
半監督學習(五)——半監督支援向量機
半監督支援向量機(S3VMs)
今天我們主要介紹SVM分類器以及它的半監督形式S3VM,到這裡我們關於半監督學習基礎演算法的介紹暫時告一段落了。之後小編還會以論文分享的形式介紹一些比較新的半監督學習演算法。讓我們開始今天的學習吧~
引入
支援向量機(SVM)相信大家並不陌生吧?但是如果資料集中有大量無標籤資料(如下圖b),那麼決策邊界應該如何去確定呢?僅使用有標籤資料學得的決策邊界(如下圖a)將穿過密集的無標籤資料,如果我們假定兩個類是完全分開的,那麼該決策邊界並不是我們想要的,我們希望的決策邊界是下圖(b)中的黑色實線。

新的決策邊界可以很好地將無標籤資料分成兩類,而且也正確地分類了有標籤資料(雖然它到最近的有標籤資料的距離比SVM小)。
支援向量機SVM
首先我們來討論SVMs,為我們接下來要介紹的S3VMs演算法做鋪墊。為了簡單起見,我們討論二分類問題,即y{-1,1},特徵空間為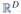 並定義決策邊界如下
並定義決策邊界如下 其中w是決定決策邊界方向和尺度的引數向量,b是偏移量。舉個例子,
其中w是決定決策邊界方向和尺度的引數向量,b是偏移量。舉個例子,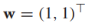 ,b=-1,決策邊界就如下圖藍色線所示,決策邊界總是垂直於w向量。
,b=-1,決策邊界就如下圖藍色線所示,決策邊界總是垂直於w向量。

我們的模型為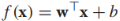 ,決策邊界是f(x)=0,我們通過sign(f(x))來預測x的標籤,我們感興趣的是例項x到決策邊界的距離,該距離的絕對值為,比如原點x=(0,0)到決策邊界的距離為
,決策邊界是f(x)=0,我們通過sign(f(x))來預測x的標籤,我們感興趣的是例項x到決策邊界的距離,該距離的絕對值為,比如原點x=(0,0)到決策邊界的距離為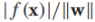 ,如上圖中的綠色實線。我們定義有標籤例項到決策邊界的有符號距離為
,如上圖中的綠色實線。我們定義有標籤例項到決策邊界的有符號距離為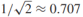
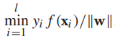 ,如果一個決策邊界能分離有標籤訓練樣本,幾何邊界是正的,我們通過尋找最大幾何邊距來發現決策邊界:
,如果一個決策邊界能分離有標籤訓練樣本,幾何邊界是正的,我們通過尋找最大幾何邊距來發現決策邊界: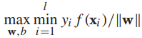 ,這個式子很難直接優化,所以我們將它重寫為等價形式。首先我們注意到引數(w,b)可以任意縮放為(cw, cb),所以我們要求最接近決策邊界的例項滿足:
,這個式子很難直接優化,所以我們將它重寫為等價形式。首先我們注意到引數(w,b)可以任意縮放為(cw, cb),所以我們要求最接近決策邊界的例項滿足: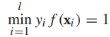 ,接下來,目標方程可以重寫為約束優化問題的形式:
,接下來,目標方程可以重寫為約束優化問題的形式: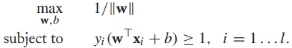 ,而且,最大化1/||w||相當於最小化||w||的平方:
,而且,最大化1/||w||相當於最小化||w||的平方:
到目前為止,我們都是基於訓練樣本是線性可分的,現在我們放寬這個條件,那麼上述目標方程不再滿足。我們要對約束條件進行鬆弛使得在某些例項上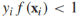
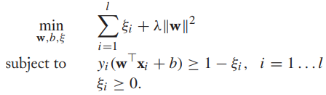
然而,將目標函式轉換成一個正則化的風險最小化的形式是有必要的(這關係到我們將其拓展到S3VMs)。考慮這樣一個優化問題: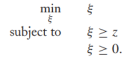
很容易可以看出當z<=0時,目標函式值為0,否則為z,所以可以簡寫為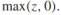
