
Spark的前世今生
Spark是什麼?
Spark,是一種通用的大資料計算框架,正如傳統大資料技術Hadoop的MapReduce、 Hive引擎,以及Storm流式實時計算引擎等。
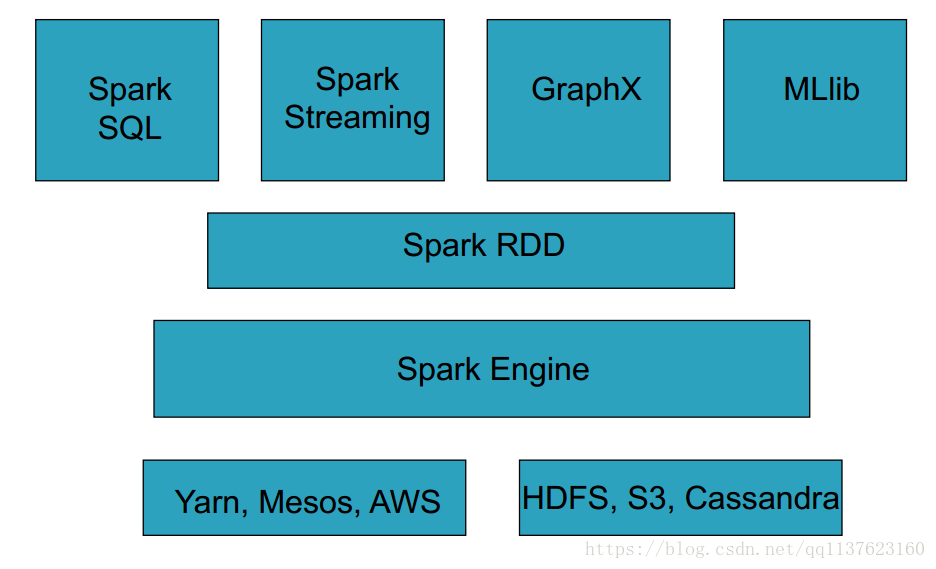
Spark包含了大資料領域常見的各種計算框架:比如Spark Core用於離線計算, Spark SQL用於互動式查詢, Spark Streaming用於實時流式計算, Spark MLlib用於機器學習, Spark GraphX用於圖計算。
Spark主要用於大資料的計算,而Hadoop以後主要用於大資料的儲存(比如HDFS、 Hive、 HBase等),以及資源排程(Yarn)。Spark+Hadoop的組合,是未來大資料領域最熱門的組合,也是最有前景的組合!
大資料體系概覽(Spark的地位)
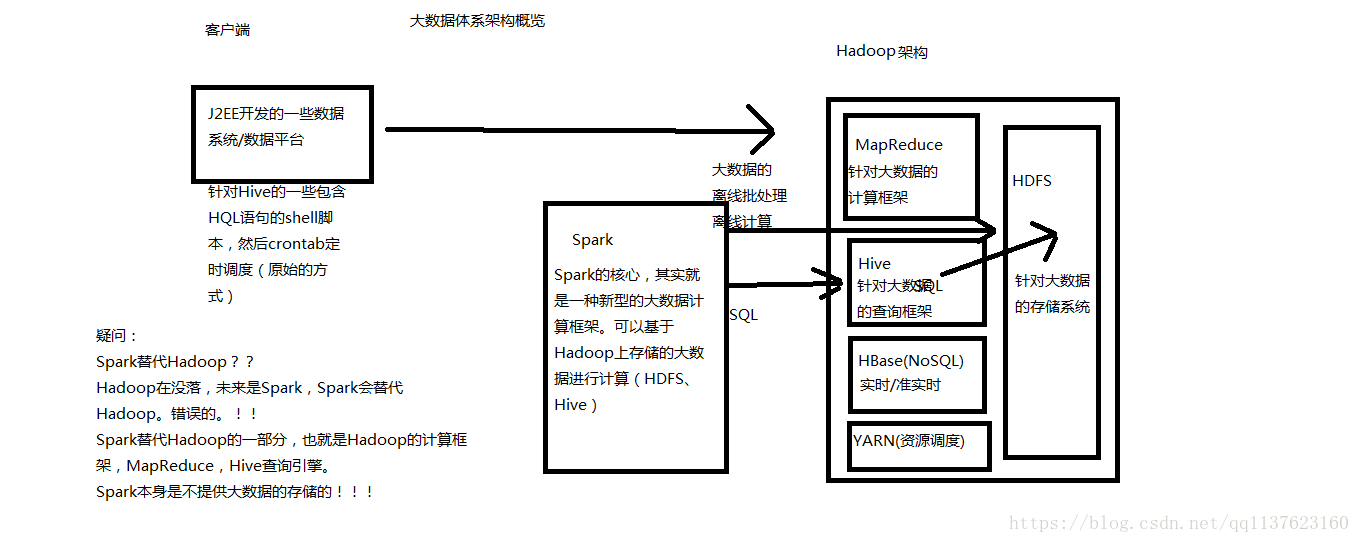
Spark的介紹
Spark,是一種”One Stack to rule them all”的大資料計算框架,期望使用一
個技術堆疊就完美地解決大資料領域的各種計算任務。 Apache官方,對Spark的
定義就是:通用的大資料快速處理引擎。
Spark使用Spark RDD、 Spark SQL、 Spark Streaming、 MLlib、 GraphX成
功解決了大資料領域中,離線批處理、互動式查詢、實時流計算、機器學習與圖
計算等最重要的任務和問題。
Spark除了一站式的特點之外,另外一個最重要的特點,就是基於記憶體進行
計算,從而讓它的速度可以達到MapReduce、 Hive的數倍甚至數十倍!
現在已經有很多大公司正在生產環境下深度地使用Spark作為大資料的計算
框架,包括eBay、 Yahoo!、 BAT、網易、京東、華為、大眾點評、優酷土豆、
搜狗等等。
