
Top-N Recommendation——基於電影(Item)的推薦
注:
1. 資料集來源MovieLens
2. 原始碼在末尾附上
一、Introduction
無論是在實體商店還是在網路上,都會有Top-N推薦的情況。基於客戶或者基於商品做出推薦。本實驗基於Movielens的電影資料集,對電影做出Top-N 推薦。主要目的是基於Item-Based的思想來進行Top-10的相關電影推薦。
二、Methodology
本實驗基於Item-Based 的思路,計算電影的相似度,對每部電影都生成一個它與其他電影的相似度的序列(按順序排列),然後從中得到Top-10的電影來作為該部電影的相關推薦電影集。在MovieLens中的資料格式如下:
1::Toy Story (1995)::Animation|Children's|Comedy
1:表示電影ID; Toy Story(1995)表示電影名 ;Animation|Children’s|Comedy :表示標籤
因此可以用一個向量表來表示該電影的資訊:
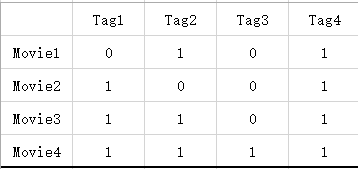
附註: 0 表示電影沒有該標籤 , 1 表示電影有該標籤
對每一部電影,計算它與其他電影的相似度,生成一個相似度的有序序列。N部電影生成N個有序序列,因此對每一部電影都有一個單獨的推薦列表。
三、Trading Algorithm
Item-Based:
首先生成一個電影的資訊矩陣(N*M),然後對於每一個部電影,使用相似度計算的公式,將該電影與其餘N-1部電影做相似計算,然後再對相似度進行排序,推薦前Top-10的電影。相似度:
公式:
本實驗採用的是Cosine相似度:
- 原理:多維空間兩點與所設定的點形成夾角的餘弦值。
- 範圍:【-1,1】,值越大,說明夾角越小,兩點相距越近,相似度就越高。
- 說明:Cosine相似度被廣泛應用於計算文件的資料的相似度,本實驗是基於標籤的電影推薦,因此採用了該公式來計算兩個電影之間標籤集的相似度,以此來代表兩部電影的相似度。
TF-IDF演算法(計算某個標籤對於該電影的權重)
由於MovieLens裡面的Movie資料只給出了電影的標籤(如下),但是並沒有給出該標籤使用者的點選量,因此無法對該標籤在本電影中的權重進行計算。因此,本實驗沒有用TF-IDF計算詞頻,確定標籤權重的步驟。
