
MapReduce原理(執行機制)
MapReduce簡介
MapReduce是面向大資料並行處理的計算模型、框架和平臺,它隱含了以下三層含義:
1)MapReduce是一個基於叢集的高效能平行計算平臺(Cluster Infrastructure)。它允許用市場上普通的商用伺服器構成一個包含數十、數百至數千個節點的分佈和平行計算叢集。
2)MapReduce是一個平行計算與執行軟體框架(Software Framework)。它提供了一個龐大但設計精良的平行計算軟體框架,能自動完成計算任務的並行化處理,自動劃分計算資料和計算任務,在叢集節點上自動分配和執行任務以及收集計算結果,將資料分佈儲存、資料通訊、容錯處理等平行計算涉及到的很多系統底層的複雜細節交由系統負責處理,大大減少了軟體開發人員的負擔。
3)MapReduce是一個並行程式設計模型與方法(Programming Model & Methodology)。它藉助於函式式程式設計語言Lisp的設計思想,提供了一種簡便的並行程式設計方法,用Map和Reduce兩個函式程式設計實現基本的平行計算任務,提供了抽象的操作和並行程式設計介面,以簡單方便地完成大規模資料的程式設計和計算處理。
MapReduce原理(執行機制)
圖一
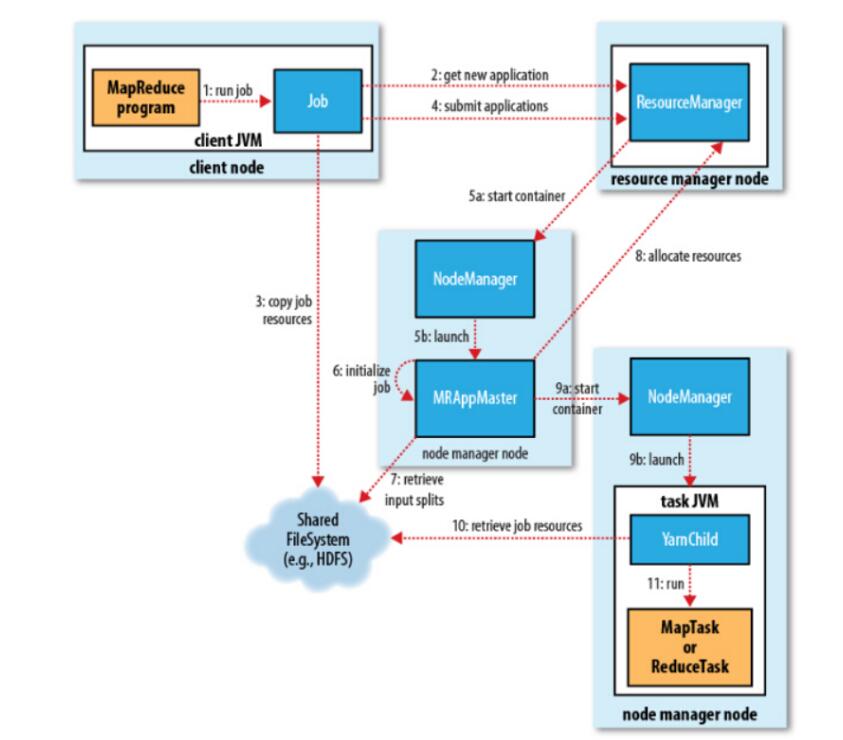
主要執行五步驟
1、向client端提交MapReduce job.
2、隨後yarn的ResourceManager進行資源的分配.
3、由NodeManager進行載入與監控containers.
