
Top-N Recommendation——基於使用者的推薦實驗
注:
1. 資料集來源 MovieLens
2. 原始碼在末尾附上
一、Introduction
大家無論是在實體商店還是在網路上,都會有Top-N推薦的情況。基於客戶或者基於商品做出推薦。本實驗基於Movielens、Ratings的電影資料集,對使用者做出Top-N 推薦。主要目的是基於User-Based的思想來進行Top-10的相關電影推薦。
二、Methodology
本實驗基於User-Based 的思路,首先通過Item-based計算電影的相似度,對每部電影都生成一個它與其他電影的相似度的序列(按順序排列),然後從中得到Top-10的電影來作為該部電影的相關推薦電影集。然後根據使用者歷史行為從Item-base中選出對應的電影序列,從而產生推薦的電影。
MovieLens中的資料格式如下:
1::Toy Story (1995)::Animation|Children's|Comedy
1:表示電影ID; Toy Story(1995)表示電影名 ;Animation|Children’s|Comedy :表示標籤
因此可以用一個向量表來表示該電影的資訊:
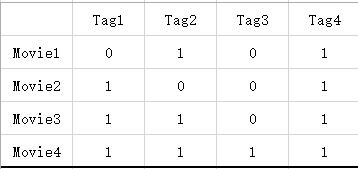
附註: 0 表示電影沒有該標籤 , 1 表示電影有該標籤
對每一部電影,計算它與其他電影的相似度,生成一個相似度的有序序列。N部電影生成N個有序序列,因此對每一部電影都有一個單獨的推薦列表。 如:
使用者歷史記錄為U{movie1,movie3,movie5};假設每一部電影的推薦項為10,那麼就有3*10=30部電影的推薦(其中可能包含重複的,將重複的電影剔除),然後再按照這些電影的相似度大小排序,選出10部電影推薦給該使用者。這樣就完成了針對使用者歷史行為的電影推薦。
三、Trading Algorithm
- Item-Based:
首先生成一個電影的資訊矩陣(N*M),然後對於每一個部電影,使用相似度計算的公式,將該電影與其餘N-1部電影做相似計算,然後再對相似度進行排序,推薦前Top-10的電影。 相似度:
公式:
本實驗採用的是Cosine相似度:
- 原理:多維空間兩點與所設定的點形成夾角的餘弦值。
- 範圍:【-1,1】,值越大,說明夾角越小,兩點相距越近,相似度就越高。
- 說明:Cosine相似度被廣泛應用於計算文件的資料的相似度,本實驗是基於標籤的電影推薦,因此採用了該公式來計算兩個電影之間標籤集的相似度,以此來代表兩部電影的相似度。
TF-IDF演算法(計算某個標籤對於該電影的權重)
由於MovieLens裡面的Movie資料只給出了電影的標籤(如下),但是並沒有給出該標籤使用者的點選量,因此無法對該標籤在本電影中的權重進行計算。因此,本實驗沒有用TF-IDF計算詞頻,確定標籤權重的步驟。User-based
每一個已有使用者都有一個歷史觀看記錄,根據歷史觀看記錄,來找出推薦的電影集。推薦的依據是Item-based思想產生的推薦序列,每一部電影都有一個推薦序列,如果使用者有User{movie1,movie2,……,movien} n個歷史觀看記錄,原則上說就應該對應著 N個推薦序列。將這N個推薦序列中重複的電影剔除,再按照從高到低的相似度排序,從中選出若干部電影推薦給使用者。這就是User-based演算法的思想。- 驗證精確度
