
推薦系統中的召回率與準確率
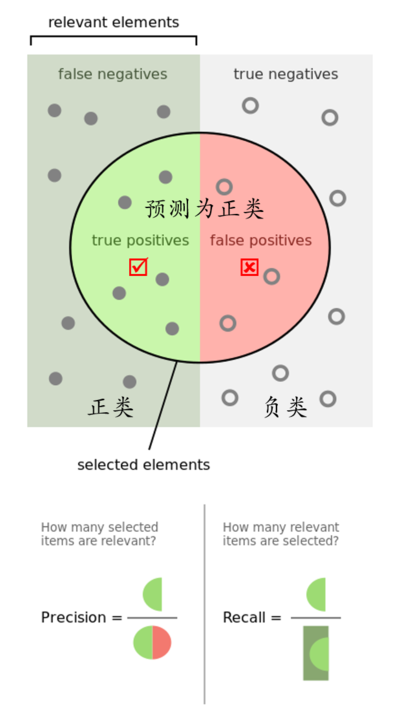
精確率是針對我們預測結果而言的,它表示的是預測為正的樣本中有多少是真正的正樣本,例如我們給使用者推薦了100條新聞,其中10條使用者產生了點選,那麼準確率為10/100 = 0.1
而召回率是針對我們原來的樣本而言的,它表示的是樣本中的正例有多少被預測正確了, 例如我們給使用者推薦了100條新聞,其中10條使用者產生了點選,而使用者最終在平臺上總共點選了200條新聞,那麼召回率為10 / 200 = 0.05, 表示的是推薦系統推薦的那些符合使用者興趣併產生點選的新聞量佔了使用者實際總共點選的新聞 有多少比例
其實就是分母不同,一個分母是預測為正的樣本數,另一個是原來樣本中所有的正樣本數。但分子都是表示預測的正樣本與原來正樣本的交集。
相關推薦
推薦系統中的召回率與準確率
精確率是針對我們預測結果而言的,它表示的是預測為正的樣本中有多少是真正的正樣本,例如我們給使用者推薦了100條新聞,其中10條使用者產生了點選,那麼準確率為10/100 = 0.1而召回率是針對我們原來的樣本而言的,它表示的是樣本中的正例有多少被預測正確了, 例如我們給使用者推薦了100條新聞,其中10條使用
機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介
模型 可擴展性 決策樹 balance rman bsp 理解 多個 缺失值 數據挖掘、機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介。 引言: 在機器學習、數據挖掘、推薦系統完成建模之後,需要對模型的
召回率與準確率(Precision and Recall)
A B 未檢索到 C D A:檢索到的,相關的 (搜到的也想要的) B:檢索到的,但是不相關的 (搜到的但沒用的) C:未檢索到的,但卻是相關的 (沒搜到,然而實際上想要的) D:未檢索到的,也不相關的 (沒搜到也沒用的) 通常我們希望:資料庫中相關的文件,被檢索到的越多越好,這是追求“查
推薦系統中準確率和召回率的理解
最近讀到推薦系統中的TopN推薦,它的預測準確率一般是通過準確率和召回率來進行評估的,那麼我們就要理解,什麼是準確率,什麼是召回率! 準確率,顧名思義,就是準確程度。通過正確數/總數得
CS229 7.2 應用機器學習方法的技巧,準確率,召回率與 F值
建立模型 當使用機器學習的方法來解決問題時,比如垃圾郵件分類等,一般的步驟是這樣的: 1)從一個簡單的演算法入手這樣可以很快的實現這個演算法,並且可以在交叉驗證集上進行測試; 2)畫學習曲線以決定是否更多的資料,更多的特徵或者其他方式會有所幫助; 3)人工檢查那些演算法預測錯誤的例子(在交叉驗證集上)
召回率和準確率之於推薦演算法的理解
推薦演算法有兩種準確度評價指標: 1、預測準確度:比如MAE,RMSE 2、分類準確度: 分類準確度定義為推薦演算法對一個產品使用者是否喜歡判定正確的比例。因此 ,當用戶只有二元選擇時 ,用分類準確度進行評價較為合適。因此,想要用準確率和召回率評價推薦演算法,必須將評
推薦系統中所需的概率論與數理統計知識
前言 一個月餘前,在微博上感慨道,不知日後是否有無機會搞DM,微博上的朋友只看不發的圍脖評論道:演算法研究領域,那裡要的是數學,你可以深入學習數學,將演算法普及當興趣。想想,甚合我意。自此,便從rickjin寫的“正態分佈的前世今生”開始研習數學。
FP,FN,TP,TN與精確率(Precision),召回率(Recall),準確率(Accuracy)
一: FP,FN,TP,TN 剛接觸這些評價指標時,感覺很難記憶FP,FN,TP,TN,主要還是要理解,理解後就容易記住了 P(Positive)和N(Negative) 代表模型的判斷結果 T(Tr
業務系統中的開與閉——分發模式
開閉原則;分發“對新增開放,對修改關閉。”——開閉原則。這裏分享一個我在業務系統設計過程中常用的一個“復合模式”,用作一個在業務系統設計中運用“開閉原則”的例子。背景這是一個賬務系統,負責處理各類業務流程中發生的若幹個賬戶之間的轉賬相關邏輯,包括賬戶余額的變更、以及各賬戶的流水記錄。這個系統的復雜度在於:不同