注意 (*)中的約束條件可以重寫為
(*)中的約束條件可以重寫為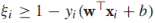 ,利用剛才的結論,我們將(*)重寫為
,利用剛才的結論,我們將(*)重寫為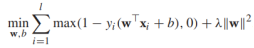
其中第一項代表的是hinge loss損失函式,第二項是正則項。
我們這裡不再深入討論SVMs的對偶形式或者核技巧(將特徵對映到更高維度的空間來解決非線性問題),雖然這兩個問題是SVMs的關鍵,但不是我們要介紹的S3VMs的重點(當然也可以將核技巧直接應用到S3VMs上),感興趣的同學可以去看相關的論文。
半監督支援向量機(S3VMs)
在上文中我們提到用hinge loss來使有標籤資料分類儘可能正確,但是如果存在無標籤資料呢?沒有標籤的話就不能知道是否分類正確,就更別提懲罰了。
我們已經學習出來一個標籤預測器sign(f(x)),對於無標籤樣本,它的預測標籤為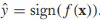 ,我們假定該預測值就是x的標籤,那麼就可以在x上應用hinge損失函數了
,我們假定該預測值就是x的標籤,那麼就可以在x上應用hinge損失函數了
我們稱它為hat loss。
由於我們標籤就是用f(x)生成的,無標籤樣本總是能被正確分類,然而hat loss 仍然可以懲罰一定的無標籤樣本。從式子中可以看出,hat損失函式更偏愛 (懲罰為0,離決策邊界比較遠),而懲罰-1<f(x)<1(特別是趨近於0)的樣本,因為這些樣本很有可能被分類錯誤,現在,我們可以寫出S3VMs的在有標籤和無標籤資料上的目標方程:
(懲罰為0,離決策邊界比較遠),而懲罰-1<f(x)<1(特別是趨近於0)的樣本,因為這些樣本很有可能被分類錯誤,現在,我們可以寫出S3VMs的在有標籤和無標籤資料上的目標方程: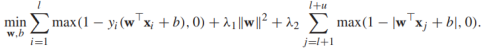 (**)
(**)
其實我們可以看出來S3VMs的目標方程偏向於將無標籤資料儘可能遠離決策邊界(也就是說,決策邊界儘可能穿過無標籤資料的低密度區域(是不是像聚類演算法的作用))。其實上面的目標方程更像是 正則化的風險最小化形式(在有標籤資料上使用hinge loss),其正則化項為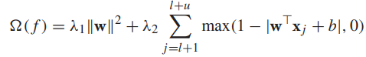
還需要注意的一點是,從經驗上來看,(**)的結果是不平衡的(大多數甚至所有的無標籤資料可能被分為一個類),造成這種現象的原因雖然還不清楚,為了修正這種錯誤,一種啟發式方法就是在無標籤資料上限制預測類的比例與標籤資料的比例相同 ,由於是不連續的,所以這個約束很難滿足,所以我們對其進行鬆弛,轉化為包含連續函式的約束:
,由於是不連續的,所以這個約束很難滿足,所以我們對其進行鬆弛,轉化為包含連續函式的約束: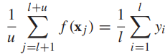 ,
,
完整的S3VMs的目標函式可以寫作:
然而,S3VMs演算法的目標函式不是凸的,也就是說,他有多個區域性優解,這是我們求解目標函式的一個計算難點。學習演算法可能會陷入一個次優的區域性最優解,而不是全域性最優解,S3VMs的一個研究熱點就是有效的找到一個近似最優解。
熵正則化
SVMs和S3VMs 不是概率模型,也就是說他們不是通過計算類的後驗概率來進行分類的。在統計機器學習中,有很多概率模型是通過計算p(y|x)來進行分類的,有趣的是對於這些概率模型也有一個對S3VMs的直接模擬,叫做entropy regularization。為了使我們的討論更加具體,我們將首先介紹一個特定的概率模型:邏輯迴歸,並通過熵正則將它擴充套件到半監督學習上。
邏輯迴歸對類的後驗概率進行建模,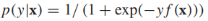 將f(x)的範圍從
將f(x)的範圍從 規約到[0,1],模型的引數是w和b。給定有標籤的訓練樣本
規約到[0,1],模型的引數是w和b。給定有標籤的訓練樣本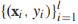 條件對數似然是
