
pytorch中網路loss傳播和引數更新理解
相比於2018年,在ICLR2019提交論文中,提及不同框架的論文數量發生了極大變化,網友發現,提及tensorflow的論文數量從2018年的228篇略微提升到了266篇,keras從42提升到56,但是pytorch的數量從87篇提升到了252篇。
TensorFlow: 228--->266
Keras: 42--->56
Pytorch: 87--->252
在使用pytorch中,自己有一些思考,如下:
1. loss計算和反向傳播
import torch.nn as nn criterion = nn.MSELoss().cuda() output = model(input) loss = criterion(output, target) loss.backward()
通過定義損失函式:criterion,然後通過計算網路真是輸出和真實標籤之間的誤差,得到網路的損失值:loss;
最後通過loss.backward()完成誤差的反向傳播,通過pytorch的內在機制完成自動求導得到每個引數的梯度。
需要注意,在機器學習或者深度學習中,我們需要通過修改引數使得損失函式最小化或最大化,一般是通過梯度進行網路模型的引數更新,通過loss的計算和誤差反向傳播,我們得到網路中,每個引數的梯度值,後面我們再通過優化演算法進行網路引數優化更新。
2. 網路引數更新
在更新網路引數時,我們需要選擇一種調整模型引數更新的策略,即優化演算法。
優化演算法中,簡單的有一階優化演算法:
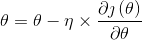
其中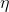
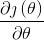
自己的理解是,對於複雜的優化演算法,基本原理也是這樣的,不過計算更加複雜。
在pytorch中,torch.optim是一個實現各種優化演算法的包,可以直接通過這個包進行呼叫。
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)注意:1)在前面部分1中,已經通過loss的反向傳播得到了每個引數的梯度,然後再本部分通過定義優化器(優化演算法),確定了網路更新的方式,在上述程式碼中,我們將模型的需要更新的引數傳入優化器。
2)注意優化器,即optimizer中,傳入的模型更新的引數,對於網路中有多個模型的網路,我們可以選擇需要更新的網路引數進行輸入即可,上述程式碼,只會更新model中的模型引數。對於需要更新多個模型的引數的情況,可以參考以下程式碼:
optimizer = torch.optim.Adam([{'params': model.parameters()}, {'params': gru.parameters()}], lr=0.01)3) 在優化前需要先將梯度歸零,即optimizer.zeros()。
3. loss計算和引數更新
import torch.nn as nn
import torch
criterion = nn.MSELoss().cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
output = model(input)
loss = criterion(output, target)
optimizer.zero_grad() # 將所有引數的梯度都置零
loss.backward() # 誤差反向傳播計算引數梯度
optimizer.step() # 通過梯度做一步引數更新