
YOLO v2演算法詳解+YOLO9000介紹
YOLO9000是繼YOLO之後的又一力作,本篇論文,其實作者在YOLO v2上並沒有特別多的創新的方法,更多的是將現有的多種方法使用在自己的YOLO中以提高識別效果,不過YOLO9000倒是很有創新點,利用ImageNet與COCO資料,使得網路可以檢測9000類資料,下面簡要介紹一下這兩個網路:
首先介紹YOLO v2都使用了哪些方法:
Batch Normalization
這個不多說了,確實是有效果的。,提高了2%。
High Resolution Classifier
作者先在224大小上訓練,然後在448上進一步fine-tune得到更好的效果。這裡我們做過實驗,在自己的資料上,如果只是單純的擴大影象,在224的預訓練模型進行訓練,分類精度不會提高,反而降低了。
加anchor
加入anchor並沒有提高map,但是提高了recall,作者在paper中表示,沒加anchor前,map為69.5,recall為81%,加入anchor後,map為69.2,recall為88%。
這裡引入一張引入anchor之後與yolo v1演算法的不同:
一目瞭然,以前是每個點預測30,現在是每個anchor預測25

利用k-means代替手動設計anchor
距離設計中,作者並沒有使用均方誤差,而是使用IOU作為距離,公式如下:
d(box,centroid)= 1- IOU(box,centroid)
bounding box loss
paper並沒有使用類似於faster rcnn以及ssd的邊框預測方法,,在faster rcnn中的計算方式如下圖,其中$x_a,y_a,w_a,h_a$分別代表anchor的座標,$x,y,w,h$代表預測值,帶星的為bounding box的座標,所以faster rcnn實際計算的是與anchor的偏移值。

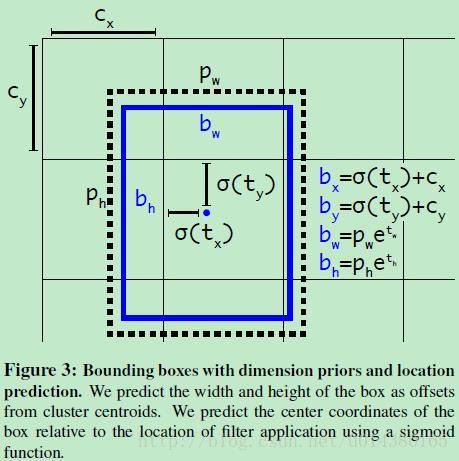
yolo v2並沒有計算與anchor的偏移值,作者解釋說計算偏移的方法由於偏移範圍比較大,計算的時候不穩定,所以yolo v2採用了計算anchor與影象左上角的位置偏移以及anchor長寬的縮放的方法,如下公式所示,$c_x,c_y$分別為anchor相對於左上角點的座標。作者使用sigmoid函式,將ground truth變換到0-1的範圍,以增加演算法的穩定性。
上面的描述可能不清楚,我們看下面的影象,yolo網路將416*416大小的輸入,經過卷積縮小32倍,得到13*13的輸出,如下圖中Cx,Cy便代表cell相對於影象左上角的偏移,注意這裡每個cell的寬度為1,sigmoid(tx)與sigmoid(ty)在0-1之間,這樣就保證了中心點的偏移仍然在當前cell內,bw與bh是相對於pw於ph的縮放,pw與ph代表anchor的長寬,至於為什麼在e上進行計算,這裡我暫時覺得與faster rcnn中的log作用類似。
Fine-Grained Features
作者考慮到,模型最終輸出是13*13,對於小物體的預測可能精度不夠高,所以同樣採用了類似於SSD的多個特徵圖的特徵,但是作者不是像SSD那樣直接對每個特徵圖進行分類與預測邊界框,而是搞了一個passthrough layer,這個是怎麼搞的呢?舉例說明,作者對上一解析度的輸出(大小為:26*26*512),通過passthrough變換為13*13*2048大小,如何變換的如下圖所示:作者利用pooling操作,將4*4的區域變換成4個channel,利用這樣的方法,將特徵圖邊長縮小一倍,但是channel數增大4倍,然後將2048維的13*13與原本的1024維的13*13進行concat,得到3072維度的特徵圖。(另,備註,這裡可以採用1*1進行512維度的降維,比如降到64,這樣passthrough之後就只有64*4=256維了,而不是2048那麼大了)
作者說這種方法,將精度提高了1%。

