
真是乾貨,一文教你怎麼寫爬蟲!
資料是創造和決策的原材料,高質量的資料都價值不菲。而利用爬蟲,我們可以獲取大量的價值資料,經分析可以發揮巨大的價值,比如:
豆瓣、知乎:爬取優質答案,篩選出各話題下熱門內容,探索使用者的輿論導向。
淘寶、京東:抓取商品、評論及銷量資料,對各種商品及使用者的消費場景進行分析。
搜房、鏈家:抓取房產買賣及租售資訊,分析房價變化趨勢、做不同區域的房價分析。
拉勾、智聯:爬取各類職位資訊,分析各行業人才需求情況及薪資水平。
雪球網:抓取雪球高回報使用者的行為,對股票市場進行分析和預測。

爬蟲是入門Python最好的方式,沒有之一。Python有很多應用的方向,比如後臺開發、web開發、科學計算等等,但爬蟲對於初學者而言更友好,原理簡單,幾行程式碼就能實現基本的爬蟲,學習的過程更加平滑,你能體會更大的成就感。
掌握基本的爬蟲後,你再去學習Python資料分析、web開發甚至機器學習,都會更得心應手。因為這個過程中,Python基本語法、庫的使用,以及如何查詢文件你都非常熟悉了。
何為爬蟲?簡單來講,爬蟲就是一個探測機器,它的基本操作就是模擬人的行為去各個網站溜達,點點按鈕,查查資料,或者把看到的資訊揹回來。就像一隻蟲子在一幢樓裡不知疲倦地爬來爬去。
今天我們來講一個爬蟲例項。爬取噹噹網資料以及圖片。
一、首先我們需要安裝python環境
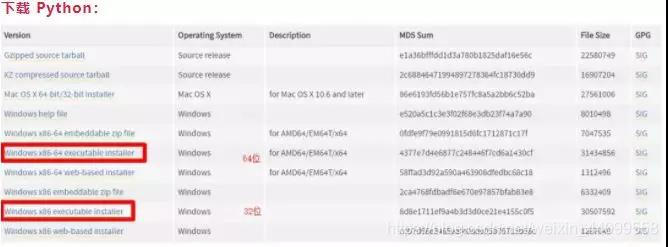
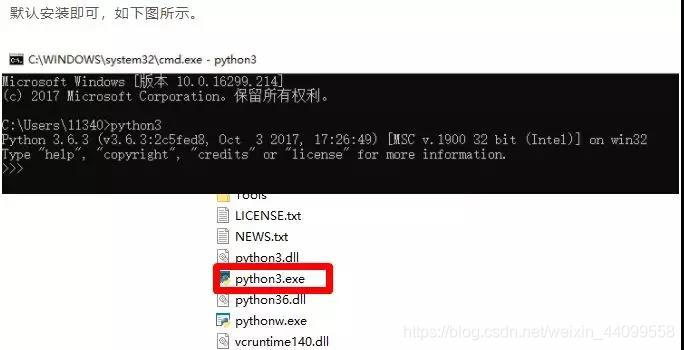
