
MYSQL學習(三) --索引詳解
建立高效能索引
(一)索引簡介
-
索引的定義
索引,在資料結構的查詢那部分知識中有專門的定義。就是把關鍵字和它對應的記錄關聯起來的過程。索引由若干個索引項組成。每個索引項至少包含兩部分內容。關鍵字和關鍵字對應記錄在儲存器位置資訊。索引是組織磁碟檔案的一種重要的技術。
資料庫的資料量通常比較大,都是儲存在磁碟上。通過儲存引擎對磁碟檔案的資料進行管理。而索引是儲存引擎御用快速找到記錄的一種資料結構。
2.索引的優點
(1)大大減少伺服器需要掃描的資料量。
(2)索引可以幫助伺服器避免排序和臨時表。
(3)索引可以將隨機IO轉換成順序IO。
3.索引三星系統原則
(1)第一星:索引將相關的記錄放在一起。即在一系列必要的列上建立索引,不必為where條件裡的所有得列建立索引。
(2)第二星:索引中資料的順序和排序要求的資料的順序一致。通常將選擇性更高的列放在索引列的最前面。
(3)第三星:索引中的列包含查詢所需要的所有列。因為索引中已經包含查詢所需的全部欄位,所以不需要在進行行查詢(覆蓋索引的定義)。
(二)索引型別
其中,索引是在儲存引擎層實現的。因此,不同的執行引擎,自己選擇使用實現自己的索引型別。
1.B-Tree 索引
(1)B+樹資料結構
B+樹的定義是在B樹的基礎之上定義的。相比B+樹,區別部分有兩點。
A.非葉子結點只存key,不儲存指向資料的指標(ROWID)。
B.葉子結點都儲存一個指向相鄰節點的指標。
區別A.非葉子節點不儲存ROWID,索引項更小。一塊可以儲存更多的索引項。所以,可以儲存更多的非葉子索引項。一個索引項能定位更多的葉子結點。
區別B.葉子節點根據指標連結,範圍查詢非常簡單(如果是B樹結構的話,範圍查詢需要 葉子節點和內部結點之間不停的往返)。
(2)使用B+樹索引的儲存引擎
InnoDB和MyISAM。
B+樹索引是邏輯結構是B+樹、物理儲存結構是鏈式儲存。
(3)B+樹索引適合的查詢型別
- 鍵值範圍
- 鍵字首查詢(只使用最左字首查詢)
- 只訪問索引的查詢(覆蓋索引)
- 全鍵值
其實是覆蓋索引。即索引中的欄位能覆蓋查詢語句中的全部欄位(包括分組、排序欄位)。
2. 雜湊索引
雜湊索引是線性索引。是基於雜湊表實現。只有精確匹配索引的所有列的查詢才有效。
雜湊索引儲存在雜湊表中。邏輯結構是線性表,物理儲存結構是順序儲存。
不同的key通過雜湊函式計算,可能產生相同的結果。即衝突。雜湊索引用的衝突解決演算法是鏈地址法(索引相同的記錄指標放在一個連結串列中)
索引表是線性表的順序儲存。儲存在連續的儲存空間中。
(1).雜湊索引的索引項包含雜湊值和行指標。
雜湊值:由索引列按照雜湊函式計算,獲得的雜湊值。
行指標:當前雜湊值對應的行的指標。
(2).雜湊索引特點
- 雜湊索引只包含雜湊值和行指標。不包含其它列資訊。因此,無法避免讀取行(無法實現覆蓋索引)。
- 雜湊索引的索引項不是按照索引值順序儲存的。所以,無法避免排序。
- 雜湊索引不支援索引列的匹配查詢。
3. 全文索引
全文索引和雜湊索引一樣,也是一種執行緒索引。本質是倒序索引。
4.B+樹索引和雜湊索引的區別
- 雜湊索引的特殊性,索引的檢索可以一次定位。而B樹索引的檢索需要工根節點到樹枝結點,最後再到葉子結節點。這樣多次IO訪問。所以,雜湊索引的效率遠高於B樹索引。
- 雜湊索引無法避免排序(按照雜湊碼順序儲存的,不是按照索引列進行順序儲存的)。B樹索引在特殊情況下是可以避免排序操作的(索引列作為索引key)。
