
資料結構檔案管理和外排序之垂死攻略

今天學修電腦。
目錄
1.1 主儲存器(primary memory或main memory,簡稱“記憶體”,或“主存”)
1.1.1 DRAM(Dynamic Random Access Memory)——便宜
1.1.4 ROM(Read - Only Memory)只讀儲存器
1.2 外儲存器(peripheral storage或secondary storage,簡稱“外存”)
1. 儲存器


1.1 主儲存器(primary memory或main memory,簡稱“記憶體”,或“主存”)
電力供應停止時,主存的資料會消失。
1.1.1 DRAM(Dynamic Random Access Memory)——便宜

(1) DRAM晶片的內部結構

(2)DRAM的基本儲存單元
儲存一個bit需要2個電晶體

(3) DRAM的特點和主要用途
DRAM每隔一段時間,要重新整理充電一次,否則內部的資料即會消失
現代PC機大多采用DRAM作為主存。如:SDRAM,DDR3 SDRAM

1.1.2 SRAM —— 貴

(1)SRAM的基本儲存單位
相對於DRAM要複雜得多,儲存一個bit需要6個電晶體。價格能不貴嗎?

(2)SRAM的特點

現代CPU中的快取記憶體通常用SRAM實現。
1.1.3 DRAM與SRAM的比較

1.1.4 ROM(Read - Only Memory)只讀儲存器

一般手機刷機的過程,就是將只讀記憶體映象(ROM image)寫入只讀記憶體(ROM)的過程。
BIOS基本輸入輸出系統,是一套不大但複雜的程式,存放在ROM中。暫存器剛通電或復位時,CPU就會從ROM的BIOS中取出第一條指令開始執行,所以BIOS中提供了系統加電自檢,引導裝入,主要I/O裝置的處理程式及介面控制等功能模組。
1.2 外儲存器(peripheral storage或secondary storage,簡稱“外存”)

外儲存器是指除計算機記憶體及CPU快取以外的儲存器,此類儲存器一般斷電後仍然能儲存資料。
1.2.1 磁碟
(1)磁碟的物理結構

(2)磁碟碟片的組織

(3)磁碟磁軌的組織(交錯法)
每頁 512 位元組 或 1024 位元組

1.3 總結
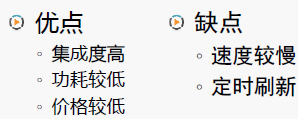
1.3.1 記憶體的優缺點

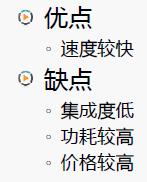
1.3.2 外存的優缺點

1.3.3 附加

2 檔案
2.1 檔案的邏輯結構
檔案是記錄的彙集
- 一個檔案的各個記錄按照某種次序排列起來,各記錄間就自然地形成了一種線性關係。
- 檔案可看成是一種線性結構
2.2 檔案的組織形式
2.2.1 邏輯檔案(logical file)
從使用者角度去看,連續的位元組構成記錄,記錄構成邏輯檔案

檔案邏輯組織形式
- 順序結構的定長記錄
- 順序結構的變長記錄
- 按關鍵碼存取的記錄
2.2.2 物理檔案(physical file)
檔案中包含的位元組成功儲存分佈在整個磁碟中
檔案物理組織結構
(1)順序結構——順序檔案
檔案的資訊存放在若干連續的物理塊中

(2)計算定址結構——雜湊檔案
一個檔案的資訊存放在若干不連續的物理塊中,各塊之間通過指標連線,前一個物理塊指向下一個物理塊

(2)帶索引的結構——帶索引檔案
系統為每個檔案建立一個專用資料結構—索引表,並將這些物理塊的塊號存放在該索引表中

2.2.3 檔案管理器
- 作業系統或資料庫系統中的一部分
檔案的記錄是無結構的,而資料庫檔案的記錄是結構型的
- 檔案管理器負責將檔案的邏輯位置對映為磁碟中具體的物理位置
2.2.4 檔案上的操作