Multi-Scale Training
為了使yolo v2適應多種不同的尺度,作者採用了多尺度對yolo v2進行訓練,作者每10個batches自動選擇縮放的尺度,從[320:608:32]進行選擇,最小的是320*320,最大的是608*608,為什麼選擇32呢?因為yolo v2的縮放是32倍,這樣可以成倍的減少。
在測試階段,不同的輸入size可以產生不同的速度,作者的測試的mAP以及速度的結果如下:
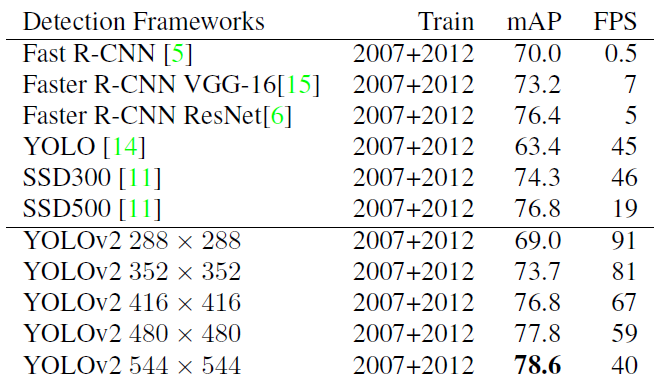

YOLO V2使用技巧的提升效果如下圖所示:

darkNet-19
為了提高模型的速度,作者沒有采用yolo v1的inception結構或者vgg結構作者base net,而是設計了darkNet-19作為基礎網路,darkNet-19採用與vgg相似的3*3卷積,並且沒有采用全連線層,借鑑了NIN網路的思想,利用global average pooling替代了全連線層,使得引數進一步的減少,並且使用了bn等,使得梯度更加的穩定,dark-net在imagenet上的表現可以達到top1:72.9%, top5: 91.2%, darkNet-19的網路結構圖,如下所示:

具體引數為:

訓練過程
1.分類的訓練
對於分類的訓練,作者並沒有什麼特殊的方式,首先利用ImageNet訓練160個epoch,採用梯度下降方法,採用多項式方法衰減學習率,weight decay 0.0005, momentum 0.9, 使用隨機裁剪,旋轉,亮度變換等方式進行資料增強。為了達到更好的效果,作者在448*448解析度上進一步fine-tune網路10,做10個epoch,初始學習率為0.001。
2.檢測的訓練
對於檢測網路,作者去掉最後一個卷積層,接3個1024*3*3的卷積層,然後接1*1的卷積層,輸出維度為(num_anchor*(class + 5)),用於預測每個anchor的類別以及4個座標加上置信度。同樣檢測迭代160個epoch,初始學習率為0.001,在60,90調整學習率為原來的0.1,weight decay為0.0005,momentum為0.9
Loss Function
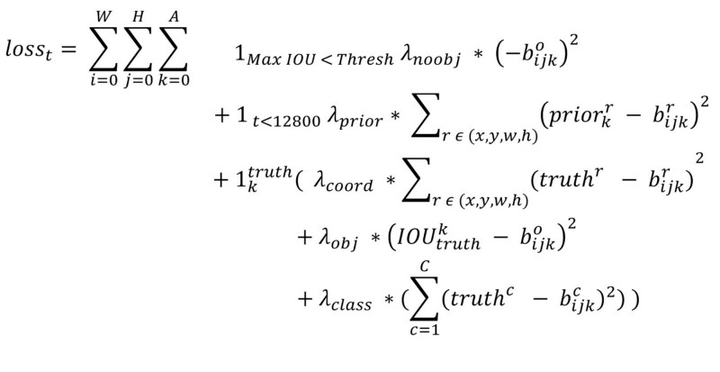
首先說明一下,YOLO中一個ground truth只會與一個先驗框進行匹配,匹配原則是IOU最大這裡不同於SSD以及RPN,其每個ground-truth會與多個IOU進行匹配
YOLO9000
其實這是這篇文章最大的創新點,算是一個開創性的方法
YOLO9000的最大創新點在於不僅使用檢測資料,同時使用了ImageNet分類資料,檢測資料,使用帶bounding box的損失函式,分類資料使用不帶bounding box的損失函式,但是這樣做遇到一個問題:imagenet資料有1000類,而voc只有20類,比如一個狗,imagenet中分為好多種,這樣便存在包含關係,便無法使用softmax進行分類了,該如何解決呢?作者採用了一種層次分類的方法,如下圖所示:
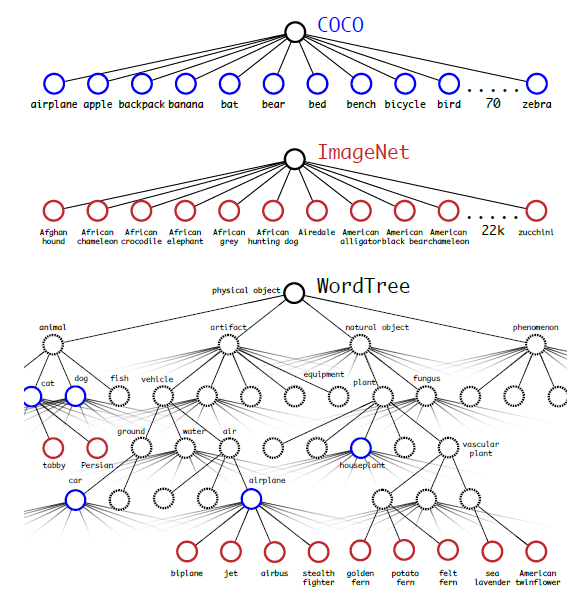
在計算某個節點的類別概率時,遍歷path,然後計算path上各個節點的概率之積。
作者在論文中提到為構建這顆樹,將1000類增加中間節點到1369類,比如Norfold terrier即會label成dog同時會label成mammal
融合分類與檢測同步進行訓練
作者使用full ImageNet(top 9000 classes)以及COCO資料集進行訓練,首先構建WordTree,共包含9418個類節點,每個節點都是一個softmax,由於ImageNet過大,這樣分類和檢測的資料嚴重不平衡,所以作者採用對COCO過取樣的方式進行資料集擴增,擴增到ImageNet的1/4.
另外作者,使用3個anchor替代原來的5個,以減少網路的輸出(由於這裡類別數太多,而對於每個anchor,網路都會預測所屬類別,所以減少2個anchor可以減少很多的網路輸出,現在每個位置是3*(4+1+9418),原來是5*(4+1+9418))如果是待檢測就用正常的yolo v2的損失,對於分類部分,只返回相應level的loss為什麼呢?因為如果預測是狗,檢測資料集並沒有標註這是什麼狗,你怎麼返回具體是什麼狗的loss呢~如果是遇到了一張分類的影象,首先返回分類的loss,就利用前面predict tree的計算方法(概率乘積),
這裡有一塊沒懂:We also assume that the predicted box overlaps what would be the ground truth label by at least 0.3IOU and we backpropagate objectness loss based on this assumption.
總之作者總結到,這種方法就是:
Using this joint training, YOLO9000 learns to find objects in images using the detection data in COCO and it learns to classify a wide variety of these objects using data from ImageNet.