- 雜湊索引只能使用全部索引鍵來查詢,不能用部分索引鍵來查詢。(雜湊函式是一種對應關係,所以,必須要所有的引數才能得到雜湊碼,部分索引建是不可以的)
(三)高效能索引策略
1.獨立的列
索引列不能是表示式,也不能是函式。
例如:SELECT actor_id FROM actor WHERE actor_id+1=5 這種寫法,就算在actor_id上建立了索引,也不起效。索引列actor_id需要是獨立的列才可以。
2.多列索引
多列索引也叫符合索引。即同時對多個列建立索引。比如(A,B,C)。
(1). 需要使用多列索引的場景
- 伺服器需要對多個索引進行相交運算(通常是AND條件)。
- 伺服器需要對多個索引進行聯合操作(通常是OR條件)。
(2).多列索引的生效規則
比如(a,b,c),a,b,c都是排好序的。在任何一段a的下面b都是排好序的。在任何一段b的下面c都是排好序的。多列索引生效原則是從前向後依次生效。如果中間索引列沒有起作用,則該索引列之前的索引列起作用。
例如 (1)select * from mytable where a=3 and b>7 and c=3; --a用到了,b也用到了,c沒有用到,這個地方b是範圍值,也算斷點,只不過自身用到了索引。
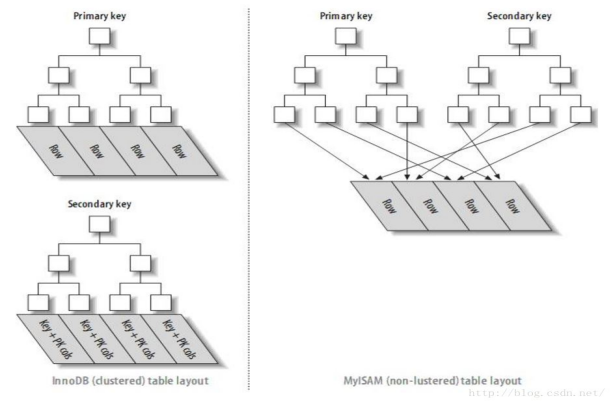
3.聚簇索引
聚簇索引:不是一種索引型別,是一種資料儲存方式。
InnoDB的聚簇索引,在同一個結構中儲存了B-Tree索引和資料行。
當表有聚簇索引的時候,它的資料實際上是儲存在索引的葉子頁(leaf page)中。資料只有一份,所以,一個表只有一個聚簇索引。聚簇是指鍵值相鄰的資料行緊簇的儲存在一起。
聚簇索引的葉子節點也是資料節點。而非聚簇索引的葉子結點仍然是索引節點。只不過,它有指向對應資料塊的指標。
(1).聚簇索引和二級索引
-
聚簇索引的定義
在InnoDB中,聚簇索引就是主鍵索引。如果表中沒有定義主鍵,則InnoDB選擇一個唯一的非空索引作為主鍵。如果沒有這樣的索引,InnoDB會隱式的定義一個主鍵來做聚簇索引。
2.聚簇索引特徵
資料儲存和索引放在一起,找到索引,就找到資料。
由於聚簇索引是將資料跟索引結構放到一塊,因此一個表僅有
二級索引定義
非主鍵索引就是二級索引。
二級索引特徵
將資料儲存和索引儲存分開的結構,索引結構的葉子節點指向資料的對應行。
在InnoDB儲存引擎中,在聚簇索引之上建立的索引稱之為輔助索引。即二級索引。輔助索引總是需要二次查詢的。輔助索引葉子結點儲存的不是行的物理位置,而是主鍵值。(然後根據主鍵值去聚簇索引中查詢資料)
(2).MyISAM和InnoDB的主鍵索引、二級索引對照圖
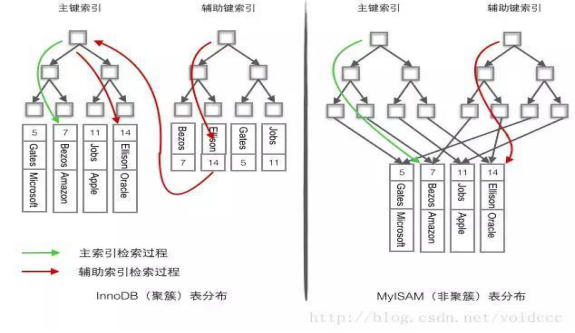
熟悉兩種引擎的資料和索引分佈,就真正理解了MYSQL的儲存和索引查詢。
- MyISAM資料分佈
如上圖所示,MyISAM的資料和索引分開儲存的。MyISAM是按照插入的順序,順序的儲存在磁碟上。類似陣列那樣順序儲存。
2. MyISAM索引
它對應的不論主鍵索引還是二級索引,都是典型的B+樹索引形式。葉子結點對應的是行指標(行在磁碟中的具體位置)。
3. InnoDB資料分佈
如上圖所示,InnoDB支援聚簇索引。其中,聚簇索引就是資料。在聚簇索引的葉子節點上,除了主鍵外,還有事務ID,回滾指標和其餘非主鍵欄位。所以,通過主鍵索引可以直接找到資料.
