
計算機視覺領域不同的方向:目標識別、目標檢測、語義分割等
計算機視覺任務:
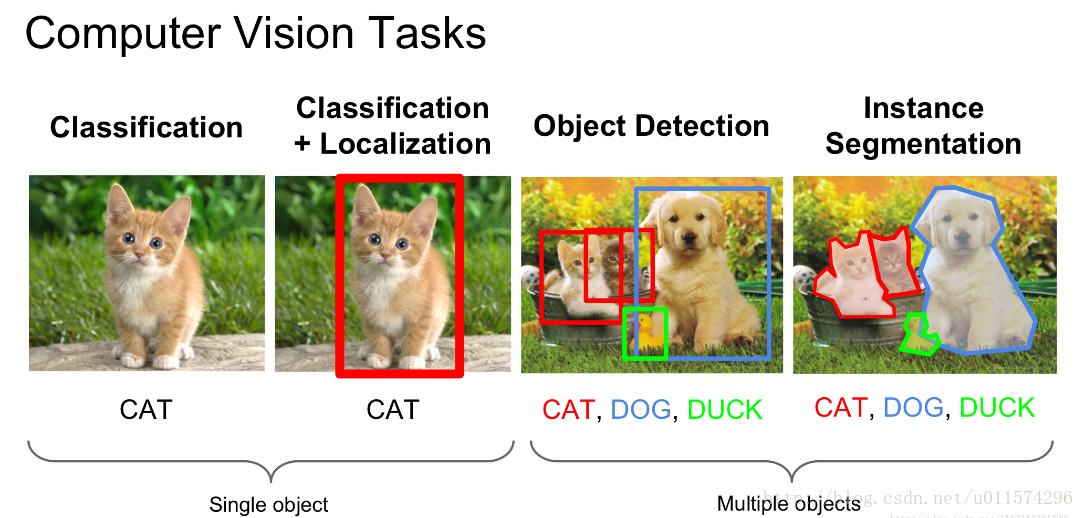
影象分類(image classification)
影象分類:根據影象的主要內容進行分類。
資料集:MNIST, CIFAR, ImageNet
目標檢測(object detection)
給定一幅影象,只需要找到一類目標所在的矩形框
人臉檢測:人臉為目標,框出一幅圖片中所有人臉所在的位置,背景為非目標
汽車檢測:汽車為目標、框出一幅圖片中所有汽車所在的位置,背景為非目標
資料集:PASCAL, COCO
目標識別(object recognition)
將需要識別的目標,和資料庫中的某個樣例對應起來,完成識別功能
人臉識別:人臉檢測,得到的人臉,再和資料庫中的某個樣例對應起來,進行識別,得到人臉的具體資訊
資料集:PASCAL, COCO
語義分割(semantic segmentation)
對影象中的每個畫素都劃分出對應的類別,即對一幅影象實現畫素級別的分類

資料集:PASCAL, COCO
例項分割(instance segmentation)
對影象中的每個畫素都劃分出對應的類別,即實現畫素級別的分類,類的具體物件,即為例項,那麼例項分割不但要進行畫素級別的分類,還需在具體的類別基礎上區別開不同的例項。
比如說影象有多個人甲、乙、丙,那邊他們的語義分割結果都是人,而例項分割結果卻是不同的物件,具體如下圖(依次為:原圖 ,語義分割 ,例項分割):

資料集:PASCAL, COCO
通俗的講解如此下:
影象分類
如果你開始瞭解深度學習的影象處理, 你接觸的第一個任務一定是影象識別 :比如把你的愛貓輸入到一個普通的CNN網路裡, 看看它是喵咪還是狗狗。
一個最普通的CNN, 比如像這樣幾層的CNN鼻祖Lenet, 如果你有不錯的資料集(比如kaggle貓狗大戰)都可以給出一個還差強人意的分類結果(80%多準確率), 雖然不是太高。
分類問題做就了還真是挺無聊的。我們進化的方向,也就是用更高階的網路結構取得更好的準確率,比如像下圖這樣的殘差網路(已經可以在貓狗資料集上達到99.5%以上準確率)。分類做好了你會有一種成為深度學習大師,拿著一把斧子眼鏡裡都是釘子的幻覺。 分類問題之所以簡單, 一要歸功於大量標記的影象, 二是分類是一個邊界非常分明的問題, 即使機器不知道什麼是貓什麼是狗, 看出點區別還是挺容易的, 如果你給機器幾千幾萬類區分, 機器的能力通過就下降了(再複雜的網路,在imagenet那樣分1000個類的問題裡,都很難搞到超過80%的準確率)。
物體檢測
很快你發現,分類的技能在大部分的現實生活裡並沒有鳥用。因為現實中的任務啊, 往往是這樣的:

或者這樣的:

那麼多東西在一起,你拿貓狗大頭照訓練的分類網路一下子就亂了陣腳。 現實中, 哪有那麼多圖片, 一個圖裡就是一個貓或者美女的大圖,更多的時候, 一張圖片裡的東西, 那是多多的, 亂亂的,沒有什麼章法可言的, 你需要自己做一個框, 把你所需要看的目標給框出來, 然後, 看看這些東西是什麼 。於是你來到機器視覺的下一層挑戰 - 目標檢測(從大圖中框出目標物體並識別), 隨之而來的是一個新的網路架構, 又被稱為R - CNN, 圖片檢測網路 , 這個網路不僅可以告訴你分類,還可以告訴你目標物體的座標, 即使圖片裡有很多目標物體, 也一一給你找出來。
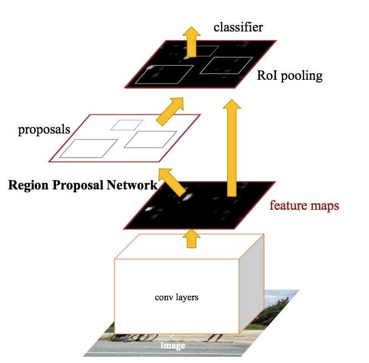
在眾多路人甲中識別嫌疑犯,也是輕而易舉, 安防的人聽著要按捺不住了。今年出現的YOLO演算法更是實現了快速實時的物體檢測,你一路走過就告訴你視線裡都有什麼在哪裡,要知道這在無人駕駛裡是何等的利器。

