
圖文 高併發環境下HashMap的問題
我們來講解高併發環境下,HashMap可能出現的致命問題。




HashMap的容量是有限的。當經過多次元素插入,使得HashMap達到一定飽和度時,Key對映位置發生衝突的機率會逐漸提高。
這時候,HashMap需要擴充套件它的長度,也就是進行Resize。
影響發生Resize的因素有兩個:
- Capacity : HashMap的當前長度。長度是2的冪。
- LoadFactor : HashMap負載因子,預設值為0.75f。
衡量HashMap是否進行Resize的條件如下:
HashMap.Size >= Capacity * LoadFactor


- 擴容
建立一個新的Entry空陣列,長度是原陣列的2倍。
- ReHash
遍歷原Entry陣列,把所有的Entry重新Hash到新陣列。為什麼要重新Hash呢?因為長度擴大以後,Hash的規則也隨之改變。
讓我們回顧一下Hash公式:
index = HashCode(Key) & (Length - 1)
當原陣列長度為8時,Hash運算是和111B做與運算;新陣列長度為16,Hash運算是和1111B做與運算。Hash結果顯然不同。
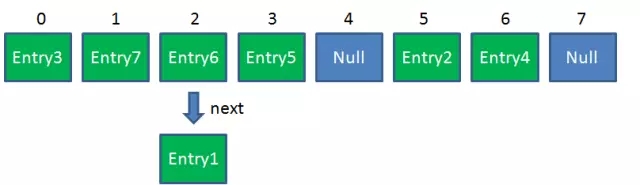
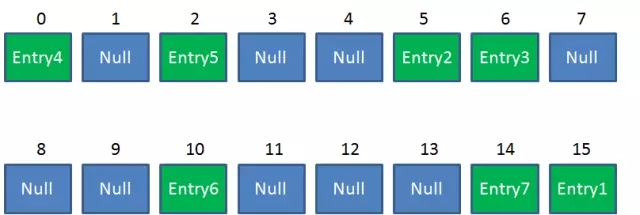
Resize前的HashMap:
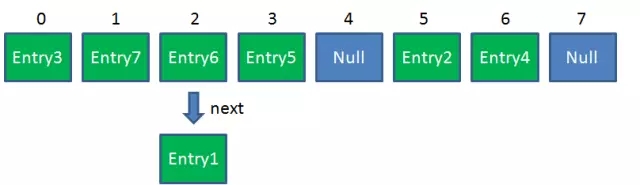
Resize後的HashMap:
ReHash的Java程式碼如下:



注意:下面的內容十分燒腦,請小夥伴們坐穩扶好。
假設一個HashMap已經到了Resize的臨界點。此時有兩個執行緒A和B,在同一時刻對HashMap進行Put操作:
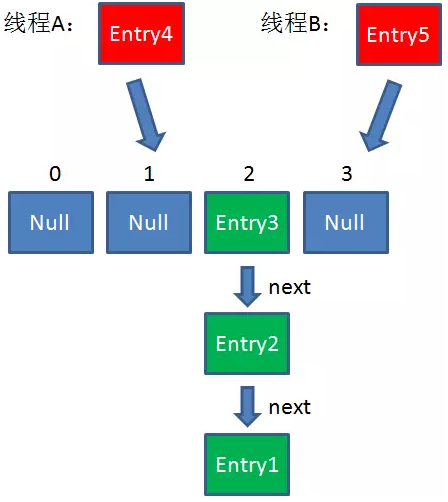
此時達到Resize條件,兩個執行緒各自進行Rezie的第一步,也就是擴容:
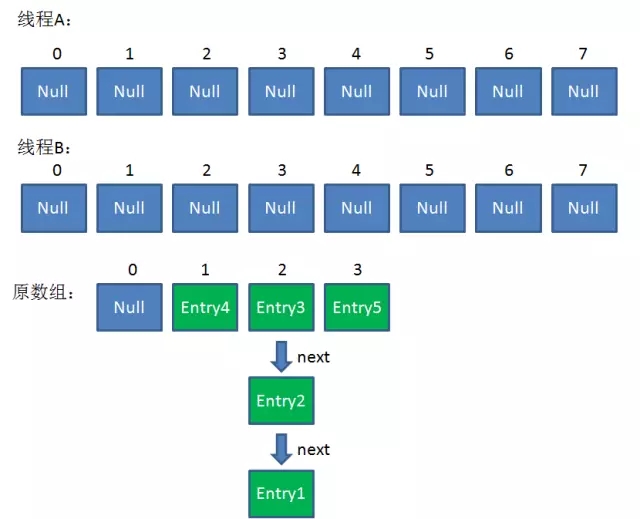
這時候,兩個執行緒都走到了ReHash的步驟。讓我們回顧一下ReHash的程式碼:

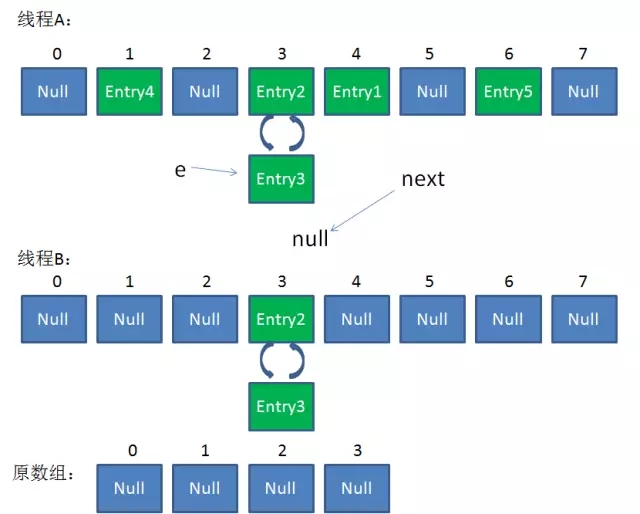
假如此時執行緒B遍歷到Entry3物件,剛執行完紅框裡的這行程式碼,執行緒就被掛起。對於執行緒B來說:
e = Entry3
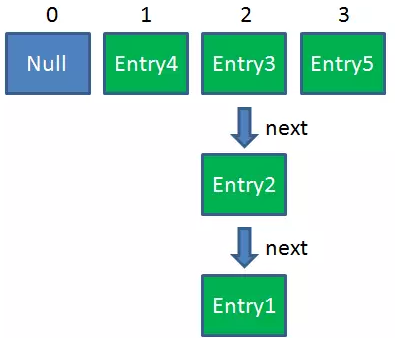
next = Entry2這時候執行緒A暢通無阻地進行著Rehash,當ReHash完成後,結果如下(圖中的e和next,代表執行緒B的兩個引用):
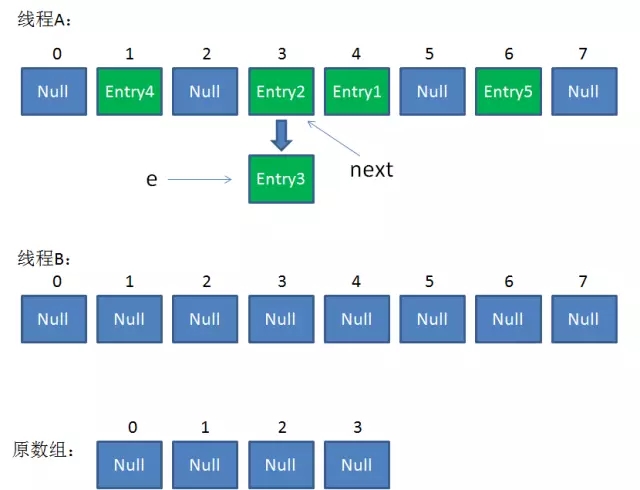
直到這一步,看起來沒什麼毛病。接下來執行緒B恢復,繼續執行屬於它自己的ReHash。執行緒B剛才的狀態是:
e = Entry3
next = Entry2

當執行到上面這一行時,顯然 i = 3,因為剛才執行緒A對於Entry3的hash結果也是3。

我們繼續執行到這兩行,Entry3放入了執行緒B的陣列下標為3的位置,並且e指向了Entry2。此時e和next的指向如下:
e = Entry2
next = Entry2整體情況如圖所示:
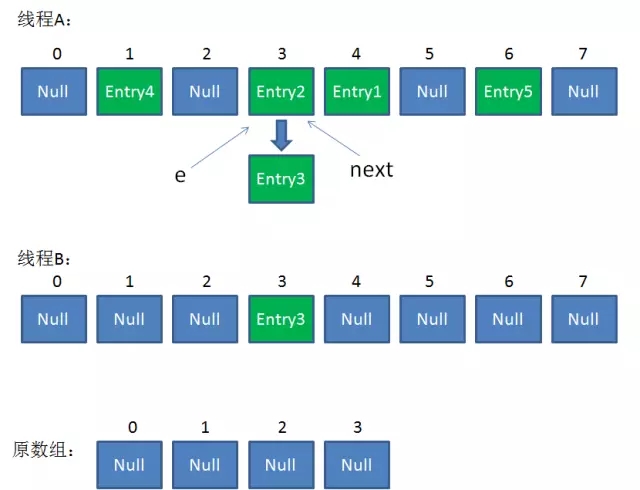
接著是新一輪迴圈,又執行到紅框內的程式碼行:

e = Entry2
next = Entry3整體情況如圖所示:

接下來執行下面的三行,用頭插法把Entry2插入到了執行緒B的陣列的頭結點:

整體情況如圖所示:
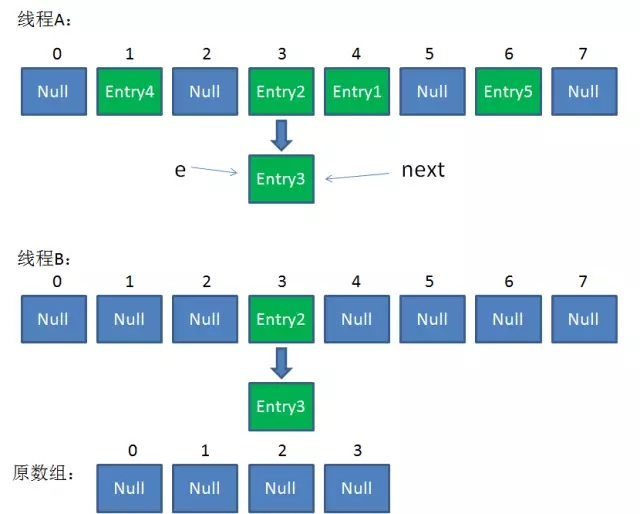
第三次迴圈開始,又執行到紅框的程式碼:

e = Entry3
next = Entry3.next = null最後一步,當我們執行下面這一行的時候,見證奇蹟的時刻來臨了:

newTable[i] = Entry2
e = Entry3
Entry2.next = Entry3
Entry3.next = Entry2
連結串列出現了環形!
整體情況如圖所示:
此時,問題還沒有直接產生。當呼叫Get查詢一個不存在的Key,而這個Key的Hash結果恰好等於3的時候,由於位置3帶有環形連結串列,所以程式將會進入死迴圈!