
手把手教你完成半結構化資料的處理
前言
現在越來越多的資料以json的格式進行儲存,例如通過網路爬蟲時,那些非同步儲存的資料往往都是json型別的;再如企業資料庫中的日誌資料,也會以json的格式存放。前不久,一位網友就碰到了這個問題,手中Excel儲存的資料並不是標準化的結構資料,而是以json格式儲存在Excel的每個單元格。那今天我們就來聊聊如何利用Python將半結構化的json資料轉換成結構化資料。
簡單的json格式
其實json的格式與Python中的字典非常類似,資料放在大括號({})內,每一個元素都是鍵值對,元素之間以逗號隔開。我們都知道,在Python中,是可以將一個字典物件轉換成資料框的,接下來我們就通過一個簡單的例子慢慢進入複雜的環境。
# 載入第三方包
import pandas as pd # 資料處理包
import numpy as np # 數值計算包
import json # json檔案轉換包
# 一個簡單的json格式字串
string1 = '{"name":"Sim","gender":"Male","age":28,"province":"江蘇"}'
string2 = '{"name":"Lily","gender":"Feale","age":25,"province":"湖北"}'
# 檢視資料型別
type(string)
# 將json格式轉換為字典
dict1 = json.loads(string1) dict2 = json.loads(string2) type(dict1)
上面構造的json資料實際上是字典型的字串,可以直接通過json包中的loads函式完成由字元型到字典型的轉化。那如何根據這兩個字典,組裝成一個2行3列的資料框呢?只需藉助於pandas模組中的DataFrame函式即可:
# 將字典資料轉換為資料框
pd.DataFrame([dict1,dict2])
這裡需要注意的是,上面的字典,是一個鍵僅對應一個值的情況,如果直接將dict1傳遞給DataFrame函式是會出錯的,除非你指定索引值。所以,當你有兩個及以上的這種字典時,你是可以傳遞給DataFrame函式的,但必須以可迭代的形式(如列表、元組、序列等)。還有一種字典,是一個鍵對應多個值
string = '{"name":["Sim","Lily"],"gender":["Male","Feale"],\
"age":[28,25],"province":["江蘇","湖北"]}'
# 轉換為資料框
pd.DataFrame(json.loads(string))
儘管這樣完成了一個字典到資料框的轉換,但千萬注意,如果一個字典的鍵包含多個值,那一定要保證所有鍵對應的值個數一致!OK,瞭解了這個基礎知識點後,我們來兩個案例,加深一下對知識點的理解。
經典案例一
先來看一下Excel表中儲存的資料格式,現在的問題是,如何將表中UserBasic一列拆解出來,即所有鍵值對轉換成變數名和觀測值。
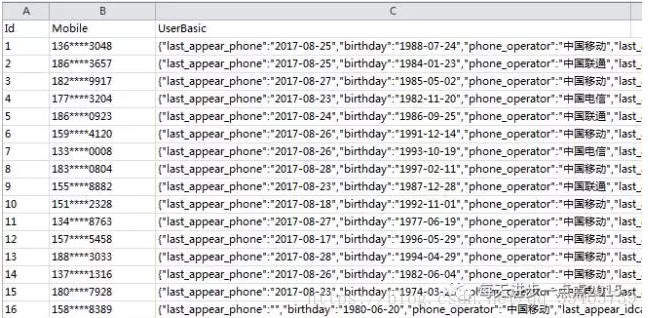
data1 = pd.read_excel(r'C:\Users\Administrator\Desktop\data1.xlsx')
data1.head()
data1.UserBasic[0]
從上面的反饋結果來看,表中UserBasic欄位的單元格儲存的json字串都是一個鍵僅對應一個值,這跟上面介紹的string1和string2是一致的,故如果需要轉換成資料框的話,需要將這些轉換的字典存放到列表中。具體操作如下:
# UserBasic列中的資訊拆分到各個變數中
basic = []for i in data1.UserBasic:
basic.append(json.loads(i))
UserBasic = pd.DataFrame(basic)
UserBasic.head()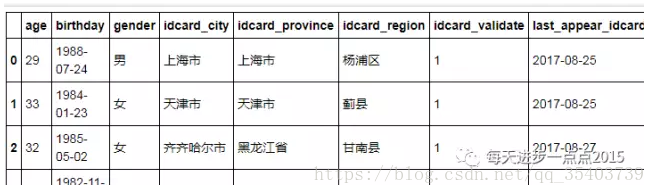
上面通過迴圈的方式將UserBasic欄位的每一行解析成字典,並儲存到列表中,最後通過DataFrame函式完成資料框的轉換。接下來需要將拆分出來的這列,與原始表中的Id變數,Mobile變數整合到一起。