Spark同時也獲得了多個世界頂級IT廠商的支援,包括IBM、 Intel等。
Spark整體架構
Spark的歷史沿革
2009年, Spark誕生於伯克利大學的AMPLab實驗室。最出Spark只是 一個實驗性的專案,程式碼量非常少,屬於輕量級的框架。
2010年,伯克利大學正式開源了Spark專案。
- 2013年, Spark成為了Apache基金會下的專案,進入高速發展期。第三方開發者貢獻了大量的程式碼,活躍度非常高。
- 2014年, Spark以飛快的速度稱為了Apache的頂級專案。
- 2015年~, Spark在國內IT行業變得愈發火爆,大量的公司開始重點部署或者使用Spark來替代MapReduce、 Hive、 Storm等傳統的大資料計算框架。
Spark的特點
速度快: Spark基於記憶體進行計算(當然也有部分計算基於磁碟,比如shuffle)。
容易上手開發: Spark的基於RDD的計算模型,比Hadoop的基於Map-Reduce的計算模型要更加易於理解,更加易於上手開發,實現各種複雜功能,比如二次排序、 topn等複雜操作時,更加便捷。
- 超強的通用性: Spark提供了Spark RDD、 Spark SQL、 Spark Streaming、 Spark MLlib、Spark GraphX等技術元件,可以一站式地完成大資料領域的離線批處理、互動式查詢、流式計算、機器學習、圖計算等常見的任務。
- 整合Hadoop: Spark並不是要成為一個大資料領域的“獨裁者”,一個人霸佔大資料領域所有的“地盤”,而是與Hadoop進行了高度的整合,兩者可以完美的配合使用。 Hadoop的HDFS、 Hive、 HBase負責儲存, YARN負責資源排程; Spark複雜大資料計算。實際上,Hadoop+Spark的組合,是一種“double win”的組合。
