
譜聚類例項
在處理非完全圖的聚類時候,很難找到一個有效的聚類演算法去做聚類。
對於下圖來說,10號點和15號點的位置相隔並不是那麼近,如用普通聚類演算法對下圖做聚類,通常會把10號點和15號點聚在一個類上,所以一般的聚類效果並沒有那麼好。
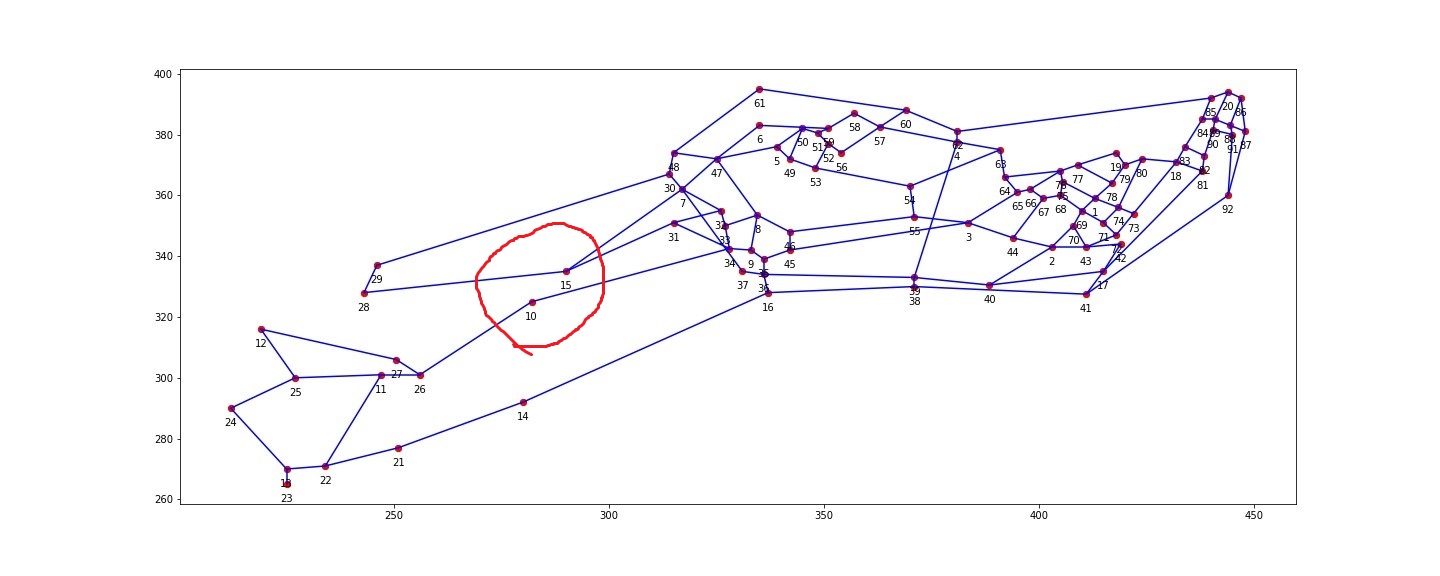
而譜聚類,就很能很好的處理這類問題。
下面我們來重點介紹譜聚類
譜聚類(SpectralClustering),就是要把樣本合理地分成兩份或者K份。從圖論的角度來說,譜聚類的問題就相當於一個圖的分割問題。即給定一個圖G = (V, E),頂點集V表示各個樣本,帶權的邊表示各個樣本之間的相似度,譜聚類的目的便是要找到一種合理的分割圖的方法,使得分割後形成若干個子圖,連線不同子圖的邊的權重(相似度)儘可能低,同子圖內的邊的權重(相似度)儘可能高。物以類聚,人以群分。
(一) 演算法步驟
- 根據資料構造一個Graph,Graph的每一個節點對應一個數據點,將各個點連線起來(隨後將那些已經被連線起來但並不怎麼相似的點,通過cut/RatioCut/NCut 的方式剪開),並 且邊的權重用於表示資料之間的相似度。把這個Graph用鄰接矩陣的形式表示出來,記為 W。
- 把W的每一列元素加起來得到N個數,把它們放在對角線上(其他地方都是零),組成一個的對角矩陣,記為度矩陣D,並把的結果記為拉普拉斯矩陣。
- 求出L的前k個特徵值(前k個指按照特徵值的大小從小到大排序得到),以及對應的特徵向量。
- 把這k個特徵(列)向量排列在一起組成一個的矩陣,將其中每一行看作k維空間中的一個向量,並使用 K-means 演算法進行聚類。聚類的結果中每一行所屬的類別就是原 來 Graph 中的,因此節點亦即最初的N個數據點分別所屬的類別。
(二) 譜聚類的實現
python程式設計,利用sklearn.cluster 下的 SpectralClustering可以很輕易的實現
