
推薦系統的評價指標總結
評價一個推薦系統的好壞的重要性不用多少。本文的總結非常的全面,相信讀者通過閱讀本文以及本文參考的文獻可以對推薦系統的評價指標有比較全面的掌握。
對推薦系統的研究一個重要的環節是如何評價一個推薦演算法的好壞。關於推薦系統評價的研究很多,文獻[1,2,3]在不同程度對評價方法進行了總結。評價方法分為離線評估,使用者調查,線上評估。由於使用者調查和線上評估代價要求高,目前大多數的研究採用的是離線測試。其中文獻[3]總結了離線評價中用到的指標,包括準確度指標、基於排序加權的指標、覆蓋率、多樣性和新穎性等。本文的研究工作採用了幾種離線評估指標。將其歸納為準確性指標和非準確性指標。下面分別給予簡單介紹。
為了方便描述評價指標,下表對後面會用到的符號進行簡單說明。

1 準確性指標
準確性指標是推薦系統中最重要的指標。最常使用的準確性指標包括準確率和召回率。1)準確率[3]。推薦列表中使用者喜歡的物品所佔的比例。針對單個使用者u的推薦準確率:
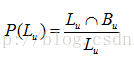
整個系統的準確率為:
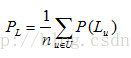
2)召回率[3]。測試集中有多少使用者喜歡的物品出現在推薦列表中。針對單個使用者u的推薦召回率:
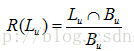
整個系統的召回率為:
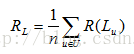
3)F1-Measure。F-Measure又稱為F-Score,是IR(資訊檢索)領域的常用的一個評價標準,計算公式為:
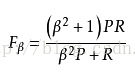
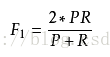
以上的準確性指標是隻從整個推薦列表的推薦使用者是否喜歡這種二值情況考慮的。除此之外,針對評分(比如0-5分制)的評估主要還有:
- RMSE (均方根誤差);
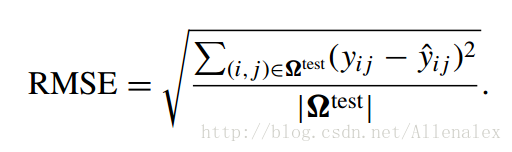
其中Ωtest為測試集;yij為使用者i對物品j的實際評分,y^ij為預測評分。
- MAE (平分絕對誤差):
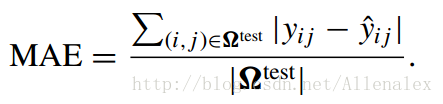
- Normalized Lpnorm:
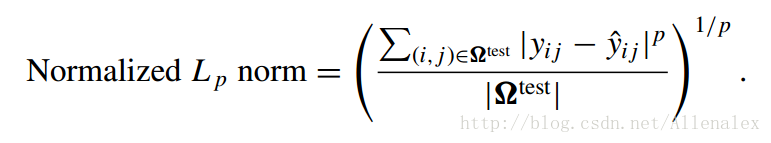 顯然,RMSE,MAE是 Normalized Lp norm的特例。
顯然,RMSE,MAE是 Normalized Lp norm的特例。
準確性指標侷限性:
- 不適合評估排序效能。關於排序的效能,推薦大家參考我的另一篇部落格: http://blog.csdn.net/allenalex/article/details/78161915
- 離線的準確率的提高並不意味著實際線上系統效果的提高。
2 非準確性指標
推薦系統中,除了推薦準確性外,還有其他一些重要的指標。包括推薦的多樣性、新穎性、驚喜度和覆蓋率等等。本文將這些指標統稱為非準確性指標。其中非準確性指標又可以分為使用者級非準確性指標和系統級非準確性指標。2.1.使用者級非準確性指標
1)個體多樣性。使用者的推薦列表列內的所有物品的平均相似度[2]: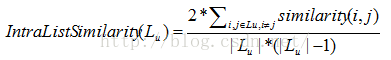
其中similarity(i,j)可以本博主的另一篇博文《推薦系統中的相似度計算方法總結》介紹的相似度計算方法來計算。求系統中所有使用者的推薦列表列內的所有物品的平均相似度的平均值得到整體(推薦列表)列內相似度:
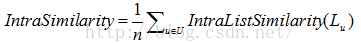
IntraSimilarity值越大,說明使用者的推薦列表內的物品之間總體平均相似度越高,也就是系統整體的個體多樣性越低。
2)新穎性[4]。評估新穎性最簡單的方法是計算推薦列表中物品的平均流行度:
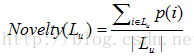
整個系統的新穎性為:
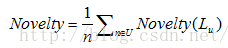
2.2.系統級的非準確性指標
1)整體多樣性[5]。採用推薦列表間的相似度,也就是使用者的推薦列表間的重疊度來定義整體多樣性。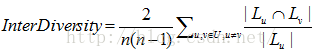
2)覆蓋率[6]。覆蓋率測量的是推薦系統推薦給所有使用者的物品數佔總物品數的比例。
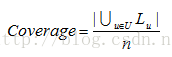
【參考文獻】
[1] Sarwar B, G. Karypis, JKonstan,et al. Item-based Collaborative Filtering Recommendation Algorithms. In: Proceedings of the 10th International WWW Conference. New York:ACM,2001,285-295.
[2] Zanker M, Felfernig A, Friedrich G. Recommender systems: an introduction[M]. Cambridge:Cambridge University Press, 2011,124-142.
[3] 朱鬱筱, 呂琳媛.推薦系統評價指標綜述.電子科技大學學報, 2012, 41(2): 163-175.
[4] L.-T. Weng,Y. Xu, Y. Li et al. Improving recommendation novelty based on topic taxonomy. In: IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology. Washington: ACM, 2007, 115–118.
[5]C.Ziegler, S.M. McNee, J. A. Konstan et al. Improving recommendation lists through topic diversification. In: Proceedings of the 14th International Conference on World Wide Web. Chiba: ACM, 2005, 22-32.[6] Ge M, Delgado-Battenfeld,Jannach D. Beyond accuracy: Evaluating recommender systems by coverage and serendipity. In:RecSys (2010): the 2010 ACM conference on Recommender systems. Barcelona:ACM,2010,257-260.