二、安裝編輯器,這裡我們就選pycharm吧,安裝只需要預設選擇即可。
1.第一種安裝庫模組的方式為:開啟 Pycharm IDE,選擇 file-Settings,如下圖所示
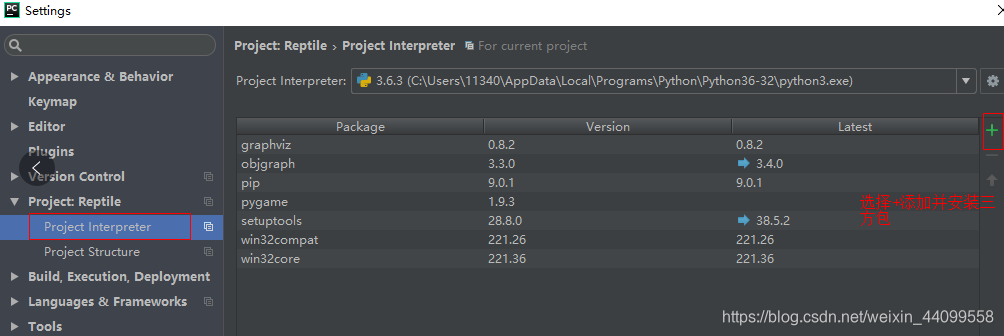
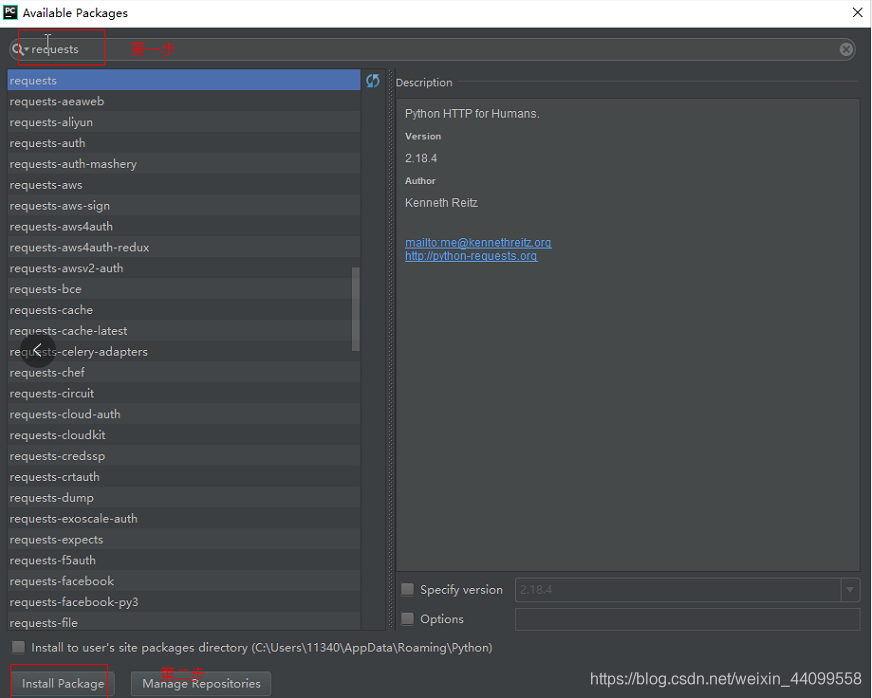
這時我們選擇右方的"+"符號,如下圖所示:
三、上程式碼!我們用的是scrapy框架~
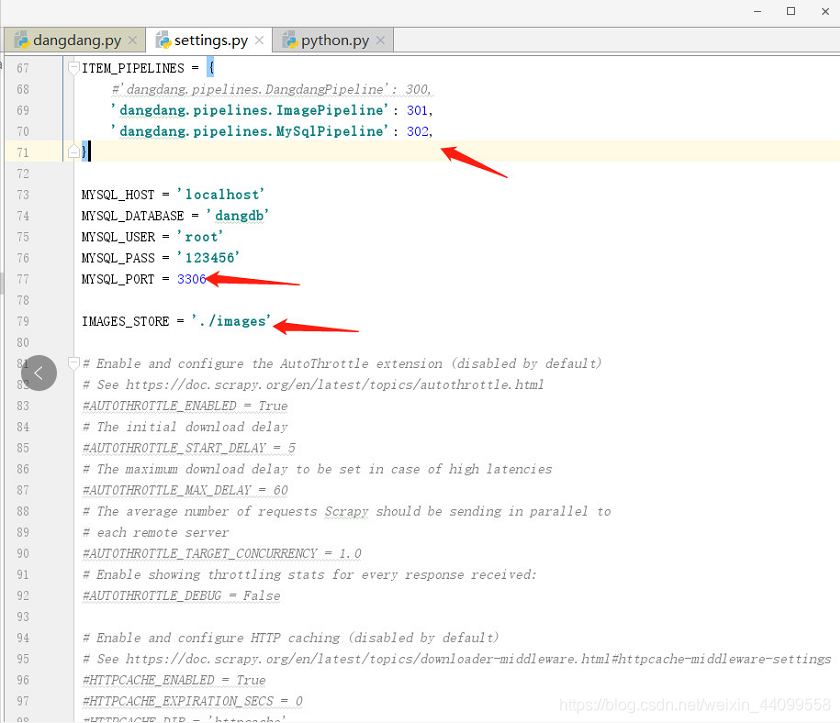
1.首先設定settings包括設定資料庫基礎資訊,你的pipeline,還有圖片下載位置
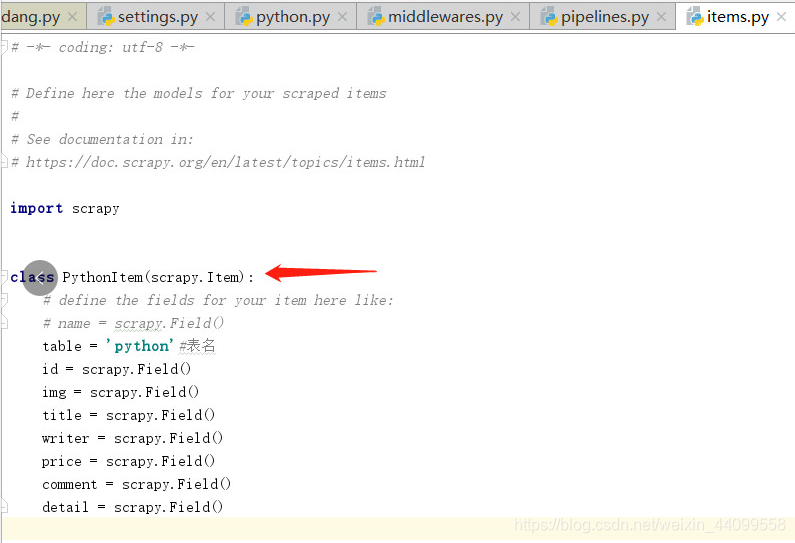
