
推薦系統評測指標—精準率(Precision)、召回率(Recall)、F值(F-Measure)
下面簡單列舉幾種常用的推薦系統評測指標:
1、精準率與召回率(Precision & Recall)
精準率和召回率是廣泛用於資訊檢索和統計學分類領域的兩個度量值,用來評價結果的質量。其中精度是檢索出相關文件數與檢索出的文件總數的比率,衡量的是檢索系統的查準率;召回率是指檢索出的相關文件數和文件庫中所有的相關文件數的比率,衡量的是檢索系統的查全率。
一般來說,Precision就是檢索出來的條目(比如:文件、網頁等)有多少是準確的,Recall就是所有準確的條目有多少被檢索出來了。
精準率、召回率和 F 值是在魚龍混雜的環境中,選出目標的重要評價指標。不妨看看這些指標的定義先:
1. 精準率 = 提取出的正確資訊條數 / 提取出的資訊條數
2. 召回率 = 提取出的正確資訊條數 / 樣本中的資訊條數
兩者取值在0和1之間,數值越接近1,查準率或查全率就越高。
3. F值 = 正確率 * 召回率 * 2 / (正確率 + 召回率) (F 值即為正確率和召回率的調和平均值)
不妨舉這樣一個例子:某池塘有1400條鯉魚,300只蝦,300只鱉。現在以捕鯉魚為目的。撒一大網,逮著了700條鯉魚,200只蝦,100只鱉。那麼,這些指標分別如下:
正確率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子裡的所有的鯉魚、蝦和鱉都一網打盡,這些指標又有何變化:
精準率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可見,正確率是評估捕獲的成果中目標成果所佔得比例;召回率,顧名思義,就是從關注領域中,召回目標類別的比例;而F值,則是綜合這二者指標的評估指標,用於綜合反映整體的指標。
當然希望檢索結果Precision越高越好,同時Recall也越高越好,但事實上這兩者在某些情況下有矛盾的。比如極端情況下,我們只搜尋出了一個結果,且是準確的,那麼Precision就是100%,但是Recall就很低;而如果我們把所有結果都返回,那麼比如Recall是100%,但是Precision就會很低。因此在不同的場合中需要自己判斷希望Precision比較高或是Recall比較高。如果是做實驗研究,可以繪製Precision-Recall曲線
來幫助分析。
2、綜合評價指標(F-Measure)
P和R指標有時候會出現的矛盾的情況,這樣就需要綜合考慮他們,最常見的方法就是F-Measure(又稱為F-Score)。
F-Measure是Precision和Recall加權調和平均:
當引數α=1時,就是最常見的F1,也即
可知F1綜合了P和R的結果,當F1較高時則能說明試驗方法比較有效。
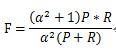
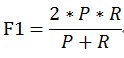
3、E值
E值表示查準率P和查全率R的加權平均值,當其中一個為0時,E值為1,其計算公式:
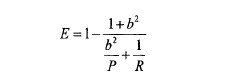
b越大,表示查準率的權重越大。
4、平均正確率(Average Precision, AP)
平均正確率表示不同查全率的點上的正確率的平均。
相關推薦
推薦系統評測指標—精準率(Precision)、召回率(Recall)、F值(F-Measure)
下面簡單列舉幾種常用的推薦系統評測指標: 1、精準率與召回率(Precision & Recall) 精準率和召回率是廣泛用於資訊檢索和統計學分類領域的兩個度量值,用來評價結果的質量。其中精度是檢索出相關文件數與檢索出的文件總數的比率,衡量的是檢索系統的查準
推薦系統評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)
mda 統計 混雜 分類 sha 指標 lock 網頁 log 下面簡單列舉幾種常用的推薦系統評測指標: 1、準確率與召回率(Precision & Recall) 準確率和召回率是廣泛用於信息檢索和統計學分類領域的兩個度量值,用來評價結果的質量。其中精度是
推薦系統評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)_DM
下面簡單列舉幾種常用的推薦系統評測指標: 1、準確率與召回率(Precision & Recall) 準確率和召回率是廣泛用於資訊檢索和統計學分類領域的兩個度量值,用來評價結果的質量。其中精度是檢索出相關文件數與檢索出的文件總數的比率,衡量的是檢索系統的查準率;召
推薦系統評測指標
0前言: 什麼才是好的推薦系統?這是推薦系統評測的需要解決的首要問題。那我們怎麼去判斷一個系統的好壞呢?我們認為一個好的推薦系統不僅僅能夠準確的預測使用者的行為,而且還能夠擴充套件使用者的視野,幫助使用者發現那些他們可能會感興趣但卻不那麼容易發現的東西。 評
準確率accuracy、精確率precision和召回率recall
cal rac ive precision bsp trie true ron 所有 準確率:在所有樣本中,準確分類的數目所占的比例。(分對的正和分對的負占總樣本的比例) 精確率:分類為正確的樣本數,占所有被分類為正確的樣本數的比例。(分為正的中,分對的有多少) 召回率:分
準確率(accuracy),精確率(Precision)和召回率(Recall),AP,mAP的概念
