
《機器學習》(周志華)西瓜書讀書筆記
阿新 • • 發佈:2019-01-10
回到頂部
第1章 緒論
- 對於一個學習演算法a,若它在某問題上比學習演算法b好,則必然存在另一些問題,在那裡b比a好.即"沒有免費的午餐"定理(No Free Lunch Theorem,NFL).因此要談論演算法的相對優劣,必須要針對具體的學習問題
第2章 模型評估與選擇
- m次n折交叉驗證實際上進行了m*n次訓練和測試
- 可以用F1度量的一般形式Fβ來表達對查準率/查全率的偏好:
- 偏差度量了學習演算法的期望預測與真實結果的偏離程度,即學習演算法本身的擬合能力,方差度量了同樣大小的訓練集的變動所導致的學習效能的變化,即資料擾動造成的影響.噪聲表達了當前任務上任何學習演算法所能達到的期望泛化誤差的下界,即學習問題本身的難度.
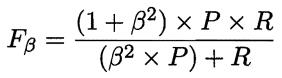
第3章 線性模型
- 線性判別分析(LDA)是一種經典的監督線性降維方法:設法將訓練樣例投影到一條直線上,使同類樣例的投影點儘可能接近,異類樣例的投影點儘可能遠離.對新樣本分類時根據投影點的位置來確定類別.
- 多分類學習的分類器一般有以下三種策略:
- 一對一(OvO),N個類別產生N * (N - 1) / 2種分類器
- 一對多(OvR或稱OvA),N個類別產生N - 1種分類器
- 多對多(MvM),如糾錯輸出碼技術
- 解決類別不平衡問題的三種方法:
- 過取樣法,增加正例使正負例數目接近,如SMOTE:思想是合成新的少數類樣本,合成的策略是對每個少數類樣本a,從它的最近鄰中隨機選一個樣本b,然後在a、b之間的連線上隨機選一點作為新合成的少數類樣本.
- 欠取樣法,減少負例使正負例數目接近,如EasyEnsemble:每次從大多數類中抽取和少數類數目差不多的重新組合,總共構成n個新的訓練集,基於每個訓練集訓練出一個AdaBoost分類器(帶閾值),最後結合之前訓練分類器結果加權求和減去閾值確定最終分類類別.
- 再縮放法
第4章 決策樹
- ID3決策樹選擇資訊增益最大的屬性來劃分:
- 資訊熵:
- 資訊增益:
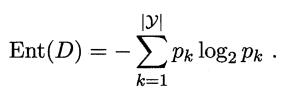
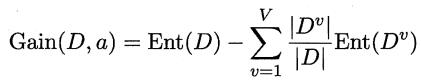
- C4.5決策樹選擇增益率大的屬性來劃分,因為資訊增益準則對可取值數目較多的屬性有所偏好.但增益率會偏好於可取值數目較少的屬性,因此C4.5演算法先找出資訊增益高於平均水平的屬性,再從中選擇增益率最高的.另外,C4.5決策樹採用二分法對連續值進行處理,使用時將劃分閾值t作為引數,選擇使資訊增益最大的t劃分屬性.採用樣本權值對缺失值進行處理,含有缺失值的樣本同時劃入所有結點中,但相應調整權重.
- 增益率:
- a的固有值:
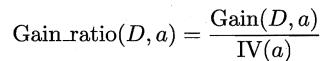
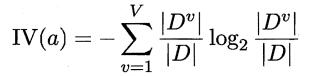
- CART決策樹則選擇基尼指數最小的屬性來劃分,基尼係數反映了從資料集中隨機抽取的兩個樣本類別不一致的概率,注意CART是二叉樹,其餘兩種都為多叉樹.
- 基尼值衡量的純度:
- 基尼指數:
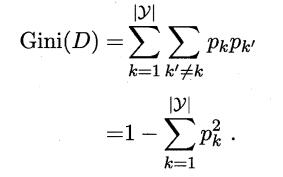
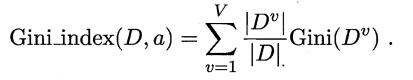
- 剪枝是決策樹對付過擬合的主要手段,分為預剪枝和後剪枝.
- 預剪枝對每個結點在劃分前先進行估計,若該結點的劃分不能帶來決策樹泛化效能提升,則停止劃分.預剪枝基於"貪心"本質,所以有欠擬合的風險.
- 後剪枝是先生成一棵完整的決策樹,然後自底向上對非葉結點考察,若該結點替換為葉結點能帶來決策樹泛化效能提升,則將子樹替換為葉結點.缺點是時間開銷大.