- 極高的活躍度: Spark目前是Apache基金會的頂級專案,全世界有大量的優秀工程師是Spark的committer。並且世界上很多頂級的IT公司都在大規模地使用Spark。
Spark VS MapReduce
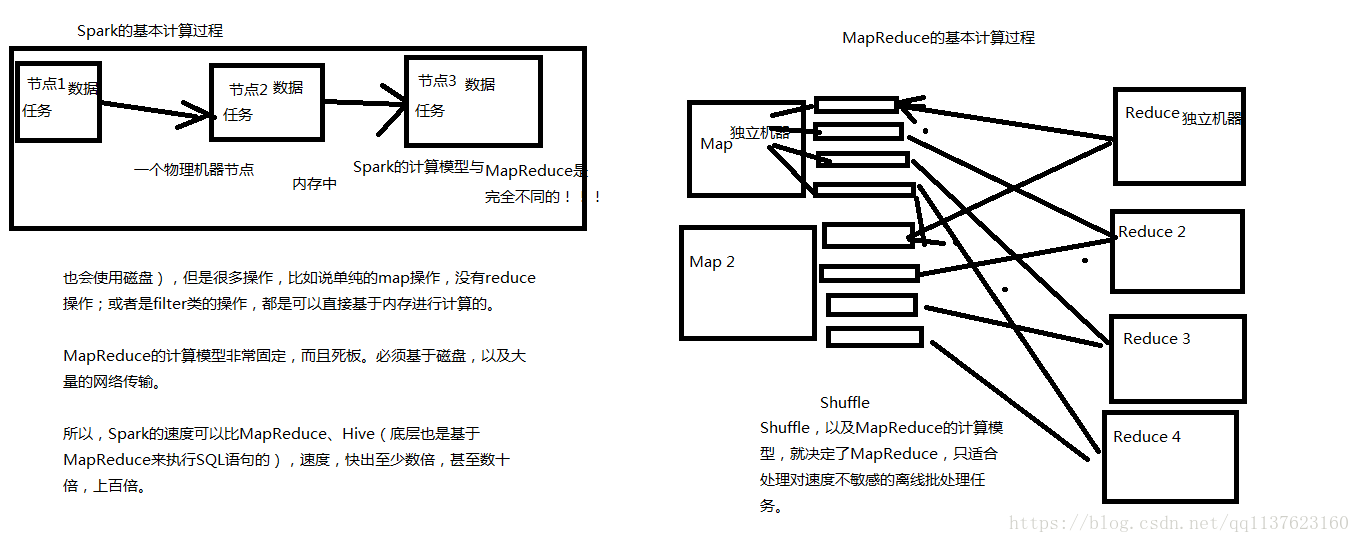
MapReduce能夠完成的各種離線批處理功能,以及常見演算法(比如二次排序、 topn等),基於Spark RDD的核心程式設計,都可以實現,並且可以更好地、更容易地實現。而且基於Spark RDD編寫的離線批處理程式,執行速度是MapReduce的數倍,速度上有非常明顯的優勢。
Spark相較於MapReduce速度快的最主要原因就在於, MapReduce的計算模型太死板,必須是mapreduce模式,有時候即使完成一些諸如過濾之類的操作,也必須經過map-reduce過程,這樣就必須經過shuffle過程。而MapReduce的shuffle過程是最消耗效能的,因為shuffle中間的過程必須基於磁碟來讀寫。
而Spark的shuffle雖然也要基於磁碟,但是其大量transformation操作,比如單純的map或者filter等操作,可以直接基於記憶體進行pipeline操作,速度效能自然大大提升。
但是Spark也有其劣勢。由於Spark基於記憶體進行計算,雖然開發容易,但是真正面對大資料的時候(比如一次操作針對10億以上級別),在沒有進行調優的情況下,可能會出現各種各樣的問題,比如OOM記憶體溢位等等。導致Spark程式可能都無法完全執行起來,就報錯掛掉了,而MapReduce即使是執行緩慢,但是至少可以慢慢執行完。
此外, Spark由於是新崛起的技術新秀,因此在大資料領域的完善程度,肯定不如MapReduce,比如基於HBase、 Hive作為離線批處理程式的輸入輸出, Spark就遠沒有MapReduce來的完善。實現起來非常麻煩。