from sklearn.cluster import SpectralClustering labels=SpectralClustering(affinity='nearest_neighbors',n_clusters=20, n_neighbors=3).fit_predict(route)
#labels=
[ 3, 3, 5, 7, 8, 8, 9, 4, 4, 15, 15, 2, 2, 15, 16, 17, 18,
13, 1, 12, 2, 2, 2, 2, 2, 15, 15, 16, 16, 9, 4, 4, 4, 4,
17, 17, 17, 14, 14, 14, 18, 18, 3, 5, 4, 4, 9, 9, 8, 8, 8,
8, 8, 5, 5, 8, 19, 19, 8, 19, 8, 7, 7, 6, 6, 6, 6, 11,
3, 3, 3, 3, 3, 3, 11, 11, 11, 1, 1, 1, 13, 13, 13, 10, 12,
12, 0, 0, 10, 10, 0, 0]
其中:
1)n_clusters:代表我們在對譜聚類切圖時降維到的維數。如分為20個聚類簇,n_clusters=20。
2) affinity: 也就是我們的相似矩陣的建立方式。可以選擇的方式有三類,第一類是 'nearest_neighbors',即K鄰近法;第二類是'precomputed',即自定義相似矩陣;第三類是全連線法,可以使用各種核函式來定義相似矩陣,還可以自定義核函式。基於對有向圖的聚類,本文的引數選擇是,affinity='nearest_neighbors', n_neighbors=3。
再把圖畫出來,完美解決類似於10號和15號座標分成一類的問題。結果如下圖
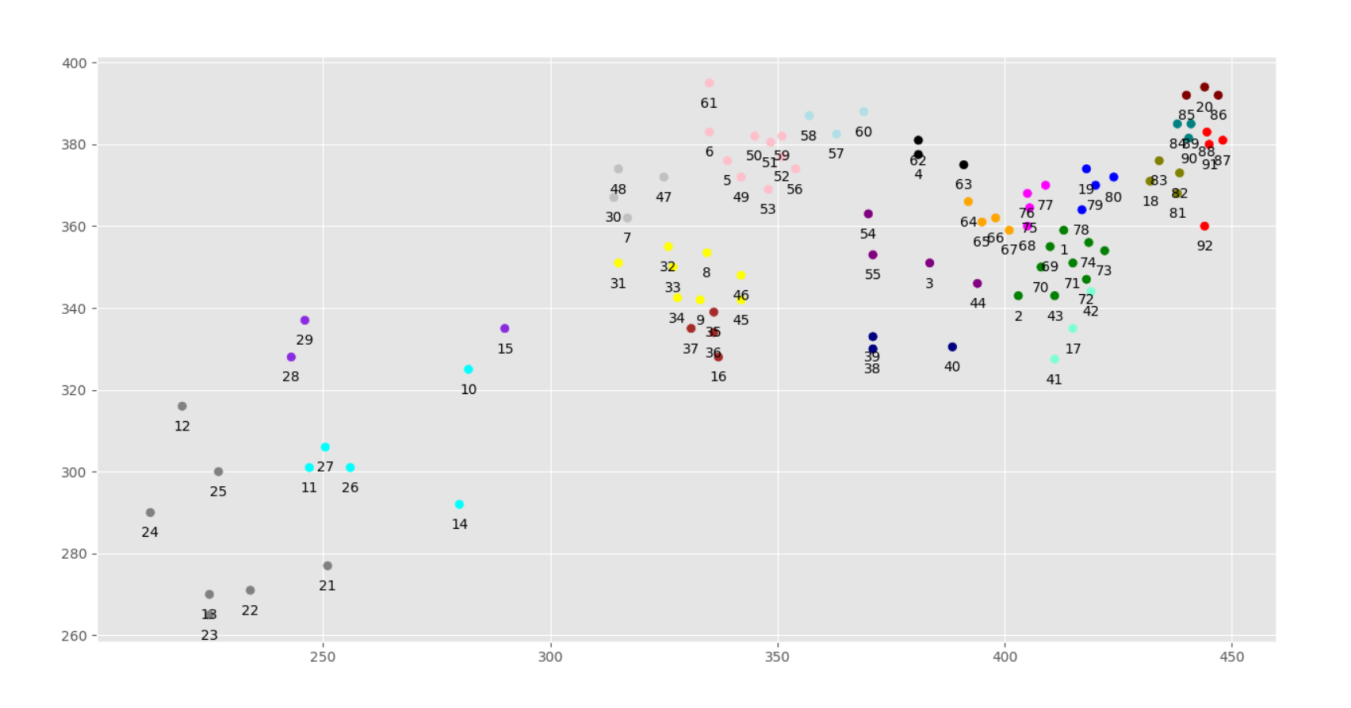
這個例子的實現所需要的資料和程式碼已經上傳到github:https://github.com/yjx7/-SpectralClustering.git 有用給個star謝謝啦