# 資料整合到一起
final_data = pd.concat([data1[['Id','Mobile']],UserBasic], axis = 1)
final_data.head()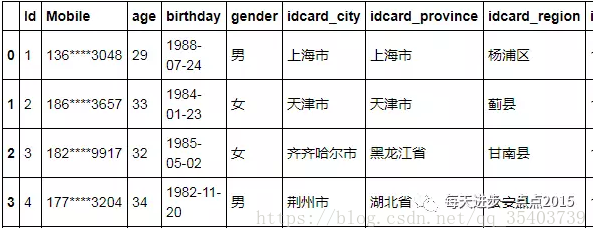
效果呈現還是蠻好的,但是有一點不好的是,通過for迴圈來完成畢竟不是高效的,如果資料量特別大,上百萬行的話,那就得迴圈執行上百萬次,會耗很多時間。這裡我們藉助於apply方法,避免顯式的迴圈:
# 避免迴圈的方式
trans_data = pd.DataFrame(data1.UserBasic.apply(json.loads))
# 資料整合到一起
final_data = pd.concat([data1[['Id','Mobile']],trans_data], axis = 1)經典案例二
我們接著看第二個例子,原始資料如下圖所示,現在的問題是在解析欄位CellBehaviorData的同時,還要做一次聚合操作(每個使用者ID近3個月的消費平均水平)。
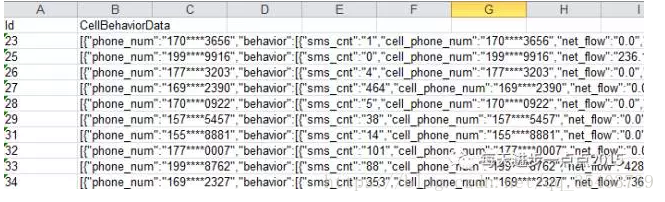
# 讀取資料
data2 = pd.read_excel(r'C:\Users\Administrator\Desktop\data2.xlsx')
# 檢視欄位CellBehaviorData第一行的資訊
data2.CellBehaviorData[0]
細心的你一定發現了個問題,這個字串的起始和結尾並不是大括號({}),而是中括號([]),故接下來要做的第一件事就是去除這兩個中括號;另一方面,behavior鍵對應的值是列表,而且列表中還有多個相同的鍵,如sms_cnt、cell_phone_num等。這樣的json最後形成的資料框一定是多行的,即表中一個單元格會就可以轉換成多行的資料框。不妨,我們先來看一下變數CellBehaviorData第一行形成是資料框張啥樣:
# 通過切片的方式去除首尾的中括號
s = data2.CellBehaviorData[0][1:-1]
# 將字串轉換成字典,並取出behavior鍵
d = json.loads(s)['behavior']
# 將字典轉換為資料框
df = pd.DataFrame(d)
df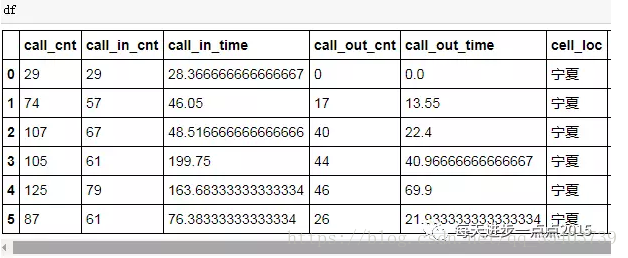
這就是一行觀測產生的多行資料框,現在的問題是如何將多行的資料框與每一個Id配對上。我們發現字典中除了behavior鍵,還有phone_num鍵,而且該鍵的值是唯一的,正好與上面資料框的cell_phone_num變數匹配。所以,待會做資料關聯的時候,就使用phone_num變數和cell_phone_num變數。
# 取出phone_num
phone_num = [i['phone_num'] for i in data2.CellBehaviorData.str[1:-1].apply(json.loads)]
# 取出CellBehaviorData欄位,並解析為資料框
df = pd.concat([pd.DataFrame(j) for j in [i['behavior'] for i in data2.CellBehaviorData.str[1:-1].apply(json.loads)]])# 將Id與手機號捆綁user = pd.concat([pd.Series(phone_num,name = 'phone_num'), data2.Id], axis = 1)
# 以手機號作為資料的關聯關聯
final_data = pd.merge(df, user, left_on = 'cell_phone_num', right_on='phone_num')
final_data.head()
# 檢視資料型別
final_data.dtypes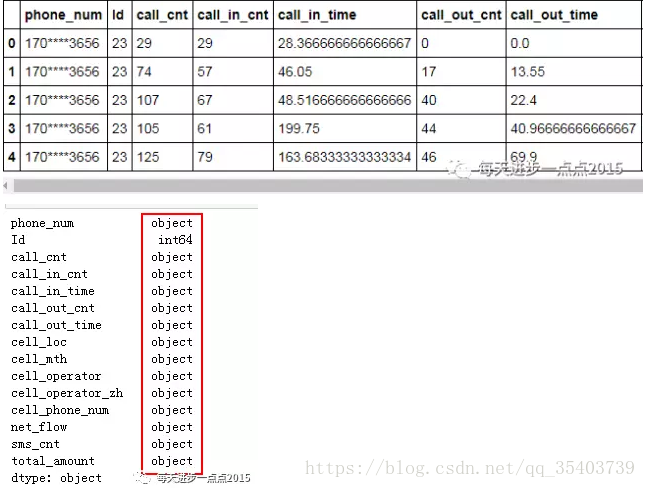
為了速度的提升,上面使用了apply技術和列表解析式的技巧將json資料拆解成資料框,同時,發現除Id變數的其他變數型別都是字串型,需要對數值變數進行轉換,因為接下來還要做聚合操作:
# 挑選需要轉換型別的變數名稱
vars = ['call_cnt','call_in_cnt','call_in_time','call_out_cnt','call_out_time','net_flow','sms_cnt','total_amount']
# 對以上變數進行資料型別轉換
df_convert = final_data[vars].apply(lambda x: x.astype('float'))
# 從新完成資料合併
final_data2 = pd.concat([df_convert, final_data.loc[:,~final_data.columns.isin(vars)]], axis = 1)
# 對每個id計算近三個月的平均指標值
stats = final_data2.loc[final_data2.cell_mth.isin(['2017-08','2017-07','2017-06']),:].groupby('Id').aggregate(np.mean)
stats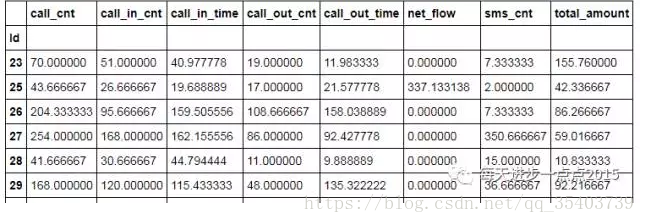
大功告成,這種型別的資料我們就可以遊刃有餘的完成轉換。但如果CellBehaviorData欄位不含有phone_num(鍵)變數的話,如何實現資料關聯呢?這裡把解決方案的程式碼呈現出來:
# 構造空列表,存放CellBehaviorData變數每一行形成的資料框
final_data = []
# 使用zip函式捆綁兩列,並使用for迴圈
for Id,CellBehaviorData in zip(data2.Id, data2.CellBehaviorData):
# 組裝資料框
mydf = pd.DataFrame(json.loads(CellBehaviorData[1:-1])['behavior'])
# 將資料框與變數Id組裝起來
final_data.append(pd.concat([pd.Series(np.repeat(Id,mydf.shape[0]), name = 'Id'),mydf], axis = 1))
#這個地方寫點自己看作者文件遇到的一些困難, 主要是repeat函式的用法np.repeat(Id,mydf.shape[0])表示的就是取Id的值然後複製mydf.shape[0]次
# 構造最終的資料框
final_data = pd.concat(final_data)# 資料型別轉換
# 挑選需要轉換型別的變數名稱
vars = ['call_cnt','call_in_cnt','call_in_time','call_out_cnt','call_out_time','net_flow','sms_cnt','total_amount']
# 對以上變數進行資料型別轉換
df_convert = final_data[vars].apply(lambda x: x.astype('float'))
# 從新完成資料合併
final_data2 = pd.concat([df_convert, final_data.loc[:,~final_data.columns.isin(vars)]], axis = 1)
final_data2
# 對每個id計算近三個月的平均指標值
stats = final_data2.loc[final_data2.cell_mth.isin(['2017-08','2017-07','2017-06']),:].groupby('Id').aggregate(np.mean)
stats雖然通過上面的方法可以實現資料的關聯和匹配,但個人覺得並不是很理想,因為這裡畢竟使用了for迴圈,一旦資料量大的話,執行起來會比較緩慢,如果高人,還請指點。
結語
OK,今天關於半結構化的json資料轉資料框的分享就介紹到到這裡,希望本篇文章對各位網友有一定的幫助。如果你有任何問題,歡迎在公眾號的留言區域表達你的疑問。歡迎各位朋友繼續轉發與分享文中的內容,讓更多的朋友學習和進步。有關文中的指令碼和資料可至下方的連結獲取,再次感謝網友對我的關注和支援。
關注“每天進步一點點2015”
相關材料下載連結
連結: https://pan.baidu.com/s/1kVzNnFp 密碼: tdkm