Spark vs MapReduce的計算模型(記憶體)
Spark SQL VS Hive
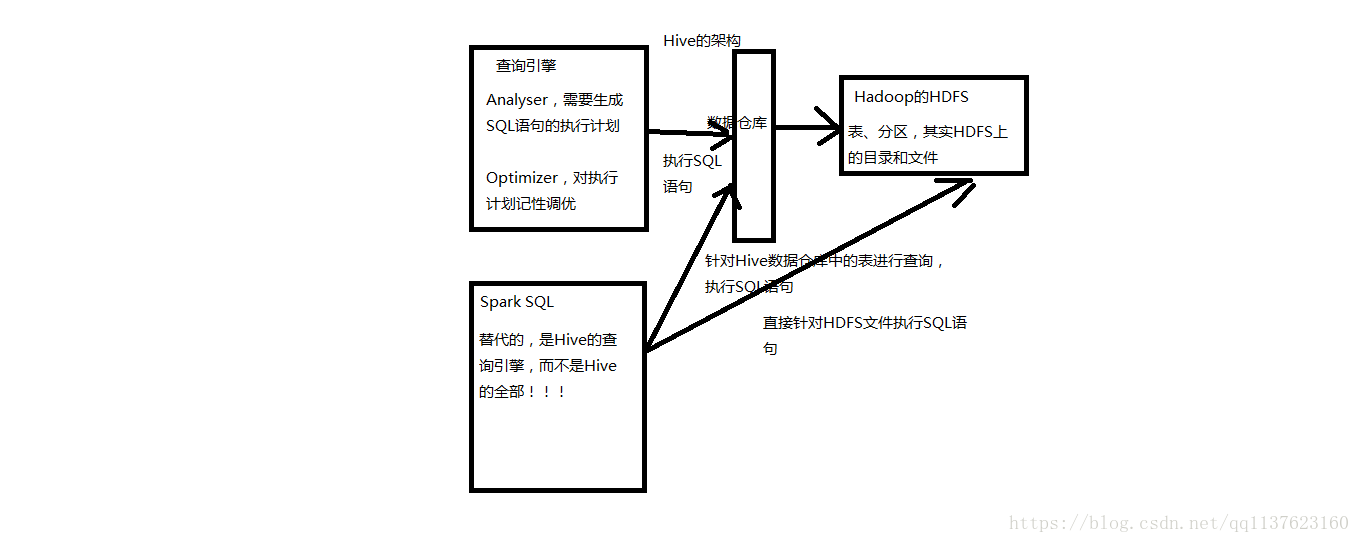
Spark SQL實際上並不能完全替代Hive,因為Hive是一種基於HDFS的資料倉庫,並且提供了基於SQL模型的,針對儲存了大資料的資料倉庫,進行分散式互動查詢的查詢引擎。
嚴格的來說, Spark SQL能夠替代的,是Hive的查詢引擎,而不是Hive本身,實際上即使在生產環境下, Spark SQL也是針對Hive資料倉庫中的資料進行查詢, Spark本身自己是不提供儲存的,自然也不可能替代Hive作為資料倉庫的這個功能。
Spark SQL的一個優點,相較於Hive查詢引擎來說,就是速度快,同樣的SQL語句,可能使用Hive的查詢引擎,由於其底層基於MapReduce,必須經過shuffle過程走磁碟,因此速度是非常緩慢的。很多複雜的SQL語句,在hive中執行都需要一個小時以上的時間。而Spark SQL由於其底層基於Spark自身的基於記憶體的特點,因此速度達到了Hive查詢引擎的數倍以上。
但是Spark SQL由於與Spark一樣,是大資料領域的新起的新秀,因此還不夠完善,有少量的Hive支援的高階特性, Spark SQL還不支援,導致Spark SQL暫時還不能完全替代Hive的查詢引擎。而只能在部分Spark SQL功能特性可以滿足需求的場景下,進行使用。
而Spark SQL相較於Hive的另外一個優點,就是支援大量不同的資料來源,包括hive、
json、 parquet、 jdbc等等。此外, Spark SQL由於身處Spark技術堆疊內,也是基於RDD來工作,因此可以與Spark的其他元件無縫整合使用,配合起來實現許多複雜的功能。比如Spark SQL支援可以直接針對hdfs檔案執行sql語句!