4. InnoDB主鍵索引
InnoDB的主鍵索引和資料分佈內容一樣。主鍵索引就是其資料分佈。
5.InnoDB二級索引
二級索引也是標準的B樹索引。只是葉子結點指的不是行指標,而是主鍵值。所以,整個葉子結點的索引項是[key+主鍵]。
6. 聚簇索引的選擇和重建
聚簇索引預設是按照主鍵建立的主鍵索引。如果沒有定義主鍵,InnoDB會選擇一個唯一的非空索引替代。
InnoDB的資料插入是按照主鍵順序插入行的。
4.覆蓋索引
如果一個索引包含(或者說覆蓋)查詢的所有欄位(查詢欄位和where條件欄位)的值,我們稱之為覆蓋索引。【由此可見,覆蓋索引是索引的一個分類而已】
覆蓋索引效率高的幾個原因
- 覆蓋索引,只需要查詢索引,不需要二次查詢資料行。少一次操作。
- 覆蓋索引是按照索引欄位順序儲存。因而,支援範圍查詢。
5.使用索引掃描來排序
核心思路是:因為索引是有序的。如果排序要求的順序和索引的順序一致,就可以直接使用索引的順序。從而減少對排序的操作。
ORDER BY和查詢型查詢的限制是一樣的:需要滿足索引的最左字首原則,否則,MySQL無法使用索引排序。但有一個特殊情況:就是前導列為常量。例如,有一個索引為(A,B,C),那麼這樣的SQL語句也會用索引排序。
select id from table where A=2 order by B,C;
第一個索引列A為常量2,2後面對應的B,C也是有序的。所以,這個查出的資料是有序的。
select id from table where A>2 order by B,C; 這個不可以。
(四)維護索引和表
索引如此重要,所以需要對索引和表進行實時維護。確保索引正常工作。
1.找到並修復損壞的表
檢查:通過CHECK TABLE來檢查引擎是否發生表損壞。
維修:使用 ALTER TABLE innoDB_tbl ENGINE = INNODB;
2.更新索引統計資訊
ANALYZE TABLE
3.減少索引和資料碎片
資料儲存的碎片有
(1).行碎片
資料行被存在多個地方的多個片段中。
(2).行間碎片
邏輯上順序的也,或者行在磁碟上不是順序儲存的。行間碎片對全表掃描和聚簇索引掃描影響較大。
(3).剩餘空間碎片
資料頁中有大量的剩餘空間。從而導致伺服器讀取大量不需要的資料。
修復: OPTIMIZE TABLE ;或者 ALTER TABLE innoDB_tbl ENGINE= <engine>;
(五)為什麼 絕大多數索引選擇B+樹?
MYSQL查詢的本質是在一個數據集合中的查詢資料。查詢常見方式以及場景如下
1.順序查詢,場景:無序,資料量較小。
2.折半(二分)查詢,場景:順序線性表儲存。資料量較小。
3.二叉樹查詢(AVL):場景:二叉樹或者平衡二叉樹儲存(有序鏈式儲存),資料量中等或者較小。
4.多路查詢樹(B樹或B+樹):場景:B+樹儲存(有序儲存),可以處理資料量很大的資料。
因為B樹儲存可以讓樹的階(深度)控制在較小的分為內。階(深度)每少一層,查詢就會少一次索引的獲取。因而,B樹這個型別的儲存是MYSQL選擇索引資料結構的一個很好的方案。
為什麼選擇B+樹而不是B樹?
- B+樹非葉子結點不存資料,所以,可以儲存更多的結點,因而,樹的階就越小。從樹形上來看越矮胖。可以較少IO操作。
- 葉子結點都新增一個指向相鄰葉子的指標。範圍掃描更容易。