
騰訊雲的一道面試題----- 一致性Hash演算法
今天在面試騰訊的時候,被面試官問到一道題,之前只是瞭解過,卻沒有真正深入的瞭解,現在才知道自己的差距,要更加努力的補充這些技術知識了。下面是非常好的這塊的資料,和大家一起分享。
一致性 hash 演算法( consistent hashing )
張亮
consistent hashing 演算法早在 1997 年就在論文 中被提出,目前在cache 系統中應用越來越廣泛;
1 基本場景
比如你有 N 個 cache 伺服器(後面簡稱 cache ),那麼如何將一個物件 object 對映到 N 個 cache 上呢,你很可能會採用類似下面的通用方法計算 object 的 hash 值,然後均勻的對映到到 N 個 cache ;
hash(object)%N
一切都執行正常,再考慮如下的兩種情況;
1 一個 cache 伺服器 m down 掉了(在實際應用中必須要考慮這種情況),這樣所有對映到 cache m 的物件都會失效,怎麼辦,需要把 cache m 從 cache 中移除,這時候 cache 是 N-1 臺,對映公式變成了 hash(object)%(N-1);
2 由於訪問加重,需要新增 cache ,這時候 cache 是 N+1 臺,對映公式變成了 hash(object)%(N+1) ;
1 和 2 意味著什麼?這意味著突然之間幾乎所有的 cache 都失效了。對於伺服器而言,這是一場災難,洪水般的訪問都會直接衝向後臺伺服器;
再來考慮第三個問題,由於硬體能力越來越強,你可能想讓後面新增的節點多做點活,顯然上面的 hash 演算法也做不到。
有什麼方法可以改變這個狀況呢,這就是 consistent hashing...
2 hash 演算法和單調性
Hash 演算法的一個衡量指標是單調性( Monotonicity ),定義如下:
單調性是指如果已經有一些內容通過雜湊分派到了相應的緩衝中,又有新的緩衝加入到系統中。雜湊的結果應能夠保證原有已分配的內容可以被對映到新的緩衝中去,而不會被對映到舊的緩衝集合中的其他緩衝區。
容易看到,上面的簡單 hash 演算法 hash(object)%N 難以滿足單調性要求。
3 consistent hashing 演算法的原理
consistent hashing 是一種 hash 演算法,簡單的說,在移除 / 新增一個 cache 時,它能夠儘可能小的改變已存在 key 對映關係,儘可能的滿足單調性的要求。
下面就來按照 5 個步驟簡單講講 consistent hashing 演算法的基本原理。
3.1 環形hash 空間
考慮通常的 hash 演算法都是將 value 對映到一個 32 為的 key 值,也即是 0~2^32-1 次方的數值空間;我們可以將這個空間想象成一個首( 0 )尾( 2^32-1 )相接的圓環,如下面圖 1 所示的那樣。

圖 1 環形 hash 空間
3.2 把物件對映到hash 空間
接下來考慮 4 個物件 object1~object4 ,通過 hash 函式計算出的 hash 值 key 在環上的分佈如圖 2 所示。
hash(object1) = key1;
… …
hash(object4) = key4;

圖 2 4 個物件的 key 值分佈
3.3 把cache 對映到hash 空間
Consistent hashing 的基本思想就是將物件和 cache 都對映到同一個 hash 數值空間中,並且使用相同的 hash演算法。
假設當前有 A,B 和 C 共 3 臺 cache ,那麼其對映結果將如圖 3 所示,他們在 hash 空間中,以對應的 hash 值排列。
hash(cache A) = key A;
… …
hash(cache C) = key C;