Spark SQL和Hive的關係
Spark Streaming VS Storm
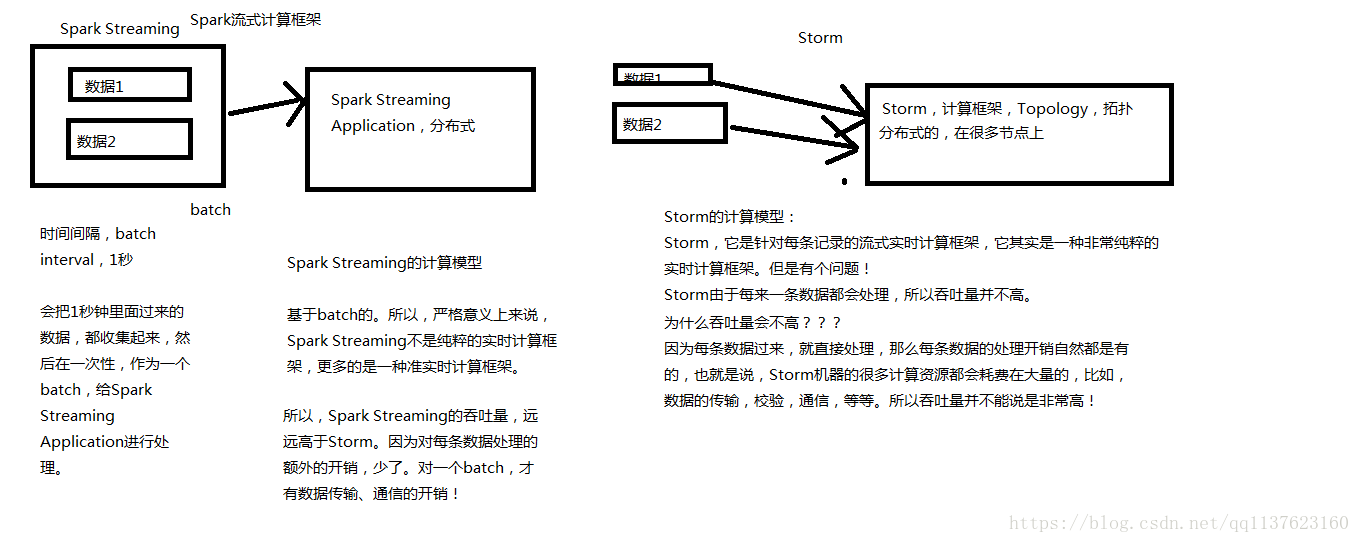
Spark Streaming與Storm都可以用於進行實時流計算。但是他們兩者的區別是非常大的。其中區別之一,就是, Spark Streaming和Storm的計算模型完全不一樣, Spark Streaming是基於RDD的,因此需要將一小段時間內的,比如1秒內的資料,收集起來,作為一個RDD,然後再針對這個batch的資料進行處理。
而Storm卻可以做到每來一條資料,都可以立即進行處理和計算。因此, Spark Streaming實際上嚴格意義上來說,只能稱作準實時的流計算框架;而Storm是真正意義上的實時計算框架。
此外, Storm支援的一項高階特性,是Spark Streaming暫時不具備的,即Storm支援在分散式流式計算程式(Topology)在執行過程中,可以動態地調整並行度,從而動態提高併發處理能力。而Spark Streaming是無法動態調整並行度的。
但是Spark Streaming也有其優點,首先Spark Streaming由於是基於batch進行處理的,因此相較於Storm基於單條資料進行處理,具有數倍甚至數十倍的吞吐量。
此外, Spark Streaming由於也身處於Spark生態圈內,因此Spark Streaming可以與Spark Core、Spark SQL,甚至是Spark MLlib、 Spark GraphX進行無縫整合。流式處理完的資料,可以立即進行各種map、 reduce轉換操作,可以立即使用sql進行查詢,甚至可以立即使用machine learning或者圖計算演算法進行處理。這種一站式的大資料處理功能和優勢,是Storm無法匹敵的。
因此,綜合上述來看,通常在對實時性要求特別高,而且實時資料量不穩定,比如在白天有高峰期的情況下,可以選擇使用Storm。但是如果是對實時性要求一般,允許1秒的準實時處理,而且不要求動態調整並行度的話,選擇Spark Streaming是更好的選擇。
Spark Streaming和Storm的計算模型對比
Spark的個人使用體會
首先, Spark目前來說,相較於MapReduce來說,可以立即替代的,並且會產生非常理想的效果的場景,就是要求低延時的複雜大資料互動式計算系統。比如某些大資料系統,可以根據使用者提交的各種條件,立即定製執行復雜的大資料計算系統,並且要求低延時(一小時以內)即可以出來結果,並通過前端頁面展示效果。在這種場景下,對速度比較敏感的情況下,非常適合立即使用Spark替代MapReduce。因為Spark編寫的離線批處理程式,如果進行了合適的效能調優之後,速度可能是MapReduce程式的十幾倍。從而達到使用者期望的效果。