SVD(singular value decomposition)應用——推薦系統中
val end lin inf 抽取 比例 過程 說明 from 參考自:http://www.igvita.com/2007/01/15/svd-recommendation-system-in-ruby/ 看到SVD用於推薦評分矩陣的分解,主要是可以根據所需因子
召回率與精確率
兔子 clas 3.3 奇怪 其中 識別 信息 深度 class 《白話機器學習》這本書寫的不是特別好,但是解釋召回率和精確率這部分還是很好的。 200 張貓的圖片中,有 180 張可以正確識別為貓,而有 20 張誤判為狗 。 200 張狗的圖片可以全部正確判斷為狗 。 6
推薦系統:矩陣分解與鄰域的融合模型
critical with 分析 但是 rac 公式 download pearson 情況 推薦系統通常分析過去的事務以建立用戶和產品之間的聯系,這種方法叫做協同過濾。 協同過濾有兩種形式:隱語義模型(LFM),基於鄰域的模型(Neighborhood models)。
推薦系統中的稀疏矩陣處理
style k-means 協同過濾算法 基礎 尋找 中產 過濾 推薦系統 數據 數據稀疏問題嚴重制約著協同過滿推薦系統的發展。對於大型商務網站來說,由於產品和用戶數量都很龐大,用戶評分產品一般不超過產品總數的1%,兩個用戶共同評分的產品更是少之又少,解決數據稀菊問題是
推薦系統-協同過濾原理與實現
一、基本介紹 1. 推薦系統任務 推薦系統的任務就是聯絡使用者和資訊一方面幫助使用者發現對自己有價值的資訊,而另一方面讓資訊能夠展現在對它感興趣的使用者面前從而實現資訊消費者和資訊生產者的雙贏。 2. 與搜尋引擎比較 相同點:幫助使用者快速發現有用資訊的工具 不同點:和搜尋引擎不同的是推薦系統不
機器學習-推薦系統中基於深度學習的混合協同過濾模型
近些年,深度學習在語音識別、影象處理、自然語言處理等領域都取得了很大的突破與成就。相對來說,深度學習在推薦系統領域的研究與應用還處於早期階段。 攜程在深度學習與推薦系統結合的領域也進行了相關的研究與應用,並在國際人工智慧頂級會議AAAI 2017上發表了相應的研究成果《A Hy
推薦系統中協同過濾演算法實現分析(重要兩個圖!!)
“協”,指許多人協力合作。 “協同”,就是指協調兩個或者兩個以上的不同資源或者個體,協同一致地完成某一目標的過程。 “協同過濾”,簡單來說,就是利用興趣相投或擁有共同經驗的群體的喜好來給使用者推薦感興趣的資訊,記錄下來個人對於資訊相當程度的迴應(如評分),以達到過濾的目的,進而幫助別人篩
虛擬化在高安全資訊系統中的作用與前景
作為新一代資訊科技革命的代表,虛擬化的影響力從網際網路領域迅速擴充套件到了高安全網路領域。對於高安全網路而言,核心問題是保護其中儲存處理的機要資訊的安全,追求技術新特性倒是其次;但是,如果一些新技術的應用能夠為高安全網路帶來安全保密能力的提升,那麼這些新技術在高安全網路中就一定會引發使用需求——虛擬
真假正負例、混淆矩陣、ROC曲線、召回率、準確率、F值、AP
[轉自:https://blog.csdn.net/yimingsilence/article/details/53769861] 一、假正例和假負例 假正例(False Positive):預測為1,實際為0的樣本 假負例(False N
機器學習:奇異值分解SVD簡介及其在推薦系統中的簡單應用
轉載自:https://www.cnblogs.com/lzllovesyl/p/5243370.html 本文先從幾何意義上對奇異值分解SVD進行簡單介紹,然後分析了特徵值分解與奇異值分解的區別與聯絡,最後用python實現將SVD應用於推薦系統。 1.SVD詳解 SVD(singul
二分類相關評估指標(召回率、準確率,精確率,F度量,AUC和ROC)
基礎定義 通常在機器學習的二分類領域中,對模型的結果評估是必不可少的,本文主要總結了各個評估指標,對每個指標的定義,作用進行闡述。廢話到此,直接上乾貨。 TP:True Positive FP:False Positive TN:Tr