2.item設定存入資料庫欄位為後期存入資料庫做準備
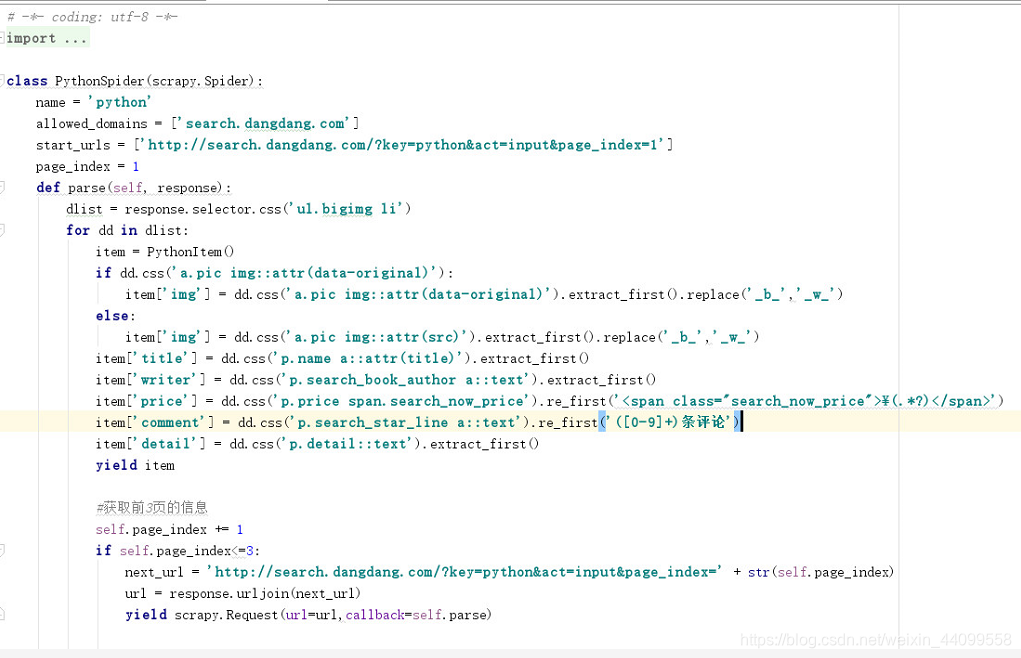
3.spider.py檔案,主要通過請求地址,傳送請求,將返回資料返回到parse方法,在parse方法中利用選擇器去選擇我們需要存入資料庫的欄位,以及設定需要爬去多少頁
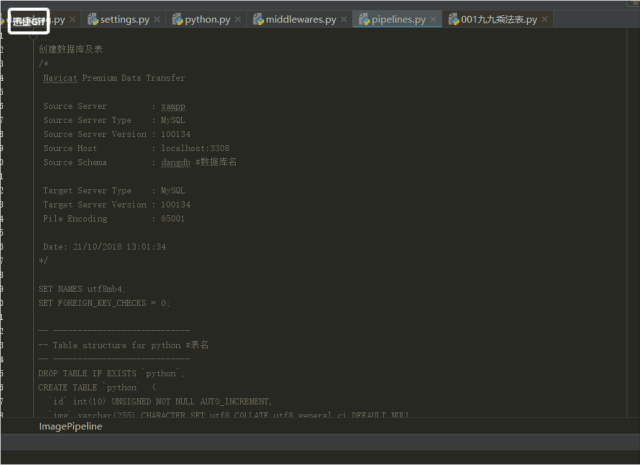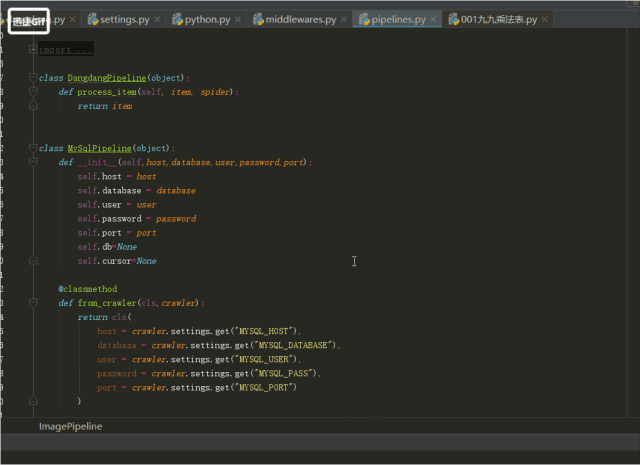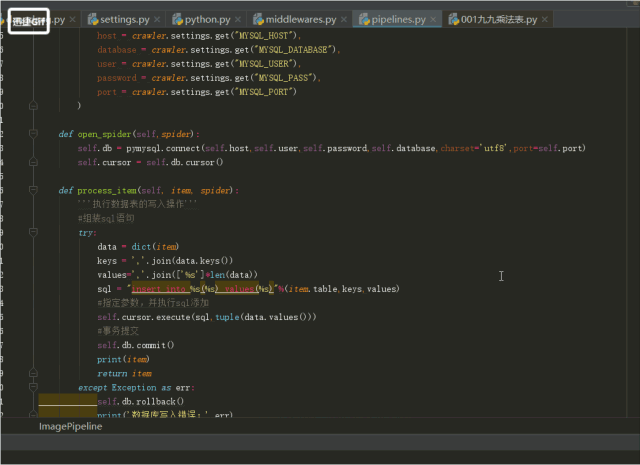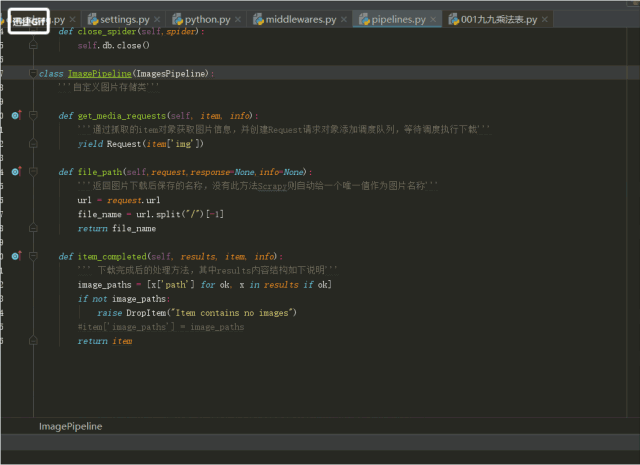
4.pipeline是用儲存資料的檔案,將資料存入資料庫,操作資料的