4、通過applicationMaster
5、通過hdfs進行job配置檔案、jar包的各節點分發。
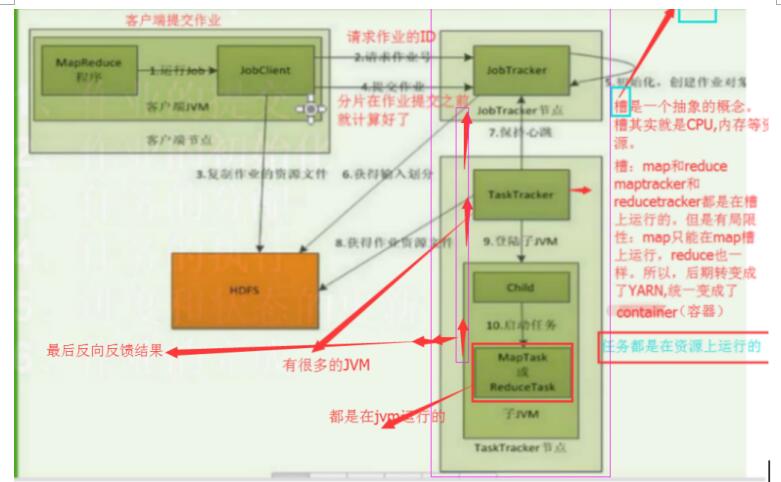
Job 提交過程
job的提交通過呼叫submit()方法建立一個JobSubmitter例項,並呼叫submitJobInternal()方法。整個job的執行過程如下:
1、向ResourceManager申請application ID,此ID為該MapReduce的jobId。
2、檢查output的路徑是否正確,是否已經被建立。
3、計算input的splits。
4、拷貝執行job 需要的jar包、配置檔案以及計算
5、在ResourceManager中呼叫submitAppliction()方法,執行job
Job 初始化過程
1、當resourceManager收到了submitApplication()方法的呼叫通知後,scheduler開始分配container,隨之ResouceManager傳送applicationMaster程序,告知每個nodeManager管理器。
2、由applicationMaster決定如何執行tasks,如果job資料量比較小,applicationMaster便選擇將tasks執行在一個JVM中。那麼如何判別這個job是大是小呢?當一個job的mappers數量小於10個,只有一個reducer或者讀取的檔案大小要小於一個HDFS block時,
(可通過修改配置項
mapreduce.job.ubertask.maxmaps,mapreduce.job.ubertask.maxreduces以及
mapreduce.job.ubertask.maxbytes 進行調整)
3、在執行tasks之前,applicationMaster將會呼叫setupJob()方法,隨之建立output的輸出路徑(這就能夠解釋,不管你的mapreduce一開始是否報錯,輸出路徑都會建立)
Task 任務分配
1、接下來applicationMaster向ResourceManager請求containers用於執行map與reduce的tasks(step 8),這裡map task的優先順序要高於reduce task,當所有的map tasks結束後,隨之進行sort(這裡是shuffle過程後面再說),最後進行reduce task的開始。(這裡有一點,當map tasks執行了百分之5%的時候,將會請求reduce,具體下面再總結)
2、執行tasks的是需要消耗記憶體與CPU資源的,預設情況下,map和reduce的task資源分配為1024MB與一個核,(可修改執行的最小與最大引數配置,mapreduce.map.memory.mb,mapreduce.reduce.memory.mb,mapreduce.map.cpu.vcores,mapreduce.reduce.reduce.cpu.vcores.)
Task 任務執行
1、這時一個task已經被ResourceManager分配到一個container中,由applicationMaster告知nodemanager啟動container,這個task將會被一個主函式為YarnChild的java application執行,但在執行task之前,首先定位task需要的jar包、配置檔案以及載入在快取中的檔案。
2、YarnChild運行於一個專屬的JVM中,所以任何一個map或reduce任務出現問題,都不會影響整個nodemanager的crash或者hang。
3、每個task都可以在相同的JVM task中完成,隨之將完成的處理資料寫入臨時檔案中。
Mapreduce資料流
執行進度與狀態更新
1、MapReduce是一個較長執行時間的批處理過程,可以是一小時、幾小時甚至幾天,那麼Job的執行狀態監控就非常重要。每個job以及每個task都有一個包含job(running,successfully completed,failed)的狀態,以及value的計數器,狀態資訊及描述資訊(描述資訊一般都是在程式碼中加的列印資訊),那麼,這些資訊是如何與客戶端進行通訊的呢?