2.3 緩衝區和緩衝池

目的:減少磁碟訪問次數的
方法:緩衝 ( buffering ) 或快取 ( caching )
- 在記憶體中保留儘可能多的塊
- 增加待訪問的塊已經在記憶體中的機會
- 儲存在一個緩衝區中的資訊經常稱為一頁( page ),往往是一次 I/O 的量
- 緩衝區合起來稱為緩衝池( buffer pool )
2.3.1 替換緩衝區塊的策略
新的頁塊申請緩衝區時,把最近最不可能被再次引用的緩衝區釋放來存放新頁
- “先進先出”( FIFO )
- “最不頻繁使用”( LFU )
- “最近最少使用”( LRU )
3 外排序
當我們要排序的檔案太大以至於記憶體無法一次性裝下的時候,這時候我們可以使用外部排序,將資料在外部儲存器和記憶體之間來回交換,以達到排序的目的。
通常由兩個相對獨立的階段組成
(1)檔案形成儘可能長的初始順串
(2)處理順串,最後形成對整資料檔案的排列檔案
一天晚上,一塵正在呆呆地看著星星,師傅突然坐在了他的旁邊

一塵啊,天上的星星那麼多,不妨你給他們按大小排個序吧

哦,這個怎麼排?
具體到我們的程式設計,就是給你2G的資料在硬碟上,但是你只有256M的記憶體可以使用,怎麼排這2G的資料呢?
這麼小的記憶體,裝不下資料啊,怎麼排呢?一臉懵逼。
還記得分而治之的思想嗎?我們可以採用這種思想把它排好序。
soga。
3.1 二路外排序——二路合併
3.1.1 例子1
首先我們可以將2G的資料分成8份,分別載入到記憶體中進行排序,在記憶體中的排序方法可以用內部排序如快排、希爾等


然後我們可以將兩個順串通過記憶體合併成一個順串(長度為原來的兩倍),經過四次合併就完成了
注意:合併操作幾乎不需要記憶體,只需分別從磁碟中的兩個順串讀入兩個元素,選擇一個最大的(或最小的)輸出,然後再讀入,再選擇
按照這個方法一直來回合併,一直合併到最終的一個順串(有序),此時排序完成
來個例子
設待排資料為:80,92,12,97,13,34,18,98,27,57,40,74,記憶體一次可以裝三個資料
將資料分為四份
然後將每份讀入記憶體,排序後寫入硬碟

然後兩兩合併
輸出哪個元素,就在那個元素所在的順串(或者叫組)再次讀入元素
就這樣,一直合併到兩個順串完,如果一個順串先完,剩下另一個順串,那麼就將剩下的順串直接拷貝到硬碟上
按照這個方法,把合併後的順串繼續合併,直到最終合併成一個總的順串,排序結束

我聽說硬碟的讀寫速度比記憶體要慢的多,按照這種排序那豈不是很慢?
為一個待排檔案建立儘可能大的初始順串,可以大大減少掃描遍數,外存讀寫次數和歸併趟數。
3.1.2 例子2

3.2 多路歸併——選擇樹
k 路歸併是每次將 k 個順串合併成一個排好序的順串

以剛才的例子來看,這次我們假設記憶體大小可以容納四個元素,我們一次對4個順串進行歸併(4路歸併)

這樣只需要一次合併就可以了,外存讀寫次數為24(12讀+12寫),比之前的48少了一半,於此同時我們也可以看到需要更大的記憶體了,記憶體之中選出最大值也會更耗時,所以要權衡選 k
在記憶體之中選最大(或最小)值時,可以選擇一個元素與其他元素一個一個比,然後更新最值,但是效率會比較低,一般採取選擇樹來選擇。
3.2.1 贏者樹——完全二叉樹

例子


根結點所指向的L[4]記錄具有最小的關鍵碼值6,它所指的記錄是順串4的當前記錄,該記錄即為下一個要輸出的記錄。
3.2.2 敗者樹——完全二叉樹

3.3 置換選擇排序
對於順串的構造,也就是第一次生成初順串的時候,我們採取的辦法是將劃分好的每一份檔案讀入記憶體,排好序,然後輸出到硬碟上形成初始順串。
這樣做的弊端就是初始順串的個數和將檔案劃分好的份數是一樣的

有沒有一種生成更長的順串,使得初始順串的個數變的更少一些呢?答案是用置換選擇排序

置換選擇排序的大體思路就是讀入一塊資料到記憶體,將這些資料建立小根堆,然後輸出最小值,再讀入下一個元素
新元素 >= 剛才寫出的元素,將其加入到最小堆中,重新調整堆
新元素 < =剛才寫出的元素,交換堆頂與堆底元素,將其放入堆底,然後移出堆
3.3.1 例子1
我們讀入三個資料在記憶體中,然後建立一個小根堆,然後寫出最小值