- 決策樹所形成的分類邊界是軸平行的,多變數決策樹(斜決策樹)的每一個非葉結點都是一個線性分類器,因此可以產生斜的劃分邊界.
第5章 神經網路
- 誤差逆傳播演算法(BP演算法)是迄今為止最成功的神經網路學習演算法.關鍵點在於通過計算誤差不斷逆向調整隱層神經元的連線權和閾值.標準BP演算法每次僅針對一個訓練樣例更新,累積BP演算法則根據訓練集上的累積誤差更新.

- 緩解BP神經網路過擬合有兩種常見策略:
- 早停:若訓練集誤差降低但驗證集誤差升高則停止訓練.
- 正則化:在誤差目標函式中增加一個描述網路複雜度的部分(較小的連線權和閾值將使神經網路較為平滑).
- 跳出區域性最小,尋找全域性最小的常用方法:
- 以多組不同引數初始化多個神經網路,選擇最接近全域性最小的
- 模擬退火
- 隨機梯度下降
- 典型的深度學習模型就是很深層的神經網路.但是多隱層神經網路難以直接用經典演算法進行訓練,因為誤差在多隱層內逆傳播時往往會發散.無監督逐層訓練(如深層信念網路,DBN)和權共享(如卷積神經網路,CNN)是常用的節省訓練開銷的策略.
第6章 支援向量機
- 支援向量機中的原始樣本空間不一定存在符合條件的超平面,但是如果原始空間是有限維,則總存在一個高維特徵空間使樣本線性可分.核函式就是用來簡化計算高維特徵空間中的內積的一種方法.核函式選擇是支援向量機的最大變數.常用的核函式有線性核,多項式核,高斯核(RBF核),拉普拉斯核,Sigmoid核.對文字資料常用線性核,情況不明時可先嚐試高斯核.
- 軟間隔是緩解支援向量機過擬合的主要手段,軟間隔允許某些樣本不滿足約束.
- 支援向量迴歸可以容忍預測輸出f(x)和真實輸出y之間存在ε的偏差,僅當偏差絕對值大於ε時才計算損失.
- 支援向量機中許多規劃問題都使用拉格朗日對偶演算法求解,原因在於改變了演算法複雜度.原問題的演算法複雜度與樣本維度有關,對偶問題的樣本複雜度與樣本數量有關.如果使用了升維的方法,則此時樣本維度會遠大於樣本數量,在對偶問題下求解會更好.
第7章 貝葉斯分類
- 基於貝葉斯公式來估計後驗概率的困難在於類條件概率是所有屬性上的聯合概率,難以從有限的訓練樣本直接估計而得.因此樸素貝葉斯分類器採用了"屬性條件獨立性假設"來避開這個障礙.
- 樸素貝葉斯分類器中為了避免其他屬性攜帶的資訊被訓練集中未出現的屬性值"抹去",在估計概率值時通常要進行"平滑",常用拉普拉斯修正.
- 屬性條件獨立性假設在現實中往往很難成立,於是半樸素貝葉斯分類器採用"獨依賴估計(ODE)",即假設每個屬性在類別之外最多僅依賴於一個其他屬性.在此基礎上有SPODE,TAN,AODE等演算法.
- 貝葉斯網又稱信念網,藉助有向無環圖來刻畫屬性之間的依賴關係,並用條件概率表來描述屬性的聯合概率分佈.半樸素貝葉斯分類器是貝葉斯網的一種特例.
- EM(Expectation-Maximization)演算法是常用的估計引數隱變數的方法.基本思想是:若引數θ已知,則可根據訓練資料推斷出最優隱變數Z的值(E);若Z的值已知,則可方便地對引數θ做極大似然估計(M).
第8章 整合學習
- 整合學習先產生一組個體學習器,再用某種策略將它們結合起來.如果整合中只包含同種型別的個體學習器則叫同質整合,其中的個體學習器稱為基學習器,相應的學習演算法稱為基學習演算法.如果包含不同型別的個體學習器則叫異質整合,其中的學習器常稱為元件學習器.
- 要獲得好的整合,個體學習器應"好而不同".即要有一定的準確性,並且要有多樣性.
- 目前的整合學習方法大致分為兩大類:
- 序列化方法:個體學習器間存在強依賴關係,必須序列生成.
- 並行化方法:個體學習器間不存在強依賴關係,可同時生成.
- Boosting先從初始訓練集訓練出一個基學習器,再根據基學習器的表現對訓練樣本分佈進行調整,使做錯的訓練樣本在後續受到更多關注(給予更大的權重或重取樣).然後基於調整後的樣本分佈來訓練下一個基學習器;直到基學習器的數目達到指定值T之後,將這T個基學習器加權結合.Boosting主要關注降低偏差,因此能基於泛化效能相當弱的學習器構建出很強的整合.代表演算法有AdaBoost.
- Bagging是並行式整合學習方法最著名的代表.它基於自助取樣法,取樣出T個含m個訓練樣本的取樣集,基於每個取樣集訓練出一個基學習器,再將這些基學習器進行簡單結合.在對預測輸出進行結合時,常對分類任務使用投票法,對迴歸任務使用平均法.Bagging主要關注降低方差,因此在不剪枝決策樹,神經網路等易受樣本擾動的學習器上效用更明顯.代表演算法有隨機森林.
- 隨機森林在以決策樹為基學習器構建Bagging的基礎上,進一步引入了隨機屬性選擇.即先從屬性集合(假定有d個屬性)中隨機選擇一個包含k個屬性的子集,再從這個子集中選擇一個最優屬性進行劃分.當k=d時,基決策樹與傳統決策樹相同.當k=1時,則隨機選擇一個屬性用於劃分.一般推薦k=log2d.
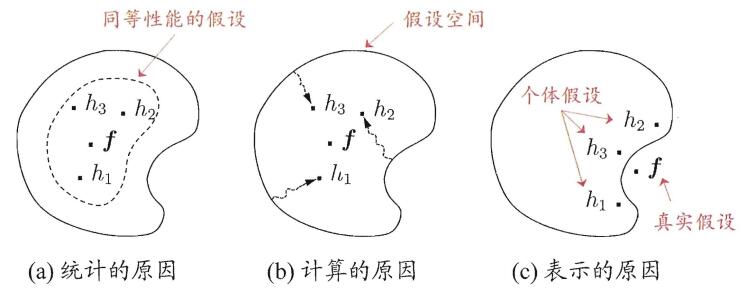
- 學習器結合可能會從三個方面帶來好處:
- 統計:可能有多個假設在訓練集上達到同等效能,單學習器可能因誤選而導致泛化效能不佳,結合多個學習器會減小這一風險.
- 計算:通過多次執行之後進行結合,降低陷入糟糕區域性極小點的風險.
- 表示:結合多個學習器,相應的假設空間有所擴大,有可能學得更好的近似.
- 結合策略:
- 平均法:對數值型輸出,最常見的策略是平均法.一般而言,在個體學習器效能相差較大時使用加權平均法,效能相近時使用簡單平均法.權重一般也是從訓練資料中學習而得.
- 投票法:對分類任務來說,最常見的策略是投票法.又可細分為絕對多數投票法,相對多數投票法,加權投票法.絕對多數投票法允許"拒絕預測",若必須提供預測結果則退化為相對多數投票法.若基學習器的型別不同,則類概率值不能直接比較,需要將類概率輸出轉化為類標記輸出後再投票.
- 學習法:當訓練資料很多時,一種更強大的策略是通過另一個學習器來結合.Stacking是學習法的典型代表.我們把個體學習器稱為初級學習器,用於結合的學習器稱為次級學習器或元學習器.Stacking用初級學習器的輸出作為樣例輸入特徵,用初始樣本的標記作為樣例標記,然後用這個新資料集來訓練次級學習器.一般用初級學習器的輸出類概率作為次級學習器的輸入屬性,用多響應線性迴歸(Multi-response Linear Regression,MLR)作為次級學習演算法效果較好.
- 多樣性增強常用的方法有:資料樣本擾動,輸入屬性擾動,輸出表示擾動,演算法引數擾動.
第9章 聚類
- 聚類既能作為一個找尋資料內在分佈結構的單獨過程,也可以作為其他學習任務的前驅過程.
- 我們希望"物以類聚",也就是聚類結果的"簇內相似度"高且"簇間相似度"低.聚類效能度量大致有兩類.一類是將聚類結果與參考模型進行比較,稱為外部指標,常用的有JC,FMI,RI;另一類是直接考察聚類結果,稱為內部指標,常用的有DBI,DI.
- 有序屬性距離計算最常用的是閔可夫斯基距離,當p=2時即歐氏距離,當p=1時即曼哈頓距離.
- 對無序屬性可採用VDM(Value Difference Metric),將閔可夫斯基距離和VDM結合即可處理混合屬性,當不同屬性的重要性不同時可使用加權距離.
- 我們基於某種形式的距離來定義相似度度量,但是用於相似度度量的距離未必一定要滿足距離度量的基本性質,尤其是直遞性.在現實任務中有必要通過距離度量學習來基於資料樣本確定合適的距離計算式.
- 原型聚類假設聚類結構能通過一組原型刻畫.通常演算法先對原型進行初始化,然後對原型進行迭代更新求解.常用的原型聚類演算法有k均值演算法,學習向量量化,高斯混合聚類.
- 密度聚類假設聚類結構能通過樣本分佈的緊密程度確定.通常從樣本密度的角度來考察樣本之間的可連線性,並基於可連線樣本不斷擴充套件聚類簇.常用演算法有DBSCAN
- 層次聚類試圖在不同層次對資料集進行劃分,從而形成樹形的聚類結構.代表演算法有AGNES.
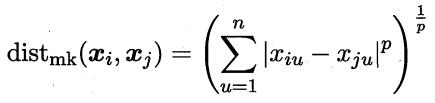
第10章 降維與度量學習
- 懶惰學習在訓練階段只把樣本儲存起來,訓練時間開銷為零,待收到測試樣本後再進行處理,如k近鄰學習(kNN).急切學習則在訓練階段就對樣本進行學習處理.
- 若任意測試樣本x附近任意小的δ距離範圍內總能找到一個訓練樣本,即訓練樣本的取樣密度足夠大,或稱為密取樣,則最近鄰分類器(1NN)的泛化錯誤率不超過貝葉斯最優分類器的錯誤率的兩倍.
- 在高維情形下出現的資料樣本稀疏,距離計算困難等問題稱為"維數災難".處理高維資料的兩大主流技術是降維和特徵選擇.
- 降維亦稱維數約簡,即通過某種數學變換將原始高維屬性空間轉變為一個低維子空間.能進行降維的原因是與學習任務密切相關的或許僅僅是資料樣本的某個低維分佈,而不是原始高維空間的樣本點.
- 多維縮放是一種經典的降維方法.它使原始空間中樣本之間的距離在低維空間中得以保持.
- 主成分分析(PCA)是最常用的一種降維方法.如果要用一個超平面對所有樣本進行恰當的表達,這個超平面應該具有最近重構性和最大可分性兩種性質.基於這兩種性質可以得到主成分分析的等價推導.PCA可以使樣本的取樣密度增大,同時在一定程度上起到去噪的效果.
- 線性降維方法有可能丟失低維結構,因此要引入非線性降維.一種常用方法是基於核技巧對線性降維方法進行核化.如核主成分分析(KPCA).
- 流形學習(manifold learning)是一類借鑑了拓撲流形概念的降維方法.流形在區域性具有歐氏空間性質.將低維流形嵌入到高維空間中,可以容易地在區域性建立降維對映關係,再設法將區域性對映關係推廣到全域性.常用的流形學習方法有等度量對映和區域性線性嵌入等.
- 對高維資料進行降維的主要目的是找到一個合適的低維空間.事實上,每個空間對應了在樣本屬性上定義的一個距離度量,度量學習直接嘗試學習出一個合適的距離度量.常用方法有近鄰成分分析(NCA).

第11章 特徵選擇與稀疏學習
- 對當前學習任務有用的屬性稱為相關特徵,沒什麼用的屬性稱為無關特徵.從給定特徵集合中選擇出相關特徵子集的過程稱為特徵選擇.特徵選擇是一個重要的資料預處理過程.
- 冗餘特徵是指包含的資訊可以從其他特徵中推演出來的特徵.冗餘特徵在很多時候不起作用,但若某個冗餘特徵恰好對應了完成學習任務所需的中間概念,則該冗餘特徵反而是有益的.
- 子集搜尋:可以採用逐漸增加相關特徵的前向搜尋,每次在候選子集中加入一個特徵,選取最優候選子集.也可以採用每次去掉一個無關特徵的後向搜尋.這些策略是貪心的,但是避免了窮舉搜尋產生的計算問題.
- 子集評價:特徵子集A確定了對資料集D的一個劃分,樣本標記資訊Y對應著對D的真實劃分,通過估算這兩個劃分的差異就能對A進行評價.可採用資訊熵等方法.
- 過濾式選擇先對資料集進行特徵選擇,然後再訓練學習器,特徵選擇過程與後續學習器無關.Relief(Relevant Features)是一種著名的過濾式選擇方法.該方法設計了一個相關統計量來度量特徵的重要性.
