓練目標檢測器。提取標籤檢測影象,以便學習精確定位物件,同時考慮分類影象以增加其詞彙量和魯棒性。
之前的演算法只能檢測少部分的物件。YOLO9000能檢測9000類樣本。
演算法細節
優化方向:
- YOLO與Faster RCNN相比,YOLO有很顯著的定位誤差;
- 相對區域檢測演算法,YOLO有更低的查全率(recall)。
神經網路結構改進:
- 不進行神經網路尺寸的擴大,而進行神經網路的簡化,從而使表示更容易學習。
YOLOv2
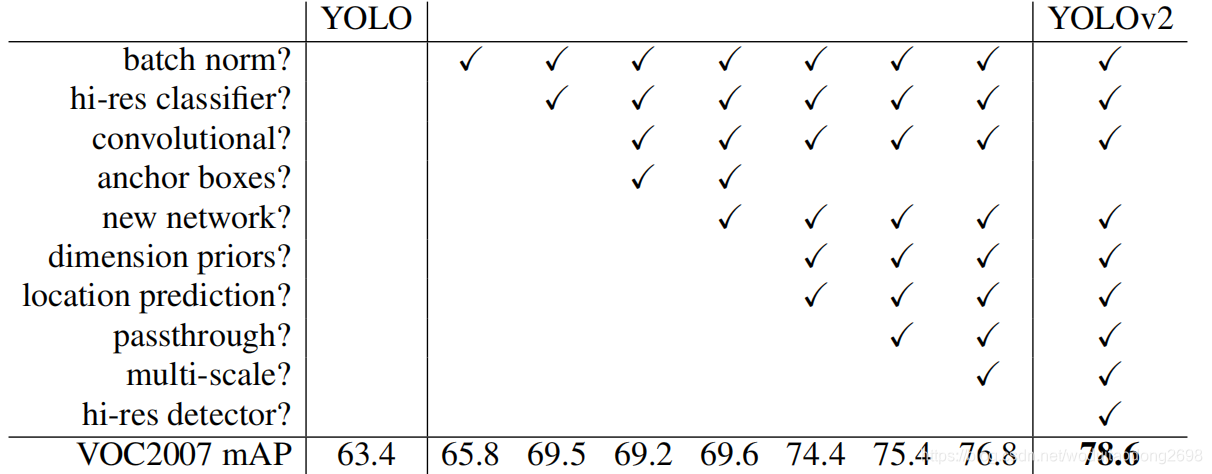
BN:
在所有的卷積層都加入了BN(區域性正則化),準確率提高了2% mAP。在加入BN之後,可以移除dropout。
High Resolution Classifier:
輸入圖片由224×224調整至448×448,準確率提高了4% mAP。
Convolutional With Anchor Boxes:
YOLO直接使用全連線層預測邊界框的座標,而不是使用手工挑選的標籤預測邊界框。
FasterR-CNN使用RPN預測偏移與錨框的置信度。因為預測層是卷積層,在特徵圖的每一個位置都要預測偏移,因此預測偏移比預測座標要簡單。
移除YOLO的全連線層,並且使用錨框來預測邊界框,首先消除一個池化層,使卷積層輸出解析度更高。
同時還使用神經網路處理416×416的輸入圖片,而不是448×448。
我們需要在特徵圖上有奇數個位置,因此只有一箇中心單元格,尤其是大目標,會佔據圖片的中心,因此最好在中心有一個位置來預測這些物體而不是四個位於其附近的物體。 YOLO的卷積層將影象取樣為32倍,因此通過使用416的輸入影象,我們得到13×13的輸出特徵圖。
當我們移動到錨框時,我們還將類預測機制與空間位置預測分離,預測每個錨箱的類和物件。 在YOLO之後,物件預測仍然預測相對於真實標籤的IOU,並且類預測在給定存在物件的情況下預測該類的條件概率。
