
pycharm 中 import requests 報錯
使用Pycharm來抓取網頁的時候,要匯入requests模組,但是在pycharm中 import requests 報錯。
原因: python中還沒有安裝requests庫
解決辦法:
1.先找到自己python安裝目錄下的pip

2.在自己的電腦裡開啟cmd視窗。先點選開始欄,在搜尋欄輸入cmd,按Enter,打開啟cmd視窗。在cmd裡將目錄切換到你的pip所在路徑。比如我的在C:\Python27\Scripts這個目錄下,先切換到d盤,再進入這個路徑。具體命令:cd..回車cd..回車到C盤,然後cd空格C:\Python27\Scripts回車,這樣就進入到了pip路徑裡面。
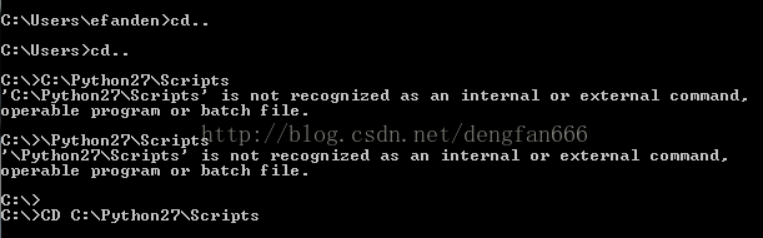
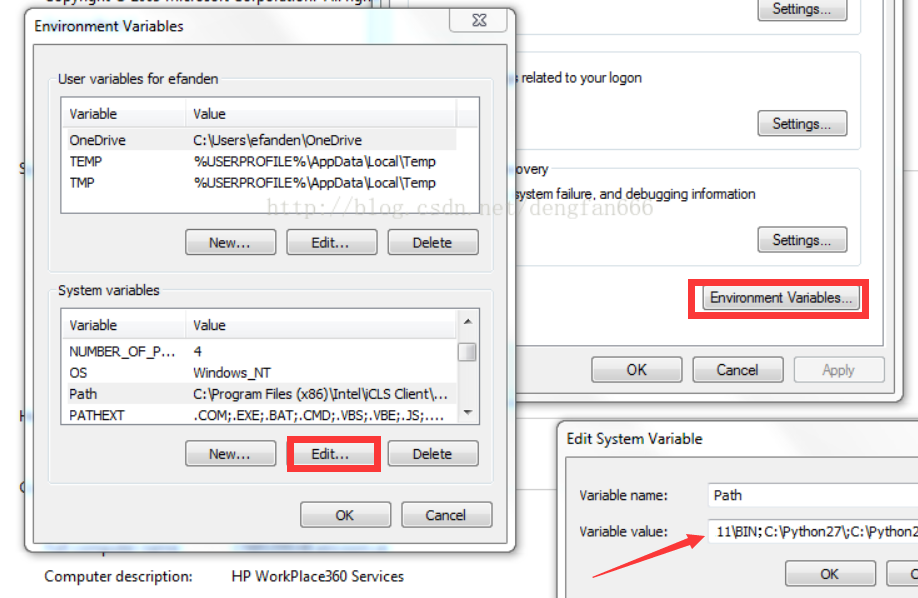
3. 這個時候卻發現cmd命令列出現了一堆紅字,安裝時候報錯,原因是C:\Python27\Scripts這個路徑沒有配置到PATH環境變數中。下面我們來配置環境變數。
依次點選我的電腦,Properties,接著點選高階系統設定,環境變數,然後把C:\Python27\Scripts路徑新增到變數值裡面就行了。
4. 接著再輸入命令pip install requests 執行安裝,等待他安裝完成就可以了。

5. 這樣再把requests庫import進來就不會報錯了。
相關推薦
pycharm 中 import requests 報錯
使用Pycharm來抓取網頁的時候,要匯入requests模組,但是在pycharm中 import requests 報錯。 原因: python中還沒有安裝requests庫 解決辦法: 1.先找到自己python安裝目錄下的pip 2.在自
tf 在pycharm 中運行報錯的解決
分享圖片 pri apple wikipedia 處理器 har 解釋器 .org get 安裝完Tensorflow 後,在Pychram中添加 解釋器之後,運行“hello,tensorflow!”測試程序,雖能運行 輸出‘ hello,tensorflow! ’, 但
jupyter中import tensorflow報錯
終端source activate tensorflow-gpu啟用tensorflow環境後,開啟jupyter notebook,依舊報錯: 可能的原因:因為在tensorflow-gpu環境中沒有安裝jupyter和ipython,檢查方法: which ipython whic
解決在Jupyter中import tensorflow報錯
1.讓jupyter識別到tensorflow /usr/local/lib/python2.7/dist-packages/ 要想在Jupyter中使用到這些模組,就需要在Anaconda中指定這些模組的地址。我的Anaconda安裝路徑為: /
pycharm中from xx import xx報錯:Unresolved reference
res 錯誤 ces 紅色 alt simple pyc 工程 wid 在引入 from simpleDemo import * 時候,發現simpleDemo 會有下滑紅色波浪線的錯誤提示 原因:import不成功是路徑沒對應上,pycharm默認該項目的根目錄為sou
pycharm中import報錯 命令列import正常
一、問題起源:在pycharm中的import會找不到,在命令列中import可以找到二、原因:可能是自己電腦中安裝了多個python環境。比如我的電腦中的cassandra安裝在了位置A,而pycha
python中呼叫 imread 報錯: ImportError: cannot import name imread
在使用Python載入影象時需要使用imread命令,但是: from scipy.misc import imread,imresize時提示 cannot import name imread
解決pycharm 執行 from selenium import webdriver報錯問題
#coding=utf-8from selenium import webdriverfrom selenium.webdriver.firefox.firefox_binary import FirefoxBinary#binary = FirefoxBinary('/pa
JS 調試中常見的報錯的解決辦法
