
使用enumerate()函式時,慣性思維帶來的錯誤
阿新 • • 發佈:2019-01-10
防止enumerate()迴圈後出錯
enumerate和for迴圈
enumerate和for迴圈很像,for迴圈是遍歷一個列表裡所有的元素,enumerate()對於一個可迭代的(iterable)/可遍歷的物件(如列表、字串),enumerate將其組成一個索引序列,利用它可以同時獲得索引(標籤)和值(元素),
當遍歷列表時有刪除操作時
- 程式碼
a=["soccer","basketball","pingpong","run","play","game"] b=[] for num,i in enumerate(a): print(num,i) if len(i) > 6: print('刪除'+i) del a[num] else: b.append(i) print(a) print(b)
- 執行結果
[‘soccer’, ‘pingpong’, ‘run’, ‘play’, ‘game’]
[‘soccer’, ‘run’, ‘play’, ‘game’] - 解釋
發現結果中滿足條件(長度大於6)的ping-pong並沒有被刪除,下面模擬一下enumerate執行過程,enumerate的過程並不一定是按每個元素過濾一遍,而是按每個索引(0,1,2,3…)過濾一遍。
迴圈過程如下:
| 索引 | 第一次迴圈 | 第二次迴圈 | 第三次迴圈 | 第四次 | 第五次 | 第六次 |
|---|---|---|---|---|---|---|
| 0 | soccer | soccer | soccer | soccer | soccer | soccer |
| 1 | basketball | pingpong | pingpong | pingpong | pingpong | pingpong |
| 2 | pingpong | run | run | run | run | run |
| 3 | run | play | play | play | play | play |
| 4 | play | game | game | game | game | game |
| 5 | game |
第一次迴圈標籤為0的soccer元素,不滿足條件(長度<6),保留元素。第二次迴圈索引為1的basketball元素,滿足條件,刪除元素。在第三次迴圈開始的時候,由於上一個迴圈刪除了basketball元素,所以basketball後面的元素索引都會減一。所以pingpong元素的索引由原來的2,變成了1。但第二次迴圈已經遍歷了索引為1的元素,所以第三次迴圈不會再遍歷這個索引以及對應的元素。所以滿足刪除條件的pingpong元素沒有被刪除。
解決方法
- 只要讓滿足刪除條件的兩個元素不挨著,那就可以刪除所有滿足條件的元素。
- 讓列表中的元素倒著迴圈。
a=["soccer","game","play","pingpong","run","basketball"]
b=[]
for num,i in enumerate(a):
print(num,i)
if len(i) > 6:
print('刪除'+i)
del a[num]
else:
b.append(i)
print(a)
print(b)
執行結果:
[‘soccer’, ‘game’, ‘play’, ‘run’]
[‘soccer’, ‘game’, ‘play’]
為什麼b列表只有兩個元素呢?
因為刪除元素後,run的新索引之前被遍歷過了,所以就自動略過了。
dataframe的索引
資料框(dataframe)每一行對應的標籤是不會變化的
np.random.seed(123)
df = pd.DataFrame(np.random.randn(5,3))
df.drop([0],axis=1,inplace=True)
print(df)
執行結果:
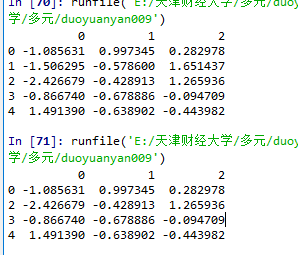
第二行被刪除了,但是每一行原來對應的索引還是原來的索引。