條件對數似然是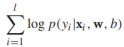 ,假定w服從高斯分佈
,假定w服從高斯分佈 ,I是對角矩陣,那麼邏輯迴歸模型的訓練就是最大化後驗概率:
,I是對角矩陣,那麼邏輯迴歸模型的訓練就是最大化後驗概率: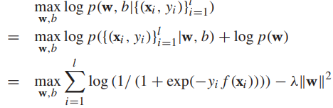
這相當於下面的正則化風險最小化問題: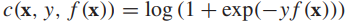
邏輯迴歸沒有使用無標籤資料,我們可以加入無標籤資料,基於如下準則:如果兩個類可以很好的分開,那麼在任何無標籤樣本上的分類都是可信的:要麼屬於正類要麼屬於負類。同樣,後驗概率要麼接近於1,要麼接近於0.一種度量置信度的方法就是熵,對於概率為p的伯努利隨機變數,熵的定義如下:
給定無標籤樣本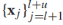 ,可以定義邏輯迴歸的熵正則化器為:
,可以定義邏輯迴歸的熵正則化器為: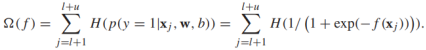
如果未標記例項的分類是確定的,則該值較小。直接將它應用到S3VMs上,我們可以定義半監督的邏輯迴歸模型:
The assumption of S3VMs
S3VMs和熵正則的假設就是樣本的類可以很好的分開,決策邊界落在樣本特徵空間的低密度區域且不會通過密集的未標記資料。如果這個假設不滿足,S3VMs可能會導致很差的表現。
小結:
今天我們介紹了SVM分類器以及它的半監督形式S3VM,與我們前面討論的半監督學習技術不同,S3VMs尋找一個在無標籤資料的低密度區間的決策邊界。我們還介紹了熵正則化,它是基於邏輯迴歸的概念模型的。到這裡我們關於半監督學習基礎演算法的介紹暫時告一段落了。之後還會以論文分享的形式介紹一些比較新的半監督學習演算法。後面的內容會探索人類和機器學習的半監督學習之間的聯絡,並討論半監督學習研究對認知科學領域的潛在影響,敬請期待~!
希望大家多多支援我的公眾號,掃碼關注,我們一起學習,一起進步~

相關推薦
半監督學習(五)——半監督支援向量機
半監督支援向量機(S3VMs) 今天我們主要介紹SVM分類器以及它的半監督形式S3VM,到這裡我們關於半監督學習基礎演算法的介紹暫時告一段落了。之後小編還會以論文分享的形式介紹一些比較新的半監督學習演算法。讓我們開始今天的學習吧~ 引入 支援向量機(SVM)相信大家並不陌生吧?但是如果資料集中有大量無
機器學習實戰系列(五):SVM支援向量機
課程的所有資料和程式碼在我的Github:Machine learning in Action,目前剛開始做,有不對的歡迎指正,也歡迎大家star。除了 版本差異,程式碼裡的部分函式以及程式碼正規化也和原書不一樣(因為作者的程式碼實在讓人看的彆扭,我改過後看起來舒服多了)
詳解SVM系列(五):非線性支援向量機與核函式
對解線性分類問題,線性分類支援向量機是一種有效的方法。但是,有時分類問題是非線性的,這時可以使用非線性支援向量機。 核技巧 **非線性分類問題:**如上面左圖所示,能用 R
MySQL 基礎知識梳理學習(五)----半同步復制
borde dump 反饋 tex 數據完整性 註意 align span 復制 1.半同步復制的特征 (1)從庫會在連接到主庫時告訴主庫,它是不是配置了半同步。 (2)如果半同步復制在主庫端是開啟了的,並且至少有一個半同步復制的從節點,那麽此時主庫的事務線程在提交時會被阻
學習筆記(十):使用支援向量機區分僵屍網路DGA家族
1.資料蒐集和資料清洗 ·1000個cryptolocker域名 ·1000個post-tovar-goz域名 ·alexa前1000域名 &n
學習筆記(九):使用支援向量機識別XSS
1.特徵化:提取特徵,對特徵進行向量化,標準化,均方差縮放,去均值操作 def get_len(url): return len(url) def get_url_count(url): if re.search('(http://)|(http://)',url,re.IGNO
機器學習筆記(八)震驚!支援向量機(SVM)居然是這種機
今天想說的呢是SVM支援向量機(support vector machine),我覺得這個演算法它初始出發的想法真的是非常符合人性,特徵空間上間隔最大的分類器,你隨便問一個人分開空間上的兩坨點最佳的平