是否 asp success ted json字符串 clas 使用 crud 識別 報錯:Uncaught SyntaxError: Unexpected token o in JSON at position 1 at JSON.parse (<anonymou
scrapy import CrawlSpider 報錯
imp esp 一個 spider wls spi ide 一個個 module from scrapy.spider import CrawlSpider 報錯 import module CrawlSpider error 看了下以前一直用的scrapy0.14.1 使
from lxml import etree 報錯
bsp get cal failed nbsp blog str XML python python 3.6 通過pip install 方式在線安裝lxml pip install lxml from lxml import etree 報錯 1 Traceback
傳參時Url中有中文報錯
head 無效 解釋 content uri 就會 invalid ins character url中如果傳了中文,瀏覽器會報錯:The header content contains invalid characters。 原因:瀏覽器自動把這個url進行decodeU
linux下python,import cv2報錯no module named cv2
ont 如果 spa module size pip3 pen 報錯 install 配置情況:anaconda2,anaconda3都有裝 打開python,看是哪個版本 如果是anaconda2:pip install opencv-python(試過pip insta
項目中訪問controller報錯:HTTP Status 500 - Servlet.init() for servlet spring threw exception
apr ssl .get beans index p s 配置 cnblogs lis 直接訪問controller路徑http://localhost:8080/index報錯: HTTP Status 500 - Servlet.init() for servlet
vue1.0中$index一直報錯的解決辦法
script 問題 pos 報錯 ssm targe 分享 解決 for 原文鏈接:https://www.cnblogs.com/liqiong-web/p/8144925.html 看學習視頻,因為年份比較早了,其實vue早已叠代到vue2.0了,遇到一些問題: v-f
Docker中啟動mysql報錯: Failed to get D-Bus connection
-- oop 鏡像文件 com port oot roo 生成 systemctl docker版本:[root@localhost ~]# docker versionClient: Version: 1.10.3 API version: 1.2
模擬javaweb項目中的相似報錯
模擬 java nat ray com div arraycopy bis exce BufferedInputStream bis = new BufferedInputStream(new FileInputStream("shabi.mp3")); Buffered
python已寫內容中可能的報錯及解決辦法
blog cas bin sci any nta enc int onerror 理論上我發的每個短文,直接復制放到py裏面,python xx.py是可以執行的,不過因為版本,編碼什麽的問題會有報錯,詳見這裏 報錯: SyntaxError: Non-ASCII char
c#.net中引入ConfigurationManager報錯
文件 管理 錯誤 圖片 com reference clas http 技術分享 頭文件添加了using System.Configuration後,還要添加對它dll的引用references,我的文件位置在C:\Windows\Microsoft.NET\Framewo
Maven項目中java類報錯-Cannot resolve symbol
start mbo resolve 解決 gpo 沒有 file sym art 電腦藍屏了,強制重啟之後再打開IDEA裏面的項目,所有Java類文件都在報Cannot resolve symbo錯誤,可以確定所有依賴的包都有引用且jar包沒有沖突。 經