當然, 到這裡你依然最終會覺得無聊, 即使網路可以已經很複雜, 不過是一個CNN網路(推薦區域),在加上一層CNN網路做分類和迴歸。 能不能幹點別的?
影象切割
這就來到了第三個關卡, 你不僅需要把圖片中邊邊角角的物體給檢測出來, 你還要做這麼一個猛料的工作, 就是把它從圖片中扣出來。 要知道, 剛出生的嬰兒分不清物體的邊界, 比如桌上有蘋果這種事, 什麼是桌子,什麼是蘋果? 所以, 網路能不能把物體從一個圖裡摳出來, 事關它是否真的像人一樣把握了視覺的本質。而把這個問題簡化,我們無非是在原先圖片上生成出一個原圖的“mask”,有點像phtoshop裡的蒙版的東西。
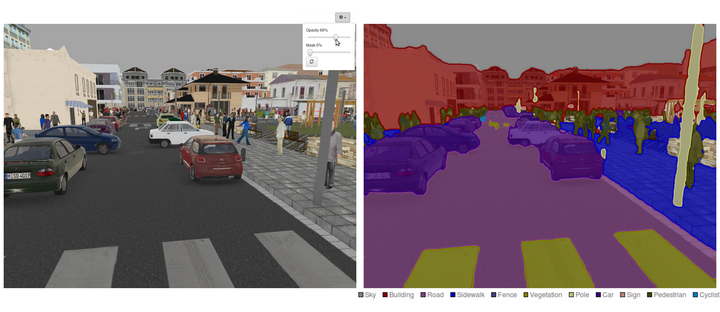
這個任務裡,我們是要從一個圖片裡得到另一個圖片哦! 生成的面具是另一個圖片, 這時候,所謂的U型網路粉墨登場,注意這是我們的第一個生成式的模型。 它的組成單元依然是卷積,但是卻加入了maxpooling的反過程升維取樣。這個Segmentation任務, 作用不可小瞧哦, 尤其對於科研口的你, 比如現在私人衛星和無人機普及了,要不要去看看自己小區周圍的地貌, 看是不是隱藏了個金庫? 清清輸入, 衛星圖片一欄無餘。 哪裡有樹, 哪裡有水,哪裡有軍事基地,不需要人,全都給你摳出來。

以圖搜圖
我們開始fashion起來, 如果你是淘寶服裝小店的老闆 ,想讓客戶輸入一張服裝的圖片,然後得到一組推薦的服裝, 來個以圖搜圖的功能怎麼搞呢? 注意啊,我可以從網路上爬一大堆圖出來,但是這些資料是沒有標註的。怎麼辦? 鐵哥告你還是有的搞,這個搞法,就是聚類。鐵哥教你最簡單的一招聚類哦,那就是, 把圖片統統放進卷積網路,但是我們不提取分類,而只是提取一些網路中間層的特徵, 這些特徵有點像每個圖片的視覺二維碼,然後我們對這些二維碼做一個k-means聚類, 也會得到意想不到的效果。 為什麼要深度? 因為深度提取的特徵,那是與眾不同的。然後以圖搜圖呢? 不過是找到同一聚類裡的其它圖片啊。
在聚類的基礎上, 就可以做個搜尋!

影象生成
我們開始晉升為仰望星空的人, 之前那些分類賺錢的應用太無聊了。 機器視覺搞科學怎麼港? 作為一群仰望星空後觀察細胞的人,我們最常發現的是我們得到的天文或者細胞圖片的噪聲實在太大了, 這簡直沒法忍啊, 然後, 深度學習給了你一套降噪和恢復影象的方法。
一個叫auto-encoder的工具, 起到了很大的作用 , 刷的一下,影象就清楚了。

這還不是最酷炫的,那個應用了博弈理論的對抗學習, 也可以幫你謀殺噪點! 如果你會對抗所謂GAN, 也是一種影象生成的工具, 讓網路去掉噪聲的圖片,與沒有噪聲的自然圖片, 連卷積網路都判別不出來,對, 就是這樣!
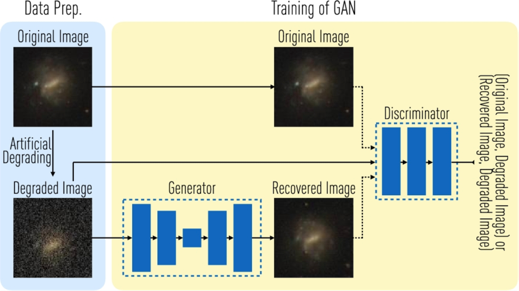

Schawinski, Kevin, et al. “Generative adversarial networks recover features in astrophysical images of galaxies beyond the deconvolution limit.” Monthly Notices of the Royal Astronomical Society: Letters 467.1 (2017): L110-L114.