2、當一個task開始執行,它將會保持執行記錄,記錄task完成的比例,對於map的任務,將會記錄其執行的百分比,對於reduce來說可能複雜點,但系統依舊會估計reduce的完成比例。當一個map或reduce任務執行時,子程序會持續每三秒鐘與applicationMaster進行互動。
Job 完成
最終,applicationMaster會收到一個job完成的通知,隨後改變job的狀態為successful。最終,applicationMaster與task containers被清空。
圖二
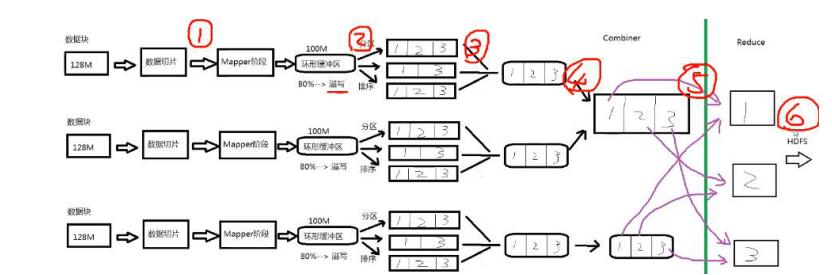
Combiner 是對mapper輸出結果進行區域性的彙總,reducer是對mapper輸出結果進行全域性的彙總。
Partitioner是map階段
資料分片處理好之後,要經過map階段的partitioner進行分割槽,來選擇不同的reduce進行處理資料。
圖三
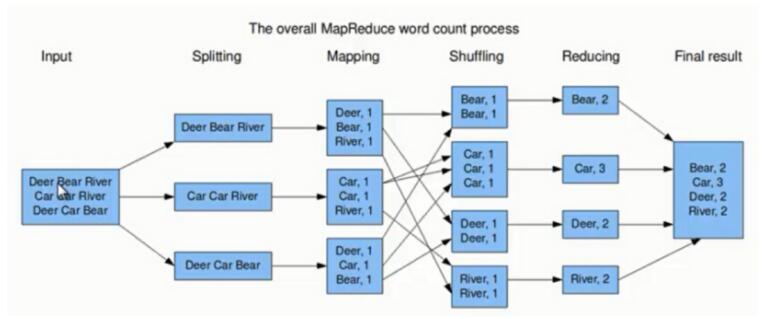
第一步:假設一個檔案有三行英文單詞作為 MapReduce 的Input(輸入),這裡經過 Splitting 過程把檔案分割為3塊。分割後的3塊資料就可以並行處理,每一塊交給一個 map 執行緒處理。
第二步:每個 map 執行緒中,以每個單詞為key,以1作為詞頻數value,然後輸出。
第三步:每個 map 的輸出要經過 shuffling(混洗),將相同的單詞key放在一個桶裡面,然後交給 reduce 處理。
第四步:reduce 接受到 shuffling 後的資料,會將相同的單詞進行合併(Merge),得到每個單詞的詞頻數,最後將統計好的每個單詞的詞頻數作為輸出結果
上述就是 MapReduce 的大致流程,前兩步可以看做 map 階段,後兩步可以看做 reduce 階段。
圖四
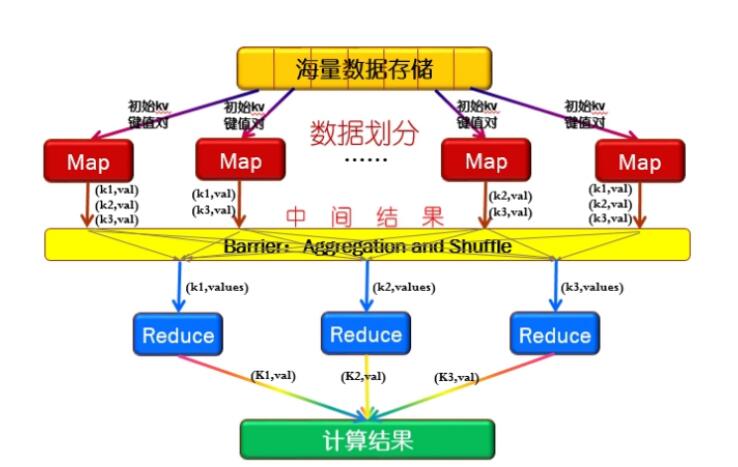
1)首先文件的資料記錄(如文字中的行,或資料表格中的行)是以“鍵值對”的形式傳入map 函式,然後map函式對這些鍵值對進行處理(如統計詞頻),然後輸出到中間結果。
2)在鍵值對進入reduce進行處理之前,必須等到所有的map函式都做完,所以既為了達到這種同步又提高執行效率,在mapreduce中間的過程引入了barrier(同步障)