為了驗證推薦的精確度,我們將已有的使用者瀏覽記錄分為兩部分,80%用來訓練,20%用來評估推薦演算法的精確度。
比如:根據使用者歷史行為(80%的訓練集),產生的推薦序列為 Rec{movie1,movie2,movie3,movie4…,movie10},然後,將剩下的的評估集打印出來,與推薦的電影比較,計算相似命中率(由於我們這裡是劃分集合評估,所以命中率指的是與推薦電影的相似度)。
注:結論部分有說明,採用相似命中率是因為訓練集與評估集的電影是互斥的,推薦的電影是根據訓練集作為歷史記錄,評估集作為檢測推薦演算法的精確度。推薦的電影(根據Item-based演算法)是從全部集合中選出來推薦的,評估電影只佔全部電影的20%,因此評估的效果並不是很好;其次,使用者*電影矩陣大小為6040*4000,但是給的評論資料才有100萬,因此Item-Based演算法的推薦序列本來就存在了誤差,故而影響到了User-based推薦序列的精確度。
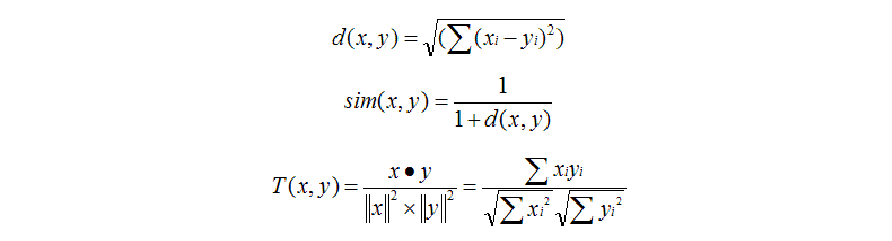
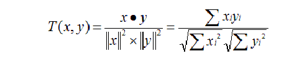
四、Result
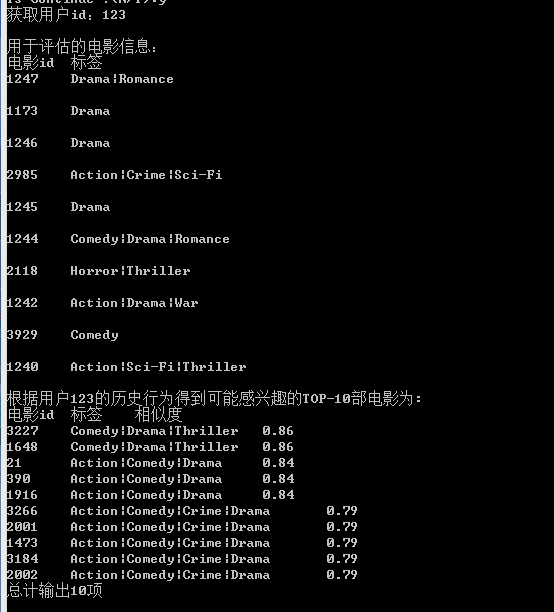
為了驗證結果,將推薦的電影序列打印出來,為了便於截圖,此處只給使用者推薦了10部電影。而且用於評估的電影,我們只選取了相似命中率最高(也就是在評估的電影集合中與推薦序列最吻合的那一部)的那一部電影來驗證相似命中率。
在這裡我們隨機選取了三部個使用者,將其電影的Top-10推薦以及它的相似度打印出來,以便分析比較。
User1:
User2:
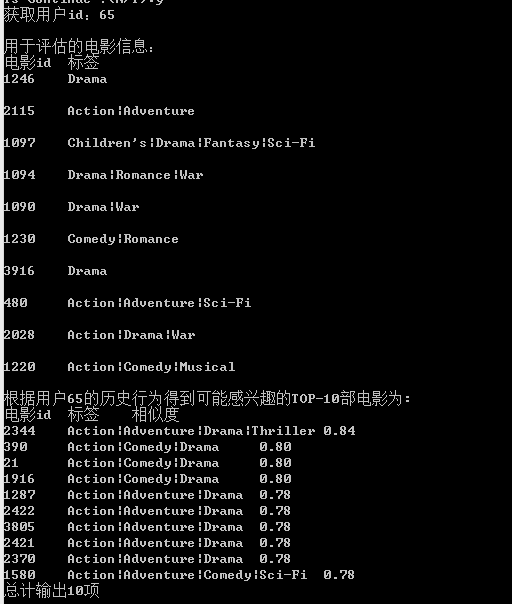
User3:

五、Conclusion
結果證明,對於每一個使用者,都輸出了一個推薦序列,而且按照相似度排列的Top-N推薦。列如, User3:用於評估推薦相似命中率的電影序列有10部,該使用者的T推薦列表也有10部,從結果來看相似命中率並不是很高。
- 存在的問題:命中率較低
- 問題分析與方案
- 第一,實驗的資料比較少,訓練集得到的模型並不可靠;
- 第二,本實驗評估的是使用者觀看的電影與推薦列表的電影的相似度,用於評估的電影是取使用者瀏覽資料的後20%資料,資料沒有隨機性;
- 第三,由於用於評估的電影與訓練集電影不同,因此評估的電影沒有重複性(也就是說,訓練集的電影在評估集中不能出現,所以評估的電影無法命中,故本實驗採用的是相似命中率通過標籤的相似度來評估推薦電影的準確率),所以實驗的精確度依賴於評估集合中電影的標籤與推薦電影標籤的相似度(與使用者行為相關度不是很大)。因此對於一個使用者,生成的推薦序列與評估電影序列,相似命中率不是很高。
總體來說,本實驗基於User-based思想,以前面的Item-based實驗資料的結果,通過相似度計算,生成針對於使用者的top-N 推薦序列。雖然資料上的準確度,但是總體上還是完成了推薦的目的。