
新聞網站大數據項目
一、業務需求
?? (一)捕獲用戶瀏覽日誌信息
?? (二)實時分析前20名流量最高的新聞話題
?? (三)實時統計當前線上已曝光的新聞話題
?? (四)統計哪個時段用戶瀏覽量最高
二、系統架構
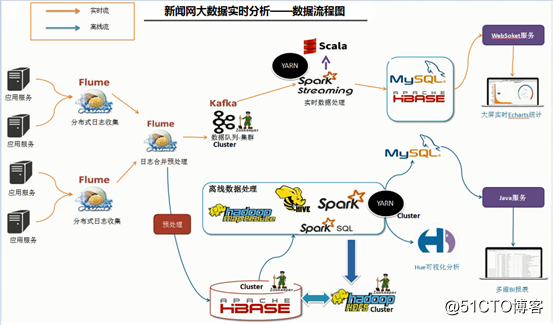
三、集群規劃
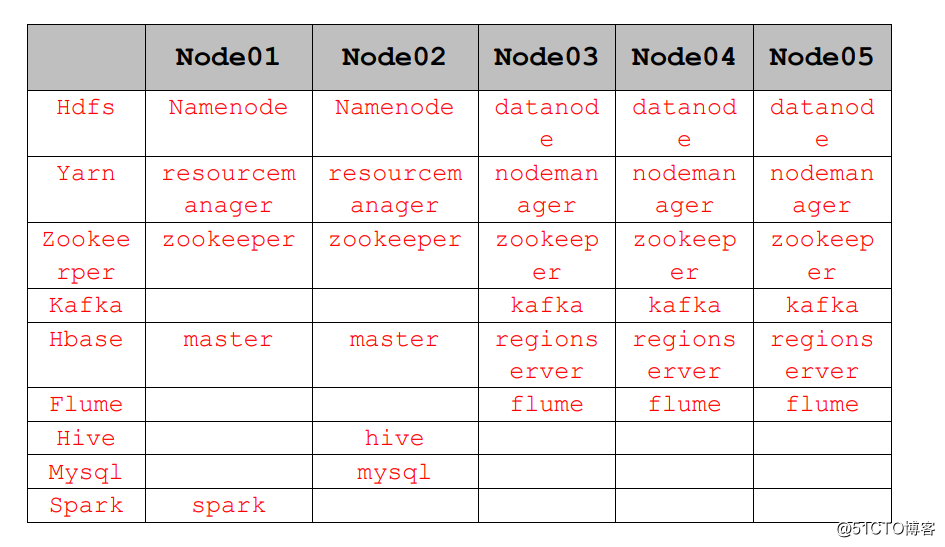
四、數據源介紹
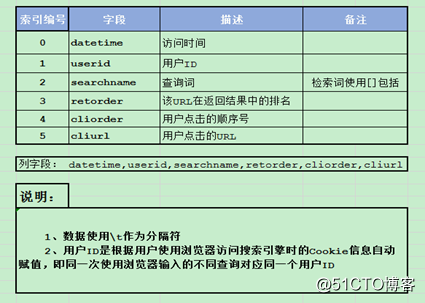
五、項目實戰
1)離線采集數據
?架構:flume+hbase+hive
??數據是實時的用戶查詢日誌信息,為了做離線的統計,需要將數據存儲HDFS,寫入的壓力非常大,單位時間內寫入的數據量比較大,直接向hdfs中寫入的效率比較低;而hbase,高速隨機讀寫的數據庫,這裏使用hbase去接收flume傳送過來的數據,當數據被傳入hbase之後,我們可以使用hive去關聯hbase中的數據。
create ‘zy_news_log‘, ‘cf‘
2)關聯flume+hbase
?使用sink為hbase或者asynchbase,但是這兩種方式其中定義EventSerializer滿足不了我們的需求,日誌數據有6列,數據以\t分割,但是默認的hbasesink只能做到一列,所以只能自定義hbase-sink。
自定義sink源代碼:
編譯打包: mvn package -DskipTests
將項目target目錄下面的flume-hbase-sink-1.0-SNAPSHOT.jar
放入到flume集群中的lib的目錄下。
編寫flume:flume-hbase-sink.conf
######################################################### ##主要作用是文件中的新增內容,將數據打入到HBase中 #註意:Flume agent的運行,主要就是配置source channel sink ##下面的a1就是agent的代號,source叫r1 channel叫c1 sink叫k1 ######################################################### a1.sources = r1 a1.sinks = k1 a1.channels = c1 #對於source的配置描述 監聽目錄中的新增數據 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /home/hadoop1/flume_properties/flume/flume-hbase.txt #對於sink的配置描述 使用hbase做數據的消費 a1.sinks.k1.type = hbase a1.sinks.k1.table = news_log a1.sinks.k1.columnFamily = cf a1.sinks.k1.serializer = org.apache.flume.sink.hbase.RegexHbaseEventSerializer #對於channel的配置描述 使用內存緩沖區域做數據的臨時緩存,文件 a1.channels.c1.type = file a1.channels.c1.checkpointDir = /home/hadoop1/flume_properties/flume/checkpoint a1.channels.c1.dataDirs = /home/hadoop1/flume_properties/flume/channel a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 100 #通過channel c1將source r1和sink k1關聯起來 a1.sources.r1.channels = c1 a1.sinks.k1.channel =c1
後臺啟動:flume-ng agent -n a1 -c conf -f flume-hbase-sink.conf -Dflume.root.logger=INFO,console
關聯flume+hbase:
hive創建hbase的表:
CREATE EXTERNAL TABLE zy_news_log(
id string,
datetime string,
userid string,
searchname string,
retorder int,
cliorder int,
cliurl string
)
STORED BY ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler‘
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf:datetime,cf:userid,cf:searchname,cf:retorder,cf:cliorder,cf:cliurl")
TBLPROPERTIES ("hbase.table.name" = "zy_news_log", "hbase.mapred.output.outputtable" = "zy_news_log");之後就可以在hive中做一些查詢操作,來完成相關業務。
2)實時采集數據
?架構:flume+Kafka
創建topic:
bin/kafka-topics.sh --create --topic zy-news-logs --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 --partitions 3 --replication-factor 3指定flume的配置文件:flume-kafka-sink.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#對於source的配置描述 監聽文件中的新增數據 exec
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/data/projects/news/data/news_log_rt.log
#對於sink的配置描述 使用kafka日誌做數據的消費
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.sinks.k1.kafka.topic = zy-news-logs
a1.sinks.k1.kafka.flumeBatchSize = 1000
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
#對於channel的配置描述 使用文件做數據的臨時緩存 這種的安全性要高
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 1000
#通過channel c1將source r1和sink k1關聯起來
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c14)數據的統計分析
? SparkStreaming+Kafka+web+scala+java+maven+hbase/mysql/redis
具體的代碼實現可以在小編的博客中下載:
新聞網站大數據項目