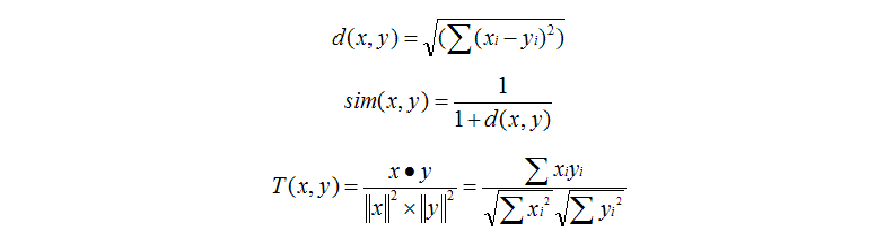
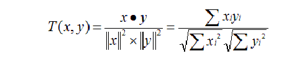
四、Result
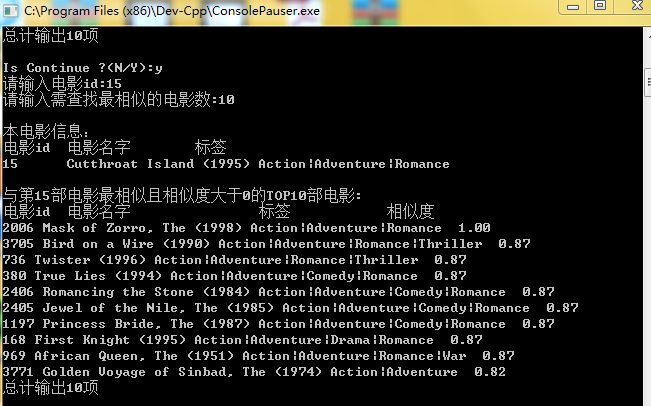
為了驗證結果,將電影的資訊和相似度打印出來。
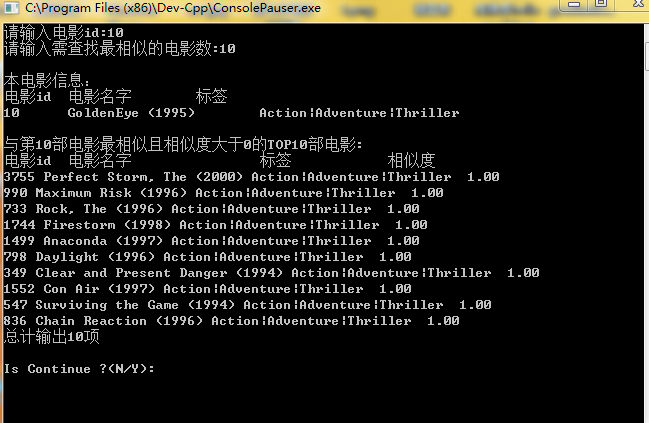
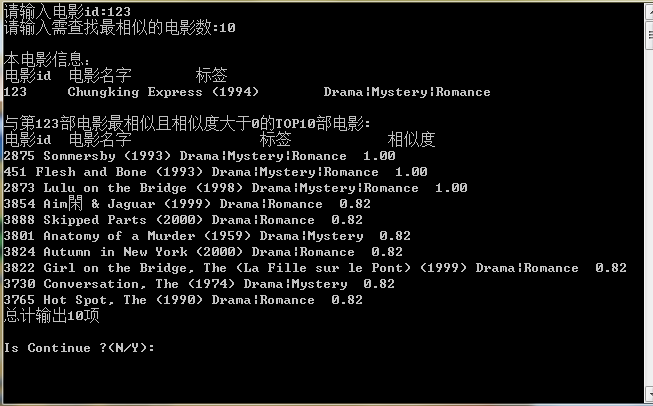
在這裡我們隨機選取了三部電影,將其電影的Top-10推薦以及它的相似度打印出來,以便分析比較。
Movie1:
Movie2:
Movie3:
五、Conclusion
結果證明,對於每一部電影,都輸出了一個推薦序列,而且按照相似度排列的Top-N推薦。列如, 電影1:它的標籤是 Action|Adventrue|Romance ,在它的Top-10推薦列表中,按照相似度從大到小推薦。
- 本實驗存在一個問題:
有些電影其推薦列表的電影相似度全部都是1,,如電影2 GoldenEye ,其標籤為:Action|Adventure|Thiriller ,推薦列表中的電影標籤與其完全相同,這是不太符合實際的。 - 原因
主要問題在於MovieLens資料集中並沒有對每一個標籤的點選量進行說明,無法通過TF-IDF演算法計算標籤在電影中的權重,但是實際情況下,每一部電影的標籤都會有一個點選量,作為該標籤與該電影相關程度的反映。因此對於一部電影,它的某一個標籤的權重無法衡量,因此不能區分出某一個標籤在一部電影當中的權重,在計算的時候每一個標籤的權重都相同,導致了擁有相同標籤的電影其相似100%。 - 解決方案
每一部電影的標籤都會有一個點選量,通過IF-IDF演算法計算其權重,作為該標籤與該電影相關程度的反映。用以區分出某一個標籤在一部電影當中的權重,在計算的時候每一個標籤的權重各有不同,那麼便不會出現上述的問題。
總體來說,本實驗基於item-based思想,通過相似度計算,生成電影的top-N 推薦序列。雖然資料上存在一些問題,但是總體上還是完成了推薦的目的。