
hadoop原始碼包編譯驗證 snappy 詳細流程
阿新 • • 發佈:2019-01-10
下載安裝依賴包
yum -y install lzo-devel zlib-devel gcc gcc-c++ autoconf automake libtool openssl-devel fuse-devel cmake
使用root使用者安裝protobuf ,進入protobuf解壓路徑
./configure
make && make install

使用root使用者安裝snappy1.1.1
下載地址
http://www.filewatcher.com/m/snappy-1.1.1.tar.gz.1777992-0.html
進入snappy1.1.1解壓路徑
./configure
make && make install
驗證是否安裝完成
ll /usr/local/lib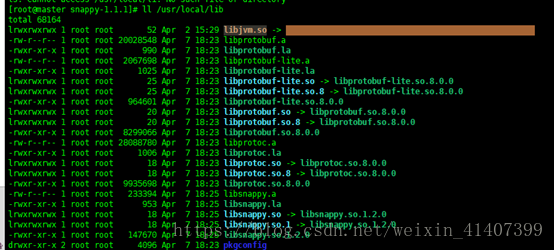
修改mavne 配置檔案,使用阿里雲伺服器,加快編譯速度
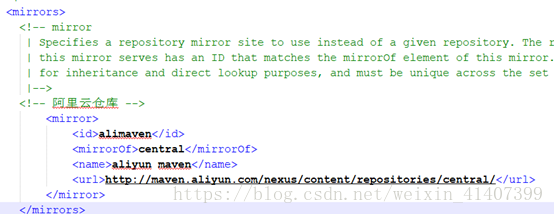
<mirrors> <!-- mirror | Specifies a repository mirror site to use instead of a given repository. The repository that | this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used | for inheritance and direct lookup purposes, and must be unique across the set of mirrors. |--> <!-- 阿里雲倉庫 --> <mirror> <id>alimaven</id> <mirrorOf>central</mirrorOf> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/repositories/central/</url> </mirror> </mirrors>
解壓原始碼包,cdh版本hadoop原始碼包下載地址
http://archive-primary.cloudera.com/cdh5/cdh/5/

進入hadoop 原始碼所在資料夾
輸入指令開始編譯,大約1個小時時間
mvn clean package -DskipTests -Pdist,native -Dtar -Drequire.snappy -e -X
編譯完成
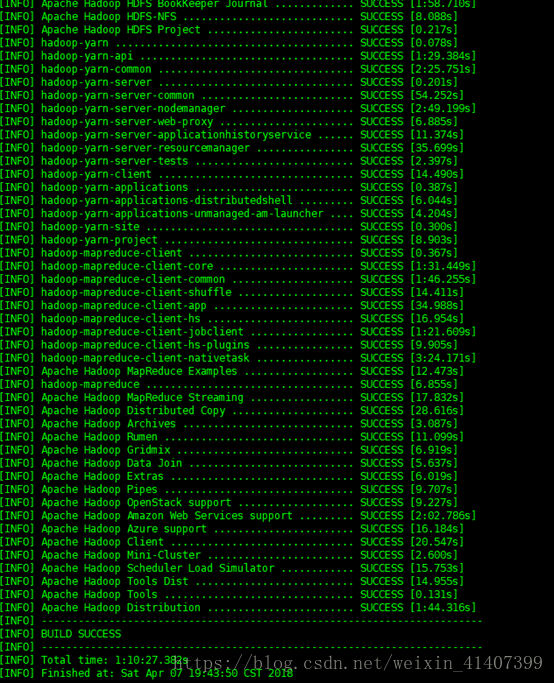
將hadoop-dist/target/hadoop-2.5.0-cdh5.3.6/lib/native複製到hadoop_home下lib/native 裡

使用hadoop checknative 檢視
hadoop checknative
測試 ,建立表
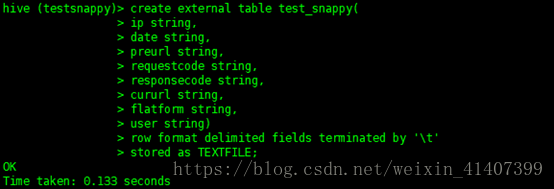
匯入資料

檢視檔案大小,2m

設定輸出壓縮格式為snappy
SET hive.exec.compress.output=true;
SET mapred.compress.map.output=true;
SET mapred.output.compress=true;
SET mapred.output.compression=org.apache.hadoop.io.compress.SnappyCodec;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
SET io.compression.codecs=org.apache.hadoop.io.compress.SnappyCodec;

建立snappy格式表

匯入資料成功
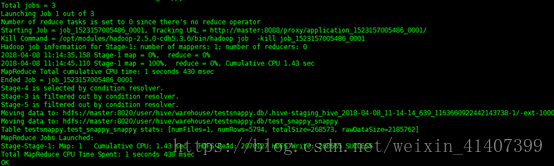
檢視hdfs上檔案,snappy格式檔案已經生產

檢視檔案大小,262.3k

建立orcfile表, SNAPPY一定要大寫

建立成功
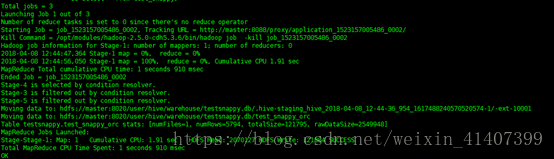
檢視檔案大小,118.9k
