
【K-L散度(相對熵)】如何理解分割模型的損失函式
阿新 • • 發佈:2019-01-10
1、概念
Kullback-Leibler Divergence,即K-L散度。是一種量化兩種概率分佈P和Q之間差異的方式,又叫相對熵。
先給出結論:
其實我們可以把每張影象都看作是一個畫素x的概率分佈,那麼使用K-L散度就可以量化predict影象和label影象之間的差異。
(其實最開始我是一位loss function定義為 IoU就好呢,後來發現絕大多數都使用K-L散度,只在Kaggle挑戰賽上見過使用IoU的)
(交叉熵是相對熵的擴充套件)
2、詳解
2.1 K-L散度
已知 P(x) 和 Q(x) 是隨機變數x的兩種不同分佈,則 P 對 Q 的 K-L散度為:
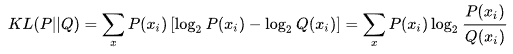
由於 代表隨機變數x的每一個取值,那麼:
![]()
可以看出,K-L散度其實是資料的分佈 P 和分佈 Q 之間的對數差值的期望,同時也表示 P 和 Q 間資訊損失的二進位制位數。
2.2 交叉熵(cross entropy)
對於 K-L散度公式進行變形:
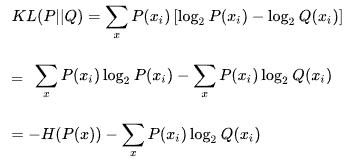
等式的前一部分恰巧就是 P(x)的熵,等式的後一部分,就是交叉熵:
![]()
在深度學習中,需要使用K-L散度評估labels和predicts間的差距,即:
![]()
但是由於KL散度中的前一部分 不變,故在優化過程中,只需要關注交叉熵 CE 就好。
所以一般在深度學習中直接用交叉熵做Loss,評估模型。
其實我們也可以直接把交叉熵理解判斷兩個分佈相似性的依據,本文則進一步解釋了交叉熵的由來,即交叉熵是由相對熵(K-L散度)衍生出來的。
參考: