
《使用Python進行自然語言處理》學習筆記五
第三章 加工原料文字
3.1 從網路和硬碟訪問文字
1 電子書
古騰堡專案的其它文字可以線上獲得,
整個過程大概需要幾十秒(實驗室網路不行是硬傷)

使用raw()可以得到原始的字串。但是raw得到的資料絕對不是我們能直接拿去分析的,還要經過一些預處理。我們要將字串分解為詞和標點符號,正如我們在第 1 章中所看到的。這一步被稱為分詞, 它產生我們所熟悉的結構,一個詞彙和標點符號的連結串列。
2處理的 HTML
好像很多公測語料都是html或者xml釋出的,這個應該可以處理類似的資料。但書裡說其中仍然含有不需要的內容,包括網站導航及有關報道等,通過一些嘗試和出錯你可以找到內容索引的開始和結尾,並選擇你感興趣的識別符號,按照前面講的那樣初始化一個文字。
這裡面的“嘗試和出錯”有點不合適吧。難道不能按標籤去找嗎,寫一個網頁模版然後去抽取某基礎標籤的內容,之前都是這麼幹的。

3處理搜尋引擎的結果
網路可以被看作未經標註的巨大的語料庫。網路搜尋引擎提供了一個有效的手段,搜尋大量文字作為有關的語言學的例子。搜尋引擎的主要優勢是規模:因為你正在尋找這樣龐大的一個檔案集,會更容易找到你感興趣語言模式。而且,你可以使用非常具體的模式,僅在較小的範圍匹配一兩個例子,但在網路上可能匹配成千上萬的例子。網路搜尋引擎的第個優勢是非常容易使用。因此, 它是一個非常方便的工具, 可以快速檢查一個理論是否合理。
不幸的是,搜尋引擎有一些顯著的缺點。首先,允許的搜尋方式的範圍受到嚴格限制。不同於本地驅動器中的語料庫,你可以編寫程式來搜尋任意複雜的模式,搜尋引擎一般只允許你搜索單個詞或詞串,有時也允許使用萬用字元。其次,搜尋引擎給出的結果不一致,並且在不同的時間或在不同的地理區域會給出非常不同的結果。當內容在多個站點重複時,搜尋結果會增加。最後, 搜尋引擎返回的結果中的標記可能會不可預料的改變, 基於模式方法定位特定的內容將無法使用(通過使用搜索引擎 APIs 可以改善這個問題)。
4 處理處理 RSS 訂閱
我覺得這個部分可以使用爬蟲和html處理來解決,更加方便。
5 讀取本地檔案
只需要注意一點,使用”\\”就沒問題的。path2='D:\\PythonSource\\fileTest.txt'

6從 PDF、MS Word 及其他二進位制格式中提取文字
ASCII 碼文字和 HTML 文字是人可讀的格式。文字常常以二進位制格式出現,如 PDF 和MSWord,只能使用專門的軟體開啟。第三方函式庫如 pypdf 和 pywin32 提供了對這些格式的訪問。從多列文件中提取文字是特別具有挑戰性的。一次性轉換幾個檔案,會比較簡單些, 用一個合適的應用程式開啟檔案, 以文字格式儲存到本地驅動器, 然後以如下所述的方式訪問它。如果該文件已經在網路上,你可以在 Google 的搜尋框輸入它的 URL。搜尋結果通常包括這個文件的 HTML 版本的連結,你可以將它儲存為文字。
7捕獲使用者輸入
Python2.X的版本是s =raw_input("Enter some text: "),到了3.X好像是用input代替了raw_input,更加好記了。
8 NLP 的流程
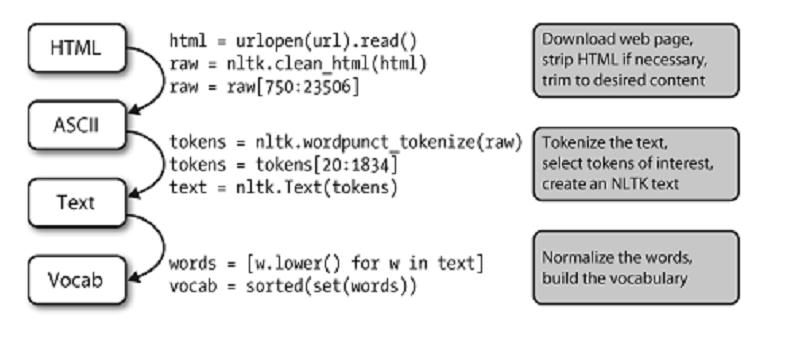
這個圖表示的很清楚,我覺得預處理的任務就是將非結構化的資料儘量結構化,以便進一步處理。
#!/usr/python/bin
#Filename:NltkTest89,一些關於文字資源處理的測試
from__future__ import division
importnltk, re, pprint
fromurllib import urlopen
importtime
importdatetime
classNltkTest89:
def __init__(self):
print 'Initing...'
def EbookTest(self,url):
starttime = datetime.datetime.now()
print 'Start at:'
print time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
raw = urlopen(url).read()
print len(raw)
print raw[:75]
endtime = datetime.datetime.now()
print 'Finish at:'
print time.strftime('%Y-%m-%d%H:%M:%S',time.localtime(time.time()))
print '下載和讀取文字使用了%d秒' %(endtime- starttime).seconds
return raw
def TokenTest(self,raw):
'''基於Project Gutenberg的一些分詞測試'''
tokens = nltk.word_tokenize(raw)
print type(tokens)
len(tokens)
print tokens[:10]
text = nltk.Text(tokens)
print type(text)
print text[1020:1060]
print text.collocations()
print raw.rfind("End of ProjectGutenberg's Crime")
def HtmlTest(self,url):
html = urlopen(url).read()
html[:60]
raw= nltk.clean_html(html)
tokens = nltk.word_tokenize(raw)
print tokens[:20]
def FileTest(self,filePath):
f = open(filePath)
for line in f:
print line.strip()
nt89=NltkTest89()
url1= "http://www.gutenberg.org/files/2554/2554.txt"
#nt89.EbookTest(url1)
#nt89.TokenTest(nt89.EbookTest(url1))
url2="http://news.bbc.co.uk/2/hi/health/2284783.stm"
#nt89.HtmlTest(url2)
path1=nltk.data.find('corpora/gutenberg/melville-moby_dick.txt')
path2='D:\\PythonSource\\fileTest.txt'
nt89.FileTest(path2)3.2字串:最底層的文字處理
1字串的基本操作
這一部分講的是Pyhton對字串的處理,字串處理哪種程式設計都有,再加上Python那麼人性化,所以整個上手很容易。
2輸出字串
也很簡單,只注意一點,在需要拼接字串的時候一定要注意,在拼接處需要空格的地方要加空格。如果沒有注意可能就會出現”Monty PythonHoly Grail“的情況,如果這是在處理其他指令的話就容易出大問題。之前用Java時就不小心過,取資料的mysql指令少了一個空格還找了一會才排掉錯。
3訪問單個字元
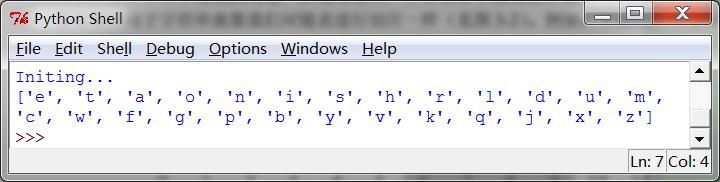
又想起那個關於四六級的笑話了,話說學渣背單詞,從前往後背,背不過C,從後往前背,背不過S。看來得說從前往後背,背不過e,從後往前背,背不過t,這樣才更科學。
4訪問子字串
主要是列表切片和find,很簡單。
5更多的字串操作
p100有詳情。師兄溫馨提示我,split和strip非常重要,尤其是strip和Java裡的trim一樣,處理文字資料經常需要去掉字串前後的空格什麼的,沒有會很麻煩。
6連結串列與字串的差異
當我們在一個 Python 程式中開啟並讀入一個檔案,我們得到一個對應整個檔案內容的字串。如果我們使用一個 for 迴圈來處理這個字串元素,所有我們可以挑選出的只是單
個的字元——我們不選擇粒度。相比之下, 連結串列中的元素可以很大也可以很小, 只要我們喜歡。例如:它們可能是段落、句子、短語、單詞、字元。所以,連結串列的優勢是我們可以靈活的決定它包含的元素,相應的後續的處理也變得靈活。因此,我們在一段 NLP 程式碼中可能做的第一件事情就是將一個字串分詞放入一個字串連結串列中。相反, 當我們要將結果寫入到一個檔案或終端,我們通常會將它們格式化為一個字串。
字串是不可變的:一旦你建立了一個字串,就不能改變它。然而,連結串列是可變的,其內容可以隨時修改。作為一個結論,連結串列支援修改原始值的操作,而不是產生一個新的值。
#-*-coding: utf-8-*-
#!/usr/python/bin
#Filename:NltkTest98,一些關於字串處理的測試
from__future__ import division
importnltk, re, pprint
fromurllib import urlopen
fromnltk.corpus import gutenberg
importtime
importdatetime
classNltkTest98:
def __init__(self):
print 'Initing...'