在使用錨框之後,準確率有了輕微的下降,但是查全率得到了提高。
Dimension Clusters:
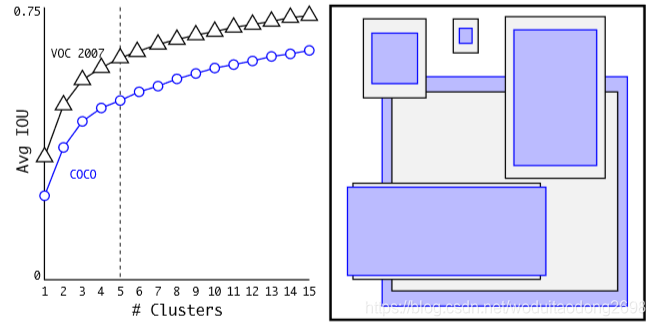
使用錨框時,遇到了兩個問題,首先是邊界框尺寸的選擇。不使用手工提取的方法,而是使用 k-means 演算法。
如果我們使用具有歐幾里德距離的標準k-means演算法,那麼較大的框會產生比較小的框更多的誤差。 然而,我們真正想要的是能夠獲得良好IOU分數的先驗,這與框尺寸的大小無關。 因此,對於我們使用的距離度量:
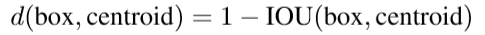
當K=5時,既能保證模型的複雜度,又能保證一個高的查全率。
我們將平均IOU與我們的聚類策略中最接近的先驗和表1中的手工挑選的錨框進行比較。 只有5個先驗,質心的表現類似於9個錨框,平均IOU為61.0相對於60.9。 如果我們使用9個質心,我們會看到更高的平均IOU。這表明使用 k-means 生成我們的邊界框會以更好的表示方式啟動模型,使任務更容易學習。

Direct location prediction:
YOLO演算法的錨框有一個問題:模型不穩定性,尤其是在早期的迭代中。這些不穩定性來源於對邊界框中心點(x, y)的定位。
在區域提取演算法中,中心點的座標表示為:
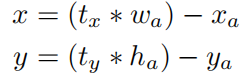
之前 YOLO的方法,網路不會預測偏移量,而是根據 YOLO 中的網格單元的位置來預測座標,這就讓 Ground Truth 的值介於 0 到 1 之間。而為了讓網路的結果能落在這一範圍內,網路使用一個 Logistic Activation 來對於網路預測結果進行限制,讓結果介於 0 到 1 之間。
在YOLOv2演算法中,每個單元格都預測5個邊界框,每個邊界框預測5個座標, tx, ty, tw, th, 與 to.