其次,相對於Hive來說,對於某些需要根據使用者選擇的條件,動態拼接SQL語句,進行某類特定查詢統計任務的系統,其實類似於上述的系統。此時也要求低延時,甚至希望達到幾分鐘之內。此時也可以使用Spark SQL替代Hive查詢引擎。因此場景比較固定, SQL語句的語法比較固定,清楚肯定不會使用到Spark SQL所不支援的Hive語法特性。此時使用Hive查詢引擎可以需要幾十分鐘執行一個複雜SQL。而使用Spark SQl,可能只需要使用幾分鐘。可以達到使用者期望的效果
最後,對於Storm來說,如果僅僅要求對資料進行簡單的流式計算處理,那麼選擇storm或者spark streaming都無可厚非。但是如果需要對流式計算的中間結果(RDD),進行復雜的後續處理,則使用Spark更好,因為Spark本身提供了很多原語,比如map、 reduce、 groupByKey、 filter等等。
Spark目前在國內的現狀以及未來的展望
Spark目前在國內正在飛速地發展,並且在很多領域,以及慢慢開始替代傳統得一些基於Hadoop的元件。比如BAT、京東、搜狗等知名的網際網路企業,都在深度的,大規模地使用Spark。
但是,大家如果去觀察一下一些招聘網站對大資料的招聘需求,就會發現,目前來說,由於大部分還是大公司在使用Spark,因此大部分中小型企業,還是主要在使用Hadoop進行大資料處理。在招聘時,還是主要以hadoop工程師為主。 Spark以及Storm的招聘還是相對Hadoop來說,會少一些。
但是,大家如果通過本堂課的講解,能夠較為全面地對Spark有一個感性得認識,就能意識到, Spark在大資料領域中,是未來的一個趨勢和方向。隨著Spark、 Spark SQL以及Spark Streaming慢慢成熟,就會慢慢替代掉Hadoop的MapReduce、 Hive查詢等。大家可以想想,如果兩者都能夠實現相同的功能,而Spark甚至以後還可以做的更好,速度要快好幾倍,甚至好幾十倍。那麼還有誰會願意使用MapReduce或
Hive查詢引擎呢?
實際上,根據我在國內一線網際網路公司這幾年的工作和觀察,以及通過與行業內各個規模公司的朋友交流,認為,未來的主流,一定是hadoop+Spark的這種組合, double win的格局。 hadoop的特長,就是hdfs,分散式儲存,基於此之上的是Hive作為大資料的資料倉庫, HBase作為大資料的實時查詢NoSQL資料庫, YARN作為通用的資源排程框架;而Spark,則發揮它的特長,將各種各樣的大資料計算模型匯聚在一個技術堆疊內,對hadoop上的大資料進行各種計算處理!
因此,大家也可以看到, Spark目前正在變得越來越火爆,招聘的企業正在越來越多,而且目前國內spark人才可以說是稀缺!!!在目前,以及未來,完全供不應求!因此這種趨勢,以及這種現狀,就決定了,對於我們個人來說,目前進行spark的學習以及研究,完全是未來一個獲取快速升值的機會!!!
來自北講師:中華石杉