機器學習總結(三):SVM支援向量機(面試必考)
基本思想:試圖尋找一個超平面來對樣本分割,把樣本中的正例和反例用超平面分開,並儘可能的使正例和反例之間的間隔最大。 演算法推導過程: (1)代價函式:假設正類樣本y =wTx+ b>=+1,負
支援向量機學習筆記(三):非線性支援向量機與SMO演算法
非線性問題 在之前學了線性支援向量機,通過訓練集學習到分離超平面 w x +
支援向量機學習筆記(二):線性支援向量機
在前面已經講了線性可分支援向量機,是基於訓練集是線性可分的假設下,但是現實生活中往往資料集不是可分的,會存在著噪音或異常值,看下面的圖。 補充:個人習慣,接下來會將凸二次規劃模型稱為支援向量機模型,因為支援向量機是通過求解凸二次規劃模型最終得到分離超平面。另外分離超平面
SVM支援向量機系列理論(四) 軟間隔支援向量機
4.1 軟間隔SVM的經典問題 4.2 軟間隔SVM的對偶問題 4.2.1 軟間隔SVM的對偶問題學習演算法 4.3 軟間
詳解SVM系列(四):線性支援向量機與軟間隔最大化
線性支援向量機 線性可分問題的支援向量機學習方法,對線性不可分訓練資料是不適用的,因為這時上述方法的不等式約束並不能都成立。 舉2個例子: 如果沒有混入異常點,導致不能線性可分,則資料可以按上面的實線來做超平面分離的。 這種情況雖然不是不可分的,但是由於其中的一個藍色點不滿足線性
資料探勘十大演算法——支援向量機SVM(一):線性支援向量機
首先感謝“劉建平pinard”的淵博知識以及文中詳細準確的推導!!! 本文轉自“劉建平pinard”,原網址為:http://www.cnblogs.com/pinard/p/6097604.html。 支援向量機原理SVM系列文章共分為5部分: (一)線性支援向量機
資料探勘十大演算法——支援向量機SVM(二):線性支援向量機的軟間隔最大化模型
首先感謝“劉建平pinard”的淵博知識以及文中詳細準確的推導!!! 支援向量機原理SVM系列文章共分為5部分: (一)線性支援向量機 (二)線性支援向量機的軟間隔最大化模型 (三)線性不可分支援向量機與核函式 (四)SMO演算法原理 (五)線性支援迴歸
機器學習與深度學習系列連載: 第一部分 機器學習(十三)半監督學習(semi-supervised learning)
在實際資料收集的過程中,帶標籤的資料遠遠少於未帶標籤的資料。 我們據需要用帶label 和不帶label的資料一起進行學習,我們稱作半監督學習。 Transductive learning:沒有標籤的資料是測試資料 Inductive learning:沒有標
半監督學習(三)——混合模型
Semi-Supervised Learning 半監督學習(三) 方法介紹 Mixture Models &
半監督學習(四)——基於圖的半監督學習
基於圖的半監督學習 以一個無標籤資料的例子作為墊腳石 Alice正在翻閱一本《Sky and Earth》的雜誌,裡面是關於天文學和旅行的文章。Alice不會英文,她只能通過文章中的圖片來猜測文章的類別。比如第一個故事是“Bridge As
python3(五)無監督學習
正文回到頂部1 關於機器學習 機器學習是實現人工智慧的手段, 其主要研究內容是如何利用資料或經驗進行學習, 改善具體演算法的效能 多領域交叉, 涉及概率論、統計學, 演算法複雜度理論等多門學科 廣泛應用於網路搜尋、垃圾郵件過濾、推薦系統、廣告投放、信用評價、欺詐檢測、股票交易和醫療診斷等
《css揭秘》學習(一)半透明邊框
sla class 代碼 原因 什麽 alt sat spa 運行 1. 知識點HSLA顏色:HSLA(H,S,L,A),取值:H:Hue(色調)。0(或360)表示紅色,120表示綠色,240表示藍色,也可取其他數值來指定顏色。取值為:0 – 360;S:Saturati
初學計算幾何(五)——半平面交
前言 學了這麼久計算幾何,其實就是為了學半平面交。 而學半平面交,其實就是為了做洛谷試煉場裡的這道題:【洛谷3222】[HNOI2012] 射箭。 概念 半平面:一條直線會把一個平面分成兩個半平面,通常我們把直線左邊的半平面視為我們所需要的半平面。 半平面交:即若干半平面的交集,顯然它有