先假定一個具體場景作為例子。假如某個班級有男生80人,女生20人,共計100人.目標是找出所有女生. 某人挑選出50個人,其中20人是女生,另外還錯誤的把30個男生也當作女生挑選出來了. 作為評估者的你需要來評估(evaluation)下他的工作 首先我們可以計算準確率(accuracy),其定
機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介
模型 可擴展性 決策樹 balance rman bsp 理解 多個 缺失值 數據挖掘、機器學習和推薦系統中的評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)簡介。 引言: 在機器學習、數據挖掘、推薦系統完成建模之後,需要對模型的
系統評測指標—準確率(Precision)、召回率(Recall)、F值(F-Measure)
綜合 gho 評估 static 指標 href net rec 出現 轉自:http://bookshadow.com/weblog/2014/06/10/precision-recall-f-measure/ 1、準確率與召回率(Precision & Reca
推薦系統評測標準TOPN之precision與recall
關於推薦系統topN的評估指標:precision(精確率)和recall(召回率) 關於準確率應該比較容易理解。但是召回率可能有點繞。下面是我覺得比較容易理解的解釋: 準確率和
評價訓練效果的值——精準度(precision)、召回率(recall)、準確率(accuracy)、交除並(IoU)
每次談到這些值得時候都很混亂,這邊通俗的講解出來,然而目前mAP還沒弄明白,後續弄明白再貼出來。。。。 TP是正樣本預測為正樣本 FP是負樣本預測為正樣本 FN是本為正,錯誤的認為是負樣本 TN是本為負,正確的認為是負樣本 precision就是在識別出來的圖片中(
推薦系統評測方法
推薦系統什麽才是好的推薦系統?以圖書推薦系統為例: 首先推薦系統要滿足用戶的需求,要盡可能地覆蓋各種圖書,要能收集到高質量的用戶反饋,增加用戶和圖書網站的交互,提高網站的收入。要能夠準確預測用戶的行為,還要擴展用戶的視野,幫助用戶發現那些他們可能會感興趣的但卻不那麽容易發現的東西。本文主要從用戶,網站,內容提
推薦系統--評估指標匯總
商品 rank eps 推薦 rac psi 系統 推薦系統 ranking 準確率。推薦給用戶的商品中,屬於測試集的比例,數學公式$P(L_{u})=\frac{L_{u}\bigcap B_{u}}{L_{u}}$ 。整個測試集的準確率為 $P_{L}=\frac{
機器學習:評價分類結果(實現混淆矩陣、精準率、召回率)
test set 目的 mod 二分 參數 nbsp return try 一、實例 1)構造極度偏差的數據 import numpy as np from sklearn import datasets digits = datasets.load_digits
準確率(Precision)、召回率(Recall)以及綜合評價指標(F1-Measure )
在資訊檢索和自然語言處理中經常會使用這些引數,下面簡單介紹如下: 準確率與召回率(Precision & Recall) 我們先看下面這張圖來加深對概念的理解,然後再具體分析。其中,用P代表Precision,R代表Recall 一般來說,Pre
《推薦系統實踐》(一)——推薦系統評測
一、預測準確度 <1>、評分預測 1.均方根誤差(RMSE) (1)均方根(RMS)也稱為效值,公式:Xrms=∑i=1NXi2NX_{rms}=\frac{\sqrt{\sum_{i=1}^NX_i^2}}{N}Xrms=N∑i=1NXi2
Precision,Recall and F1-measure 準確率、召回率以及綜合評價指標
通俗易懂,故轉一下。 轉自: http://www.cnblogs.com/bluepoint2009/archive/2012/09/18/precision-recall-f_measures.html 在資訊檢索和自然語言處理中經常會使用這些引數,下面簡單介紹如
推薦系統測評指標
一個完整的推薦系統一般含3個參與方:使用者、物品提供者和提供推薦系統的網站。一個好的推薦系統是能令三方共贏的系統。好的推薦系統不僅能準確預測使用者的行為,還能擴充套件使用者的視野,幫助使用者發現那些他們可能會感興趣,但卻不容易發現的東西。自己的理解:對使用者來說,好推薦系統
搜尋推薦系統評價指標
Precision和Recall 首先我們來看看下面這個混淆矩陣: pred_label/true_label Positive Negative Positive TP FP Negtive FN TN 如上表所示,行表示預測的label值,列
項亮《推薦系統實踐》讀書筆記1-推薦系統評價指標
推薦系統評價指標 1.評分預測 預測準確度: 均方根誤差(RMSE): 平均絕對誤差(MAE): 關於這兩個指標的優缺點,Netflix認為RMSE加大了對預測不準的使用者物品評分的懲罰(平方項的懲罰),因為對系統的評測更加苛刻。研究表明,如果
評估指標:準確率(Precision)、召回率(Recall)以及F值(F-Measure)
為了能夠更好的評價IR系統的效能,IR有一套完整的評價體系,通過評價體系可以瞭解不同資訊系統的優劣,不同檢索模型的特點,不同因素對資訊檢索的影響,從而對資訊檢索進一步優化。 由於IR的目標是在較短時間內返回較全面和準確的資訊,所以資訊檢索的評價指標通常從三個方面考慮:效