5.執行
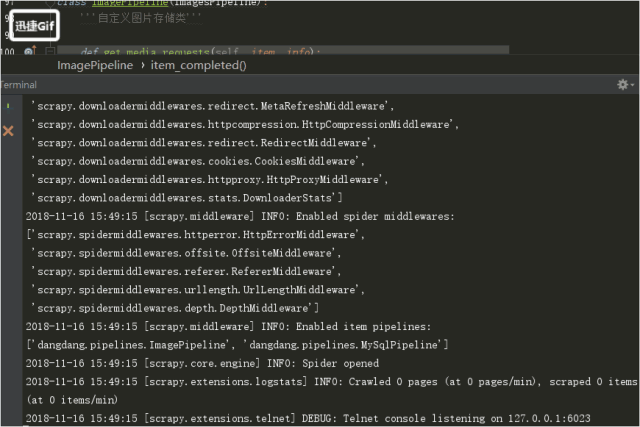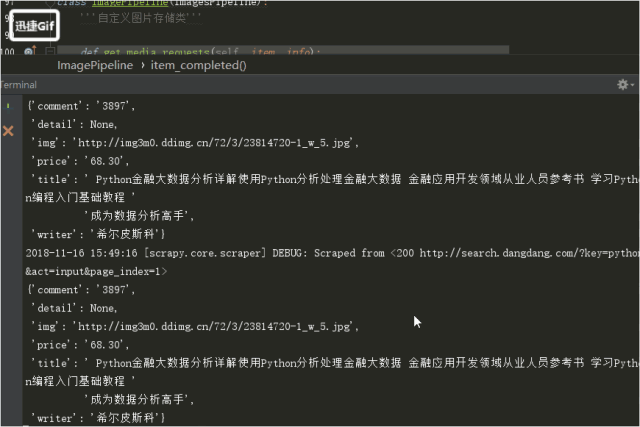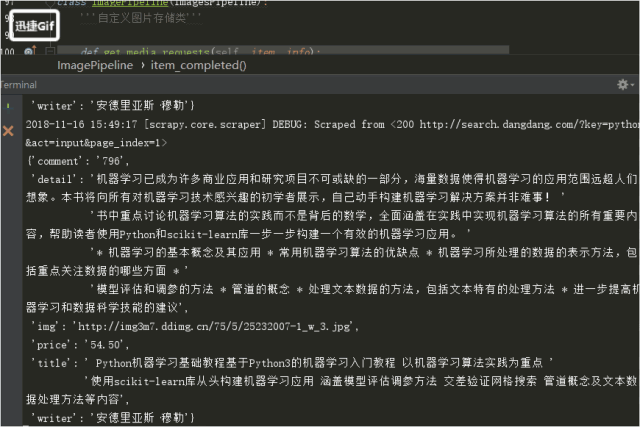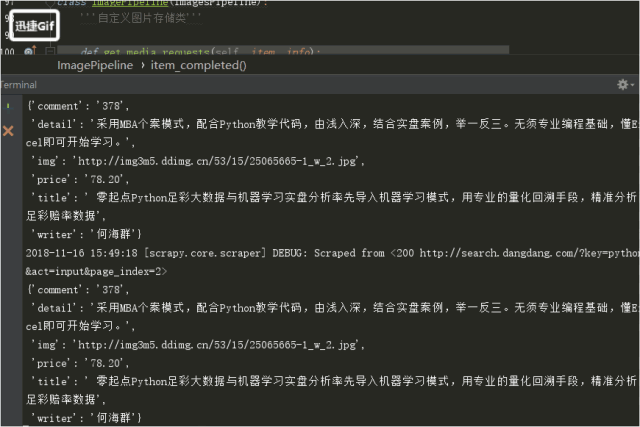
結果!!!!
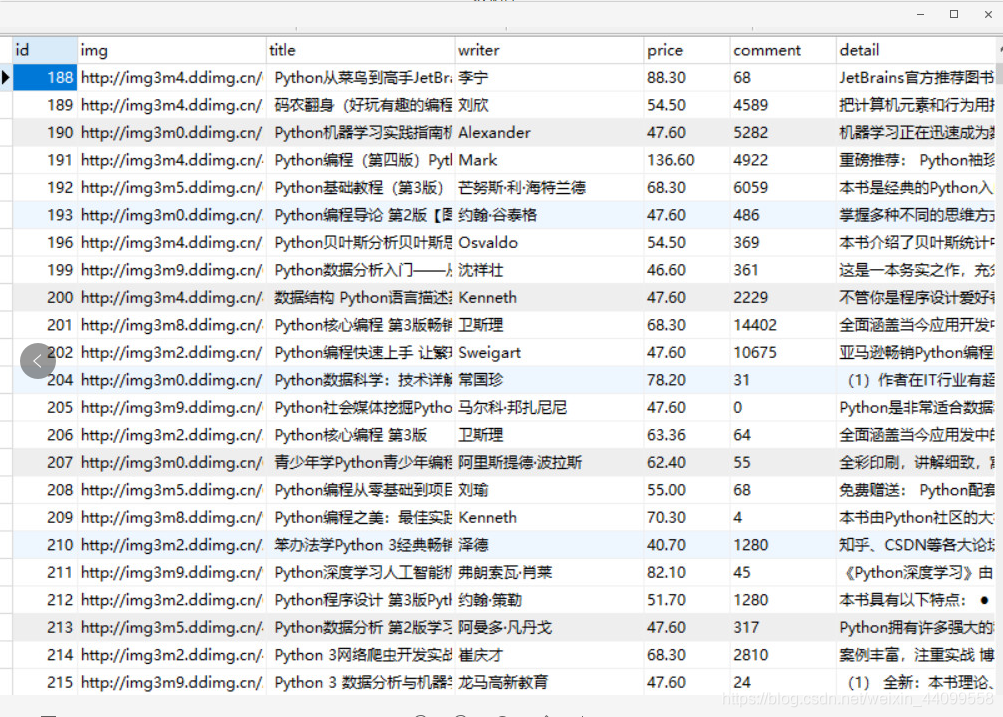
資料庫
爬取的圖片
這樣爬取資訊效率很高噠~你看,這一條學習路徑下來,你已然可以成為老司機了,非常的順暢。所以在一開始的時候,儘量不要系統地去啃一些東西,找一個實際的專案(開始可以從豆瓣、小豬這種簡單的入手),直接開始就好。