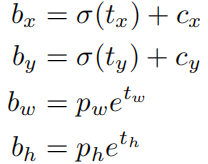

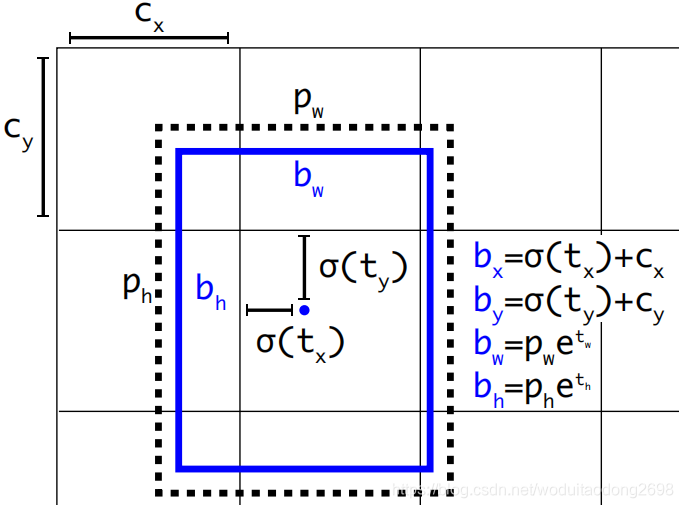
使用維度群集以及直接預測邊界框中心位置可以比使用錨框的的YOLO提高几乎5%。
Fine-Grained Features:
優化的YOLO在13x13的特徵圖上預測檢測器,對於大尺寸的物體可以很有效地檢測,但是細粒度的特徵對於小尺寸物件很有效。Faster R-CNN 與 SSD都是在不同的特徵圖上執行他們的候選區域神經網路。
本文采用不同的方法,只需新增一個passthrough層,它可以從26 x 26解析度的早期層中獲取特徵。
passthrough層通過將相鄰特徵堆疊到不同的通道而不是空間位置,將較高解析度的特徵與低解析度特徵連線起來,類似於ResNet中的標識對映。
轉換26 × 26 × 512特徵圖到13 × 13 × 2048特徵圖,可以和原始特徵連線起來。
Multi-Scale Training:
首先轉換448×448的解析度為416×416的輸入。
不固定輸入圖片的尺寸,每10個batch就任意改變輸入圖片的尺寸,下采樣因子為32,最小的輸入為320,最大的輸入是608。
實驗結果:
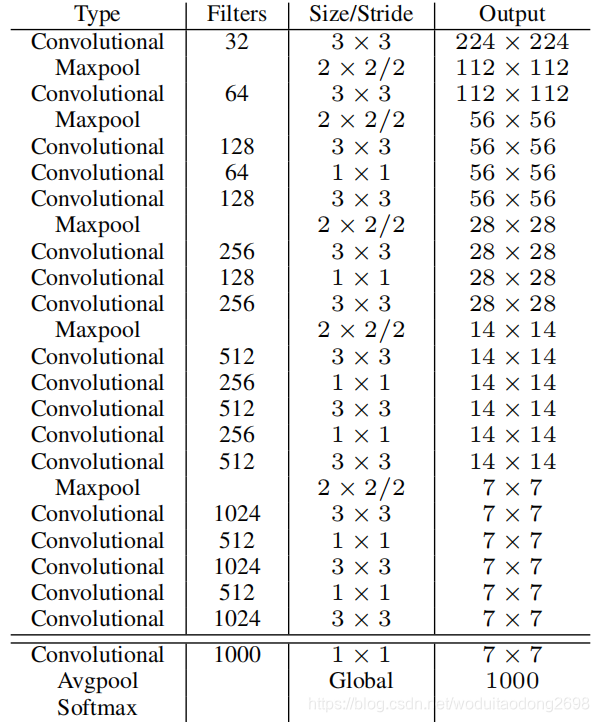
Darknet-19 神經網路結構:
Training for classification:
訓練Imagenet資料集,共有1000個類別,初始輸入圖片尺寸為224 × 224,設定學習率為0.1,利用隨機梯度下降的方法,訓練160個epoch,多項式衰減速率的冪為4,權重衰減指數為0.005,momentum 引數為0.9。輸入圖片採用標準的資料增強方法,包括隨機裁剪,旋轉以及色度,亮度的調整等。