def AlphaTest(self,text):
raw = gutenberg.raw(text)
fdist = nltk.FreqDist(ch.lower() for chin raw if ch.isalpha())
print fdist.keys()
nt98=NltkTest98()
text='melville-moby_dick.txt'
nt98.AlphaTest(text)3.3使用 Unicode 進行文書處理
1 什麼是 Unicode?
Unicode 支援超過一百萬種字元。每個字元分配一個編號,稱為編碼點。檔案中的文字都是有特定編碼的,所以我們需要一些機制來將文字翻譯成 Unicode翻譯成 Unicode 叫做解碼。相對的,要將 Unicode 寫入一個檔案或終端,我們首先需要將 Unicode 轉化為合適的編碼——這種將 Unicode 轉化為其它編碼的過程叫做編碼.
2 從檔案中提取已編碼文字
3 在 Python 中使用本地編碼
在一個 Python 檔案中使用你的字串輸入及編輯的標準方法,需要在檔案的第一行或第二行中包含字串:'# -*- coding: utf-8-*-' 。注意windows裡面編輯的檔案到linux裡面要轉碼,不然會亂碼。
3.4 使用正則表示式檢測片語搭配
1 使用基本的元字元
P108正則表示式都是差不多的,pythonli裡的,java裡的,shell裡的都差不多。
2 範圍與閉包
T9 系統用於在手機上輸入文字。兩個或兩個以上的詞彙以相同的擊鍵順序輸入,這叫做輸入法聯想提示,這個原來是這樣的啊。那麼在使用者詞庫裡的應該優先權更大一點,這樣就符合個性化的要求。
3.5 正則表示式的有益應用
1 提取字元塊
2 在字元塊上做更多事情
3 查詢詞幹
這表明另一個微妙之處:“*”操作符是“貪婪的”,所以表示式的“.*”部分試圖儘可能多的匹配輸入的字串。
regexp= r'^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)?$'
^abc表示以abc開始
如果我們要使用括號來指定連線的範圍,但不想選擇要輸出的字串,必須新增“?:”

4 搜尋已分詞文字

這個在做商品評價什麼的應該非常有用的,直接抽取附近的形容詞然後統計所佔比例就可以了。
3.6 規範化文字
去掉所有的詞綴以及提取詞幹的任務等。更進一步的步驟是確保結果形式是字典中確定的詞,即叫做詞形歸併的任務。
1 詞幹提取器
NLTK 中包括了一些現成的詞幹提取器,Porter和 Lancaster 詞幹提取器按照它們自己的規則剝離詞綴。NltkTest105.TokenerCompare試了一下,好像是Porter好一些。雖說專業的比較好,但是據說nltk的預處理也就一般,英文的還是一般用Stanford的,可以試著比較一下。
2詞形歸併
WordNet 詞形歸併器刪除詞綴產生的詞都是在它的字典中的詞。 這個額外的檢查過程使詞形歸併器比剛才提到的詞幹提取器要慢。
好吧,確實很慢,大概慢一倍以上,不過還是可以接收的,可以考慮和Porter級聯使用。
3.7用正則表示式為文字分詞
分詞是將字串切割成可識別的構成一塊語言資料的語言單元。
1分詞的簡單方法
2 NLTK 的正則表示式分詞器
函式 nltk.regexp_tokenize()與 re.findall() 類似(我們一直在使用它進行分詞) 。 然而,nltk.regexp_tokenize()分詞效率更高,且不需要特殊處理括號。
3分詞的進一步問題
個人覺得,如果不是專業研究分詞,可以簡單的使用目前已公認的效果最好的分詞工具就可以了,不必要為了造飛機去研究冶鐵。
3.8分割
1斷句
在將文字分詞之前,我們需要將它分割成句子。NLTK通過包含 Punkt句子分割器(Kiss & Strunk,2006)簡化了這些。
2分詞
現在分詞的任務變成了一個搜尋問題:找到將文字字串正確分割成詞彙的字位串。我們假定學習者接收詞,並將它們儲存在一個內部詞典中。給定一個合適的詞典,是能夠由詞典中的詞的序列來重構源文字的。
好吧,默默的在這裡決定了,英文用Stanford的分詞,中文用NLPIR2014,不在這裡糾結了。
3.9格式化:從連結串列到字串
1從連結串列到字串
''.join(silly)
2字串與格式
太基礎了,不多說
3排列
%s 和%d。我們也可以指定寬度,如%6s,產生一個寬度為 6 的字串。
4將結果寫入檔案
