
推薦系統中準確率和召回率的理解
阿新 • • 發佈:2019-01-04
最近讀到推薦系統中的TopN推薦,它的預測準確率一般是通過準確率和召回率來進行評估的,那麼我們就要理解,什麼是準確率,什麼是召回率!
準確率,顧名思義,就是準確程度。通過正確數/總數得到。而正確數是什麼,總數是什麼呢?
召回率,我們可以理解為找到的數目與總的需要我們找到的數目的比,那在推薦系統中,什麼是找到的數目,什麼是需要我們總的找到的數目呢?
令R(u)表示在根據訓練資料給使用者做出的推薦列表,T(u)表示使用者根據測試資料給使用者做出的推薦列表,則
召回率:

準確率:
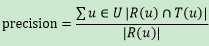
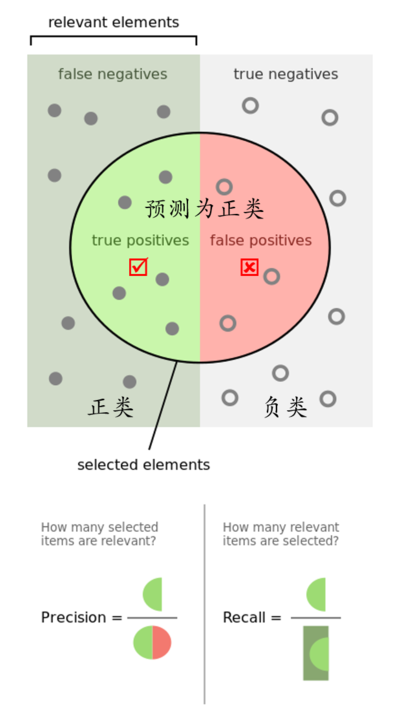
精確率是針對我們預測結果而言的,它表示的是預測為正的樣本中有多少是真正的正樣本。
而召回率是針對我們原來的樣本而言的,它表示的是樣本中的正例有多少被預測正確了。
其實就是分母不同,一個分母是預測為正的樣本數,另一個是原來樣本中所有的正樣本數。但分子都是表示預測的正樣本與原來正樣本的交集。
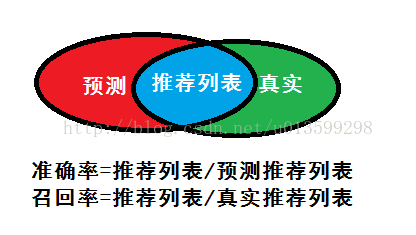
在資訊檢索領域,精確率和召回率又被稱為查準率和查全率,
查準率=檢索出的相關資訊量 / 檢索出的資訊總量
查全率=檢索出的相關資訊量 / 系統中的相關資訊總量