在微調時,輸入圖片尺寸為448 × 448,引數和初始訓練大致相同,但是隻訓練10個epoch,學習率設定為0.001。
利用高解析度的圖片輸入,最終神經網路實現了a top-1 accuracy of 76.5% and a top-5 accuracy of 93.3%。
Training for detection:
在檢測時,移除了神經網路的最後一層卷積層,而是加入3個3×3的卷積層,每個卷積層有1024個filter,而且每個後面都連線一個1×1的卷積層,1×1卷積的filter個數根據需要檢測的類來定。比如對於VOC資料,由於每個grid cell我們需要預測5個box,每個box有5個座標值和20個類別值,所以每個grid cell有125個filter。然後將最後一層3 × 3 × 512層與倒數第二層連線起來,從而最後一層卷積層可獲得細粒度的特徵。
訓練時採用0.001的學習率訓練160個epoch,並且在第60與90個epoch時將學習率除以10。設定權重衰減指數為0.005,momentum 引數為0.9。使用與之前一樣的資料增強方法。
YOLO9000
分級分類:
檢測資料集標籤只有粗略的分類,但是分類資料集標籤有精細的分類。可以融合標籤。本文采用了一種多標籤模型。
某種類別的概率可分為多種概率的乘積:

其中:
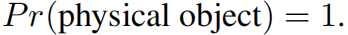
多個softmax分類:
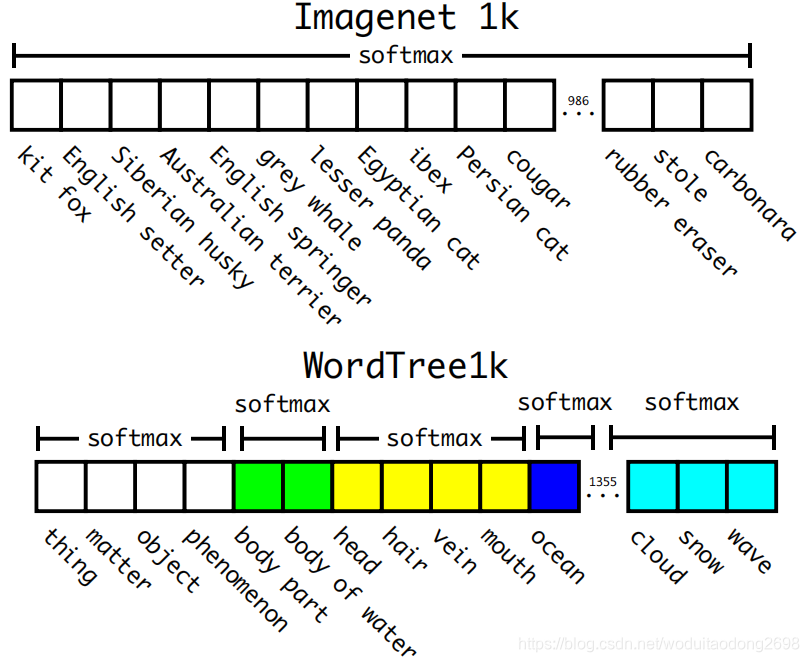
利用樹形結構進行標籤融合:
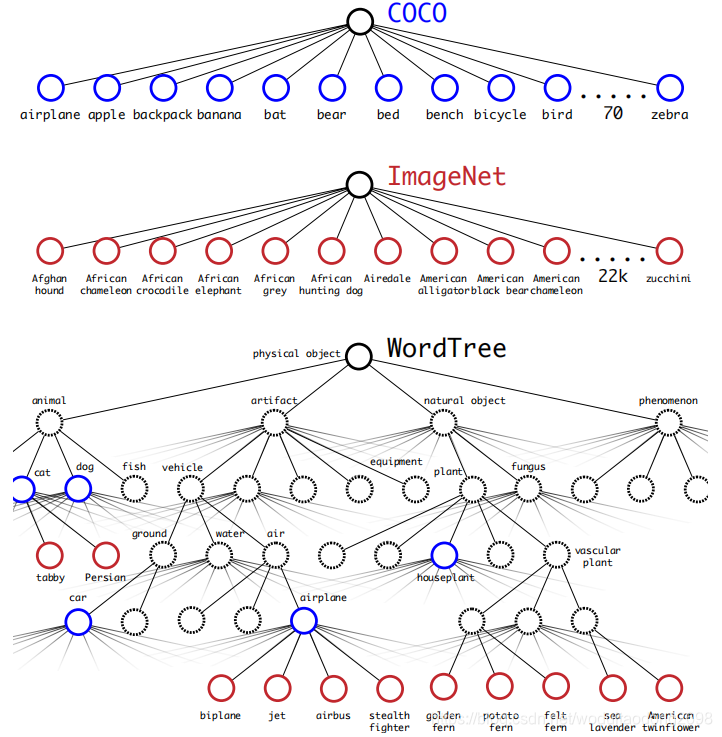
聯合訓練:
YOLOv2對於每個grid cell採用5個box prior,而YOLO9000只採用3個。從而限制輸出尺寸。
通過這種聯合訓練,YOLO9000使用COCO中的檢測資料在影象中查詢物件,並使用來自ImageNet的資料對各種物件進行分類。