儲存和記憶體是需要協調的,當無法提供足夠的記憶體支援時,要有意識的寫檔案儲存中間結果。尤其是訓練時間很長的結果,能少算一次就少算一次。
5文字換行
我們可以在 Python 的 textwrap 模組的幫助下采取換行。
fromtextwrap import fill
wrapped= fill(output)
printwrapped
程式碼片段NltkTest105
#-*- coding: utf-8-*-
#!/usr/python/bin
#Filename:NltkTest105,一些關於字串處理的測試
from__future__ import division
importnltk, re, pprint
fromurllib import urlopen
fromnltk.corpus import gutenberg, nps_chat
importtime
importdatetime
classNltkTest105:
def __init__(self):
print 'Initing...'
def ReTest(self,lan,regex):
wordlist = [w for w innltk.corpus.words.words(lan) if w.islower()]
print [w for w in wordlist ifre.search(regex, w)]
def T9Test(self,lan,regex):
wordlist = [w for w innltk.corpus.words.words(lan) if w.islower()]
print [w for w in wordlist ifre.search(regex, w)]
def stem(self,word):
regexp =r'^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)?$'
stem, suffix = re.findall(regexp,word)[0]
return stem
def TokensReTest(self):
moby =nltk.Text(gutenberg.words('melville-moby_dick.txt'))
print moby.findall(r"<a>(<.*>) <man>")
def TokenerCompare(self,tokens):
porter = nltk.PorterStemmer()
lancaster = nltk.LancasterStemmer()
wnl = nltk.WordNetLemmatizer()
print [porter.stem(t) for t in tokens]
print [lancaster.stem(t) for t intokens]
print [wnl.lemmatize(t) for t intokens]
def FileWrTest(self,path,content):
outFile=open(path,'w')
for word in sorted(content):
outFile.write(word+'\n')
nt105=NltkTest105()
lan='en'
regex1='ed$'
regex2='^[ghi][mno][jlk][def]$'
#nt105.ReTest(lan,regex1)
#nt105.T9Test(lan,regex2)
raw="""DENNIS: Listen, strange women lying in ponds distributingswords\
is nobasis for a system of government. Supreme executive power derives from\
amandate from the masses, not from some farcical aquaticceremony."""
tokens= nltk.word_tokenize(raw)
#print[nt105.stem(t) for t in tokens]
#nt105.TokensReTest()
#nt105.TokenerCompare(tokens)
words= set(nltk.corpus.genesis.words('english-kjv.txt'))
path='D:\\PythonSource\\outfiletest.txt'
nt105.FileWrTest(path,words)