圖 3 cache 和物件的 key 值分佈
說到這裡,順便提一下 cache 的 hash 計算,一般的方法可以使用 cache 機器的 IP 地址或者機器名作為 hash輸入。
3.4 把物件對映到cache
現在 cache 和物件都已經通過同一個 hash 演算法對映到 hash 數值空間中了,接下來要考慮的就是如何將物件對映到 cache 上面了。
在這個環形空間中,如果沿著順時針方向從物件的 key 值出發,直到遇見一個 cache ,那麼就將該物件儲存在這個 cache 上,因為物件和 cache 的 hash 值是固定的,因此這個 cache 必然是唯一和確定的。這樣不就找到了物件和 cache 的對映方法了嗎?!
依然繼續上面的例子(參見圖 3 ),那麼根據上面的方法,物件 object1 將被儲存到 cache A 上; object2 和object3 對應到 cache C ; object4 對應到 cache B ;
3.5 考察cache 的變動
前面講過,通過 hash 然後求餘的方法帶來的最大問題就在於不能滿足單調性,當 cache 有所變動時, cache會失效,進而對後臺伺服器造成巨大的衝擊,現在就來分析分析 consistent hashing 演算法。
3.5.1 移除 cache
考慮假設 cache B 掛掉了,根據上面講到的對映方法,這時受影響的將僅是那些沿 cache B 逆時針遍歷直到下一個 cache ( cache C )之間的物件,也即是本來對映到 cache B 上的那些物件。
因此這裡僅需要變動物件 object4 ,將其重新對映到 cache C 上即可;參見圖 4 。

圖 4 Cache B 被移除後的 cache 對映
3.5.2 新增 cache
再考慮新增一臺新的 cache D 的情況,假設在這個環形 hash 空間中, cache D 被對映在物件 object2 和object3 之間。這時受影響的將僅是那些沿 cache D 逆時針遍歷直到下一個 cache ( cache B )之間的物件(它們是也本來對映到 cache C 上物件的一部分),將這些物件重新對映到 cache D 上即可。
因此這裡僅需要變動物件 object2 ,將其重新對映到 cache D 上;參見圖 5 。

圖 5 新增 cache D 後的對映關係
4 虛擬節點
考量 Hash 演算法的另一個指標是平衡性 (Balance) ,定義如下:
平衡性
平衡性是指雜湊的結果能夠儘可能分佈到所有的緩衝中去,這樣可以使得所有的緩衝空間都得到利用。
hash 演算法並不是保證絕對的平衡,如果 cache 較少的話,物件並不能被均勻的對映到 cache 上,比如在上面的例子中,僅部署 cache A 和 cache C 的情況下,在 4 個物件中, cache A 僅儲存了 object1 ,而 cache C 則儲存了object2 、 object3 和 object4 ;分佈是很不均衡的。
為了解決這種情況, consistent hashing 引入了“虛擬節點”的概念,它可以如下定義:
“虛擬節點”( virtual node )是實際節點在 hash 空間的複製品( replica ),一實際個節點對應了若干個“虛擬節點”,這個對應個數也成為“複製個數”,“虛擬節點”在 hash 空間中以 hash 值排列。
仍以僅部署 cache A 和 cache C 的情況為例,在圖 4 中我們已經看到, cache 分佈並不均勻。現在我們引入虛擬節點,並設定“複製個數”為 2 ,這就意味著一共會存在 4 個“虛擬節點”, cache A1, cache A2 代表了cache A ; cache C1, cache C2 代表了 cache C ;假設一種比較理想的情況,參見圖 6 。

圖 6 引入“虛擬節點”後的對映關係
此時,物件到“虛擬節點”的對映關係為:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此物件 object1 和 object2 都被對映到了 cache A 上,而 object3 和 object4 對映到了 cache C 上;平衡性有了很大提高。
引入“虛擬節點”後,對映關係就從 { 物件 -> 節點 } 轉換到了 { 物件 -> 虛擬節點 } 。查詢物體所在 cache 時的對映關係如圖 7 所示。
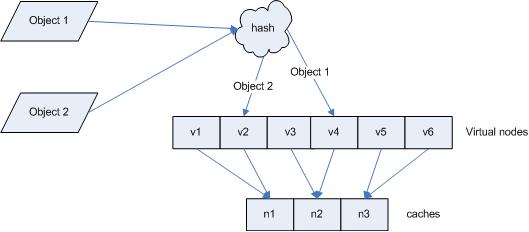
圖 7 查詢物件所在 cache
“虛擬節點”的 hash 計算可以採用對應節點的 IP 地址加數字字尾的方式。例如假設 cache A 的 IP 地址為202.168.14.241 。
引入“虛擬節點”前,計算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虛擬節點”後,計算“虛擬節”點 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2
5 小結
Consistent hashing 的基本原理就是這些,具體的分佈性等理論分析應該是很複雜的,不過一般也用不到。