
Pytorch入門:資料的載入與處理
0. 寫在前面
在深度學習的問題中處理資料都會佔據比較大的時間,只有把資料處理好了才有可能對模型進行訓練、測試等後續工作。
PyTorch提供了很多用於讓資料載入變得更加方便的工具,接下來我們就來學習一下怎麼樣處理那些PyTorch沒有提供直接介面的資料。
在學習這個之前,首先要保證電腦上已經安裝了下面這兩樣東西:
- scikit-image:用於影象輸入輸出和轉換
- pandas:用於更好的處理csv資料
這篇文章內容還是比較多的,但認真看完應該就可以掌握各種資料集的處理了。
1. 匯入需要庫
from __future__ import print_function, division
import 2. 資料集介紹及下載
2.1 資料集介紹
接下來我們要處理的資料集是關於臉部姿勢的,每張圖片都會被註釋成這樣,每張臉上都會有68各不同的標記點:

2.2 資料集下載與展示
-
戳這裡下載需要教程中用到的臉部資料集,跟資料集一起的還有一個註釋檔案
face_landmarks.csv。
直接開啟如下圖所示:
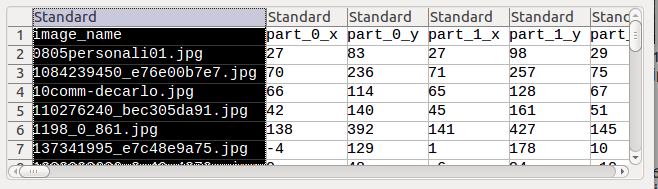
即每張圖片都對應一個檔名和對應的N個臉部特徵標記點。 -
在註釋檔案中的是N個座標點,每個座標點由兩個橫縱座標組成。所以先用pandas工具把註釋檔案處理一下。
landmarks_frame = pd.read_csv('faces/face_landmarks.csv')
n = 得到的結果為:

3.將影象和對應的特徵點標記出來展示。
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
plt.pause(0.001) # pause a bit so that plots are updated
plt.figure()
show_landmarks(io.imread(os.path.join('faces/', img_name)),
landmarks)
plt.show()
得到的結果為:

3. Dataset類介紹
3.1 原理介紹
torch.utils.data.Dataset是一個PyTorch用來表示資料集的抽象類。我們用這個類來處理自己的資料集的時候必須繼承Dataset,然後重寫下面的函式:
- __len__: 使得len(dataset)返回資料集的大小;
- __getitem__:使得支援dataset[i]能夠返回第i個數據樣本這樣的下標操作。
3.2 建立臉部影象資料集
- 在類的
__init__函式中完成csv檔案的讀取工作; - 在類的
__getitem__函式中完成圖片的讀取工作。這樣是為了減小記憶體開銷,只要在需要用到的時候才將圖片讀入。 - 除此,資料集還會接收一個可以選擇的引數
transform,用來對影象做一些改變,具體的會在下面進行介紹。 - 最終返回的樣本資料是一個字典形式的,如下所示:
{‘image':image,'landmarks':landmarks}
那麼現在我們就可以寫出類的定義:
class FaceLandmarksDataset(Dataset):
"""Face Landmarks dataset."""
def __init__(self, csv_file, root_dir, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
3.3 例項化類
接下來我們對上面定義好的類做例項化,然後在資料樣本上進行迭代。我們會列印前4個樣本影象及其對應的座標點。
face_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',
root_dir='faces/')
fig = plt.figure()
for i in range(len(face_dataset)):
sample = face_dataset[i]
print(i, sample['image'].shape, sample['landmarks'].shape)
ax = plt.subplot(1, 4, i + 1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample)
if i == 3:
plt.show()
break
結果如下所示:

4. Transforms
從上面顯示的圖片我們可以看到每張圖片的大小都不一樣,但往往我們在處理神經網路的輸入影象的時候都希望它們有一個相對固定的大小。因此,我們需要一些對影象進行預處理的工作。
4.1 實現常用變換功能
我們試著寫一下這三個常用的變換功能:
Rescale:重新調整影象大小;RandomCrop:隨機從影象中擷取一部分;ToTensor:將numpy型別表示的影象轉換成torch表示的影象。
我們用類而不是函式來實現以上這三個功能,主要是考慮到如果用函式的話,每次都需要傳入引數,但是用類就可以省掉很多麻煩。我們只需要實現每個類的__call__函式和__init__函式。
下面是對這三個功能的實現:
class Rescale(object):
"""Rescale the image in a sample to a given size.
Args:
output_size (tuple or int): Desired output size. If tuple, output is
matched to output_size. If int, smaller of image edges is matched
to output_size keeping aspect ratio the same.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
if isinstance(self.output_size, int):
if h > w:
new_h, new_w = self.output_size * h / w, self.output_size
else:
new_h, new_w = self.output_size, self.output_size * w / h
else:
new_h, new_w = self.output_size
new_h, new_w = int(new_h), int(new_w)
img = transform.resize(image, (new_h, new_w))
# h and w are swapped for landmarks because for images,
# x and y axes are axis 1 and 0 respectively
landmarks = landmarks * [new_w / w, new_h / h]
return {'image': img, 'landmarks': landmarks}
class RandomCrop(object):
"""Crop randomly the image in a sample.
Args:
output_size (tuple or int): Desired output size. If int, square crop
is made.
"""
def __init__(self, output_size):
assert isinstance(output_size, (int, tuple))
if isinstance(output_size, int):
self.output_size = (output_size, output_size)
else:
assert len(output_size) == 2
self.output_size = output_size
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
new_h, new_w = self.output_size
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
image = image[top: top + new_h,
left: left + new_w]
landmarks = landmarks - [left, top]
return {'image': image, 'landmarks': landmarks}
class ToTensor(object):
"""Convert ndarrays in sample to Tensors."""
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
# swap color axis because
# numpy image: H x W x C
# torch image: C X H X W
image = image.transpose((2, 0, 1))
return {'image': torch.from_numpy(image),
'landmarks': torch.from_numpy(landmarks)}
4.2 組合以上變換功能
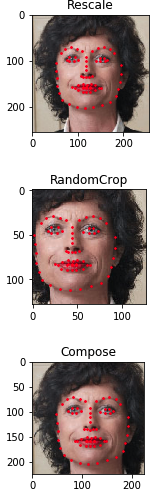
假設我們現在需要將影象的較短邊調整到256,然後從中隨機擷取224的正方形影象。我們就可以呼叫torchvision.transforms.Compose將以上的Rescale和RandomCrop兩個變換組合起來。
以下的程式碼段展示了分開進行變換以及用Compose組合進行變換的結果圖
scale = Rescale(256)
crop = RandomCrop(128)
composed = transforms.Compose([Rescale(256),
RandomCrop(224)])
# Apply each of the above transforms on sample.
fig = plt.figure()
sample = face_dataset[65]
for i, tsfrm in enumerate([scale, crop, composed]):
transformed_sample = tsfrm(sample)
ax = plt.subplot(1, 3, i + 1)
plt.tight_layout()
ax.set_title(type(tsfrm).__name__)
show_landmarks(**transformed_sample)
plt.show()
5. 合併dataset與transform、遍歷資料集
簡單回顧一下:
- 第3小節我們介紹了
dataset類; - 第4小節我們我們介紹了怎麼樣實現各個轉換函式,然後將其組合起來。
如果你還記得的話,我們在之前定義dataset的時候是有一個transform引數的,但我們在第4節中是先取了樣本資料,然後再進行變換操作,並沒有將其作為引數傳到dataset中。所以我們現在要做的工作就是將所有的內容整合到一起。每次抽取一個樣本,都會有以下步驟:
- 從檔案中讀取圖片;
- 將轉換應用於讀入的圖片;
- 由於做了隨機選取的操作,所以起到了資料增強的效果。
其實我們只要把Transform的部分作為形參傳入dataset就可以了,其他的都不變。
然後用for迴圈來依次獲得資料集樣本。
transformed_dataset = FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',
root_dir='faces/',
transform=transforms.Compose([
Rescale(256),
RandomCrop(224),
ToTensor()
]))
for i in range(len(transformed_dataset)):
sample = transformed_dataset[i]
print(i, sample['image'].size(), sample['landmarks'].size())
if i == 3:
break
取到的四個資料樣本如下所示:

6. DataLoader類
以上我們已經實現了dataset與transform的合併,也實現了用for迴圈來獲取每一個樣本資料,好像事情就已經結束了。
但等等,真的結束了嗎?emmmm,我們好像還落了什麼事情,是的沒錯:
- 按照batch_size獲得批量資料;
- 打亂資料順序;
- 用多執行緒multiprocessing來載入資料;
torch.utils.data.DataLoader這個類為我們解決了以上所有的問題,是不是很膩害~
只要按照要求設定DataLoader的引數即可:
- 第一個引數傳入transformed_dataset,即已經用了transform的Dataset例項。
- 第二個引數傳入batch_size,表示每個batch包含多少個數據。
- 第三個引數傳入shuffle,布林型變數,表示是否打亂。
- 第四個引數傳入num_workers表示使用幾個執行緒來載入資料。
如下所示即實現了DataLoader函式的使用,及批樣本資料的展示。
dataloader = DataLoader(transformed_dataset, batch_size=4,
shuffle=True, num_workers=4)
# Helper function to show a batch
def show_landmarks_batch(sample_batched):
"""Show image with landmarks for a batch of samples."""
images_batch, landmarks_batch = \
sample_batched['image'], sample_batched['landmarks']
batch_size = len(images_batch)
im_size = images_batch.size(2)
grid = utils.make_grid(images_batch)
plt.imshow(grid.numpy().transpose((1, 2, 0)))
for i in range(batch_size):
plt.scatter(landmarks_batch[i, :, 0].numpy() + i * im_size,
landmarks_batch[i, :, 1].numpy(),
s=10, marker='.', c='r')
plt.title('Batch from dataloader')
for i_batch, sample_batched in enumerate(dataloader):
print(i_batch, sample_batched['image'].size(),
sample_batched['landmarks'].size())
# observe 4th batch and stop.
if i_batch == 3:
plt.figure()
show_landmarks_batch(sample_batched)
plt.axis('off')
plt.ioff()
plt.show()
break
這樣呢其實就完成了對資料集完整的處理了。

7. torchvision
torchvision包提供了一些常用的資料集和轉換函式。使用torchvision甚至不需要自己寫處理函式。
在torchvision中最通用的資料集是ImageFolder,它假設資料結構為如下:
root/ants/xxx.png
root/ants/xxy.jpeg
root/ants/xxz.png
.
.
.
root/bees/123.jpg
root/bees/nsdf3.png
root/bees/asd932_.png
這裡的root指代根目錄,ants bees指的是不同的類標籤,後面的是具體的圖片名稱。
當然它還提供了對PIL.Image的常用操作,包括RandomHorizontalFlip Scale等等。
以下為用torchvision實現的超簡化版本的資料處理方法:
import torch
from torchvision import transforms, datasets
data_transform = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
hymenoptera_dataset = datasets.ImageFolder(root='hymenoptera_data/train',
transform=data_transform)
dataset_loader = torch.utils.data.DataLoader(hymenoptera_dataset,
batch_size=4, shuffle=True,
num_workers=4)
整理總結
我們來整理一下整個實現思路哦~
主要分以下三種情況:
1. 對於torchvision提供的資料集
- 這是最簡單的一種情況。
- 對於這一類資料集,就是PyTorch已經幫我們做好了所有的事情,連資料來源都不需要自己下載。
- Imagenet,CIFAR10,MNIST等等PyTorch都提供了資料載入的功能,所以可以先看看你要用的資料集是不是這種情況。
2. 對於特定結構的資料集
- 這種情況就是不在上述PyTorch提供資料庫之列,但是滿足下面的形式:
root/ants/xxx.png
root/ants/xxy.jpeg
root/ants/xxz.png
.
.
.
root/bees/123.jpg
root/bees/nsdf3.png
root/bees/asd932_.png
- 那麼就可以通過torchvision中的通用資料集ImageFolder來完成載入。
-具體使用方法見上文。
3. 對於最普通的資料集
- 最後一種情況是既不是自帶資料集,又不滿足ImageFolder,這種時候就自己進行處理。
- 首先,定義資料集的類(myDataset),這個類要繼承dataset這個抽象類,並實現__len__以及__getitem__這兩個函式,通常情況還包括初始函式__init__.
- 然後,實現用於特定影象預處理的功能,並封裝成類。當然常用的一些變換可以在torchvision中找到。用torchvision.transforms.Compose將它們進行組合成(transform)
- transform作為上面myDataset類的引數傳入,並得到例項化myDataset得到(transformed_dataset)物件。
- 最後,將transformed_dataset作為torch.utils.data.DataLoader類的形參,並根據需求設定自己是否需要打亂順序,批大小…
- 具體見上文。
參考資料
文章來源:
作者:與陽光共進早餐
連結:https://www.jianshu.com/p/6e22d21c84be
來源:簡書
簡書著作權歸作者所有,任何形式的轉載都請聯絡作者獲得授權並註明出處。