然後再讀進來一個元素97,這個元素97>12,把 97 放到堆頂,調整堆,然後輸出最小值80
繼續讀入13,此時13 < 剛才輸出的元素 80 ,則交換堆底元素97 和 堆頂元素 80,然後將13放入堆底(覆蓋80),並且將 13 移出堆(堆大小減一)
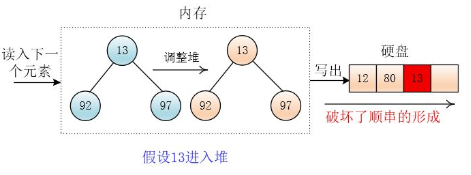
然後讀入元素 34
讀入元素18,仍然小於剛輸出的97,此時堆頂與堆底重疊,將18放入堆底(堆頂)

此時第一個順串就形成了,然後將之前未進入堆的三個元素重新建立成小根堆,然後按照同樣的方法繼續進行
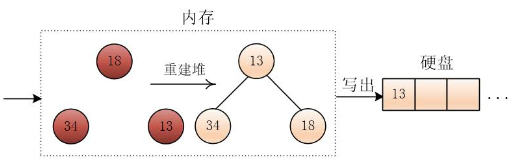
到最後,如果輸入硬碟的資料讀完了,只剩下一個小根堆,思路是一樣的,一直選出最小值,輸出

然後互換堆底與堆頂元素,再刪除堆底元素,然後調整堆,輸出最小值74

最後會生成另外一個順串。這樣只生成了兩個初始順串,比之前劃分成四份生成四個初始順串少了些,這樣歸併趟數也就少了
3.3.2 例子2

29 > 16, 輸出16, 29進堆

重新排列堆

14 < 19,14不能進入堆。輸出19,14放入堆底,並忽略。

重新排列堆
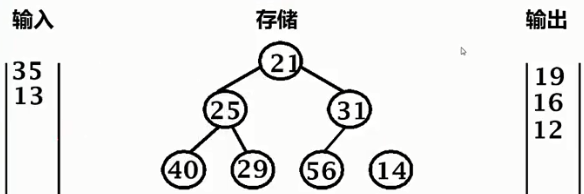
35 > 21,輸出21,35進堆

重新排列堆

13 < 25,輸出25,13壓入堆底,暫時忽略

構造下一個順串時,可以利用上13或14。堆的規模會越來越小,輸出的順串會越來越大。
3.3.3 總結
(1)置換選擇排序演算法得到的順串長度並不相等。
(2)如果堆的大小是 M
- 一個順串的最小長度就是 M 個記錄
- 最好的情況下,例如輸入為正序,有可能一次就把整個檔案生成為一個順串
- 平均情況下,置換選擇排序演算法可以形成長度為 2M 的順串
3.4 掃雪機模型
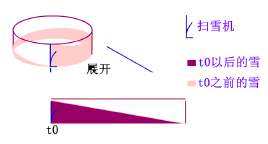
在一個下雪的日子,在一個圓形的跑道上有一個剷雪機在勻速地剷雪,下雪的速度也是勻速的,剷雪機的速度和下雪的速度剛好匹配,也就是說剷雪機從起始位置跑一圈後原來位置的雪的高度不變

正如上圖,跑了一圈後發現高度還是h,這時候就達到了一個動態平衡的狀態,此時剷雪機前方的雪是一個斜坡

剷雪機不停地往前開,雪一直下,一部分落在了剷雪機上,一部分落在了剷雪機後面
此時剷雪機最前面的雪的高度一直都是h,因為前面有雪不斷地落在斜坡上,所以剷雪機跑一圈鏟的雪的總量為s*h,很顯然是原來路上積雪的兩倍
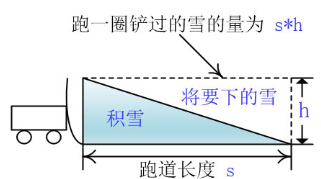
類比到我們的程式裡,道路上的積雪就是我們記憶體中建的堆,需要我們輸出最小值(清理),而不斷下的雪就是新的輸入,當輸入隨機的時候,大於等於剛輸出值的元素被加入到堆中(落在剷車前被鏟走),小於剛輸出的元素被留下(落在剷車後面),產生的順串的長度(鏟的雪)就是記憶體中堆大小(道路上的積雪)的兩倍了。

資料結構學完了嗎?哪有學完的時候。
本文學習自
張銘《資料結構》
陸俊林《計算機組成原理》