在負責同步的同時完成對map的中間結果的統計,包括:
a. 對同一個map節點的相同key的value值進行合併。
b. 之後將來自不同map的具有相同的key的鍵值對送到同一個reduce進行處理。
3)在reduce階段,每個reduce節點得到的是從所有map節點傳過來的具有相同的key的鍵值對。reduce節點對這些鍵值進行合併。
圖五

這圖五是圖四的進一步細化,主要體現在:
1)Combiner 節點負責完成上面提到的將同一個map中相同的key進行合併,避免重複傳輸,從而減少傳輸中的通訊開銷。
2)Partitioner節點負責將map產生的中間結果進行劃分,確保相同的key到達同一個reduce節點.
圖六
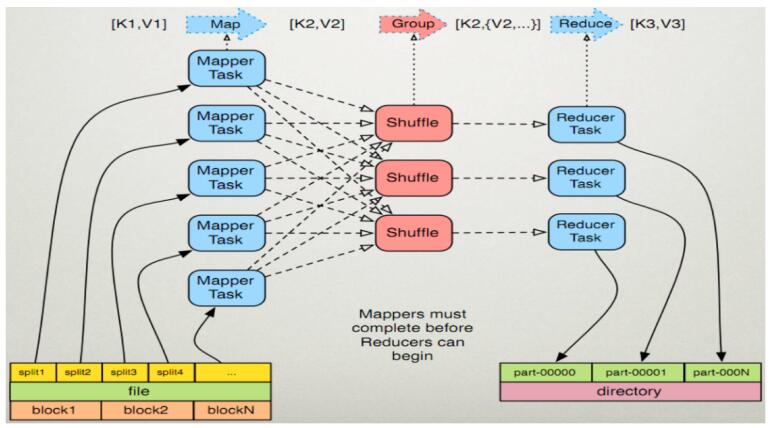
MapReduce的執行步驟
1、Map任務處理
1.1 讀取HDFS中的檔案。每一行解析成一個<k,v>。
每一個鍵值對呼叫一次map函式。
<0,hello you> <10,hello me>
1.2 覆蓋map(),接收1.1產生的<k,v>,進行處理,轉換為新的<k,v>輸出。
<hello,1> <you,1> <hello,1> <me,1>
1.3 對1.2輸出的<k,v>進行分割槽。預設分為一個區。
詳見:partitioner
1.4 對不同分割槽中的資料進行排序(按照k)、分組。分組指的是相同key的value放到一個集合中。
排序後:<hello,1> <hello,1> <me,1> <you,1>
分組後:<hello,{1,1}><me,{1}><you,{1}>
1.5 (可選)對分組後的資料進行歸約。
詳見:Combiner
2、Reduce任務處理
2.1 多個map任務的輸出,按照不同的分割槽,通過網路copy到不同的reduce節點上。(shuffle)
詳見:shuffle的過程分析
2.2 對多個map的輸出進行合併、排序。
覆蓋reduce函式,接收的是分組後的資料,實現自己的業務邏輯, <hello,2> <me,1> <you,1>
處理後,產生新的<k,v>輸出。
2.3 對reduce輸出的<k,v>寫到HDFS中。