
mysql覆蓋索引詳解
如果一個索引包含(或覆蓋)所有需要查詢的欄位的值,稱為‘覆蓋索引’。即只需掃描索引而無須回表。
只掃描索引而無需回表的優點:
1.索引條目通常遠小於資料行大小,只需要讀取索引,則mysql會極大地減少資料訪問量。
2.因為索引是按照列值順序儲存的,所以對於IO密集的範圍查詢會比隨機從磁碟讀取每一行資料的IO少很多。
3.一些儲存引擎如myisam在記憶體中只快取索引,資料則依賴於作業系統來快取,因此要訪問資料需要一次系統呼叫
4.innodb的聚簇索引,覆蓋索引對innodb表特別有用。(innodb的二級索引在葉子節點中儲存了行的主鍵值,所以如果二級主鍵能夠覆蓋查詢,則可以避免對主鍵索引的二次查詢)
覆蓋索引必須要儲存索引列的值,而雜湊索引、空間索引和全文索引不儲存索引列的值,所以mysql只能用B-tree索引做覆蓋索引。
當發起一個索引覆蓋查詢時,在explain的extra列可以看到using index的資訊
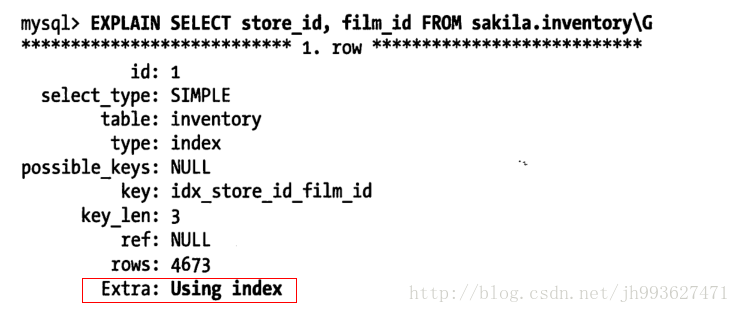
覆蓋索引的坑:mysql查詢優化器會在執行查詢前判斷是否有一個索引能進行覆蓋,假設索引覆蓋了where條件中的欄位,但不是整個查詢涉及的欄位,mysql5.5和之前的版本也會回表獲取資料行,儘管並不需要這一行且最終會被過濾掉。

如上圖則無法使用覆蓋查詢,原因:
1.沒有任何索引能夠覆蓋這個索引。因為查詢從表中選擇了所有的列,而沒有任何索引覆蓋了所有的列。
2.mysql不能在索引中執行LIke操作。mysql能在索引中做最左字首匹配的like比較,但是如果是萬用字元開頭的like查詢,儲存引擎就無法做比較匹配。這種情況下mysql只能提取資料行的值而不是索引值來做比較
優化後SQL:新增索引(artist,title,prod_id),使用了延遲關聯(延遲了對列的訪問)

說明:在查詢的第一階段可以使用覆蓋索引,在from子句中的子查詢找到匹配的prod_id,然後根據prod_id值在外層查詢匹配獲取需要的所有值。
5.5時API設計不允許mysql將過濾條件傳到儲存引擎層(是把資料從儲存引擎拉到伺服器層,在根據條件過濾),5.6之後由於ICP這個特性改善了查詢執行方式