
SVM支援向量機原理(二) 線性支援向量機的軟間隔最大化模型
在支援向量機原理(一) 線性支援向量機中,我們對線性可分SVM的模型和損失函式優化做了總結。最後我們提到了有時候不能線性可分的原因是線性資料集裡面多了少量的異常點,由於這些異常點導致了資料集不能線性可分,本篇就對線性支援向量機如何處理這些異常點的原理方法做一個總結。
1. 線性分類SVM面臨的問題
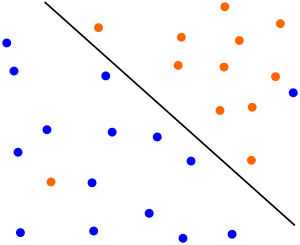
有時候本來資料的確是可分的,也就是說可以用 線性分類SVM的學習方法來求解,但是卻因為混入了異常點,導致不能線性可分,比如下圖,本來資料是可以按下面的實線來做超平面分離的,可以由於一個橙色和一個藍色的異常點導致我們沒法按照上一篇線性支援向量機中的方法來分類。
另外一種情況沒有這麼糟糕到不可分,但是會嚴重影響我們模型的泛化預測效果,比如下圖,本來如果我們不考慮異常點,SVM的超平面應該是下圖中的紅色線所示,但是由於有一個藍色的異常點,導致我們學習到的超平面是下圖中的粗虛線所示,這樣會嚴重影響我們的分類模型預測效果。
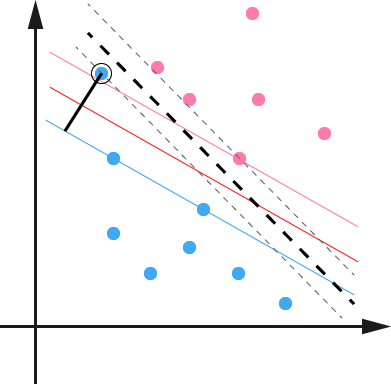
如何解決這些問題呢?SVM引入了軟間隔最大化的方法來解決。
2. 線性分類SVM的軟間隔最大化
所謂的軟間隔,是相對於硬間隔說的,我們可以認為上一篇線性分類SVM的學習方法屬於硬間隔最大化。
回顧下硬間隔最大化的條件:
接著我們再看如何可以軟間隔最大化呢?
SVM對訓練集裡面的每個樣本
對比硬間隔最大化,可以看到我們對樣本到超平面的函式距離的要求放鬆了,之前是一定要大於等於1,現在只需要加上一個大於等於0的鬆弛變數能大於等於1就可以了。當然,鬆弛變數不能白加,這是有成本的,每一個鬆弛變數
這裡,
也就是說,我們希望
這個目標函式的優化和上一篇的線性可分SVM的優化方式類似,我們下面就來看看怎麼對線性分類SVM的軟間隔最大化來進行學習優化。
3. 線性分類SVM的軟間隔最大化目標函式的優化
和線性可分SVM的優化方式類似,我們首先將軟間隔最大化的約束問題用拉格朗日函式轉化為無約束問題如下:
其中
也就是說,我們現在要優化的目標函式是:
這個優化目標也滿足KKT條件,也就是說,我們可以通過拉格朗日對偶將我們的優化問題轉化為等價的對偶問題來求解如下:
我們可以先求優化函式對於
首先我們來求優化函式對於