- 包裹式選擇直接把最終將要使用的學習器的效能作為特徵子集的評價標準.因此產生的最終學習器的效能較好,但訓練時的計算開銷也更大.LVW(Las Vegas Wrapper)是一個典型的包裹式特徵選擇方法,它在拉斯維加斯方法框架下使用隨機策略來進行子集搜尋,並以最終分類器的誤差為特徵子集評價準則.
- 嵌入式選擇是將特徵選擇過程與學習器訓練過程融為一體,兩者在同一個優化過程中完成.例如正則化.
- L1正則化(Lasso)是指權值向量w中各個元素的絕對值之和.L1正則化趨向選擇少量的特徵,使其他特徵儘可能為0,可以產生稀疏權值矩陣,即產生一個稀疏模型,可以用於特徵選擇.L1正則化是L0正則化的最優凸近似.
- L2正則化(Ridge)是指權值向量w中各個元素的平方和然後再求平方根.L2正則化趨向選擇更多的特徵,讓這些特徵儘可能接近0,可以防止模型過擬合(L1也可以).
- 字典學習也叫稀疏編碼,指的是為普通稠密表達的樣本找到合適的字典,將樣本轉化為合適的稀疏表達形式,從而使學習任務得以簡化,模型複雜度得以降低的過程.
- 壓縮感知關注的是利用訊號本身的稀疏性,從部分觀測樣本中恢復原訊號.分為感知測量和重構恢復兩個階段,其中重構恢復比較重要.可利用矩陣補全等方法來解決推薦系統之類的協同過濾(collaborative filtering)任務.
由於第一次閱讀,12章開始的內容僅作概念性瞭解.
回到頂部第12章 計算學習理論
- 計算學習理論研究的是關於通過計算來進行學習的理論,目的是分析學習任務的困難本質,為學習演算法提供理論保證,並提供分析結果指導演算法設計.
- 計算學習理論中最基本的是概率近似正確(Probably Approximately Correct,PCA)學習理論.由此可以得到PAC辨識,PAC可學習,PAC學習演算法,樣本複雜度等概念.
- 有限假設空間的可分情形都是PAC可學習的.對於不可分情形,可以得到不可知PAC可學習的概念,即在假設空間的所有假設中找到最好的一個.
- 對二分類問題來說,假設空間中的假設對資料集中示例賦予標記的每種可能結果稱為對資料集的一種對分.若假設空間能實現資料集上的所有對分,則稱資料集能被假設空間打散.假設空間的VC維是能被假設空間打散的最大資料集的大小.
- 演算法的穩定性考察的是演算法在輸入發生變化時,輸出是否會隨之發生較大的變化.
第13章 半監督學習
- 主動學習是指先用有標記樣本訓練一個模型,通過引入額外的專家知識,將部分未標記樣本轉變為有標記樣本,每次都挑出對改善模型效能幫助大的樣本,從而構建出比較強的模型.
- 未標記樣本雖未直接包含標記資訊,但若它們與有標記樣本是從同樣的資料來源獨立同分布取樣而來,則它們所包含的關於資料分佈的資訊對建模大有裨益.
- 要利用未標記樣本,需要有一些基本假設,如聚類假設,流形假設.
- 半監督學習可進一步劃分為純半監督學習和直推學習.前者假定訓練資料中的未標記樣本並非待預測的資料,而後者則假定學習過程中所考慮的未標記樣本恰是待預測資料.
- 生成式方法是直接基於生成式模型的方法.此類方法假設所有資料都是由同一個潛在的模型生成的.這個假設使得我們能通過潛在模型的引數將未標記資料與學習目標聯絡起來.
- 半監督支援向量機(S3VM)是支援向量機在半監督學習上的推廣.S3VM試圖找到能將兩類有標記樣本分開,且穿過資料低密度區域的劃分超平面.
- 除此之外,還有圖半監督學習,基於分歧的方法(如協同訓練),半監督聚類等學習方法.
第14章 概率圖模型
- 機器學習最重要的任務,是根據一些已觀察到的證據來對感興趣的未知變數進行估計和推測.生成式模型考慮聯合分佈P(Y,R,O),判別式模型考慮條件分佈P(Y,R|O).
- 概率圖模型是一類用圖來表達變數相關關係的概率模型.若變數間存在顯式的因果關係,常使用貝葉斯網.若變數間存在相關性但難以獲取顯式的因果關係,常使用馬爾可夫網.
- 隱馬爾可夫模型(Hidden Markov Model,HMM)是結構最簡單的動態貝葉斯網.主要用於時序資料建模,在語音識別,自然語言處理等領域有廣泛應用.隱馬爾可夫模型中有狀態變數(隱變數)和觀測變數兩組變數.
- 馬爾可夫鏈:系統下一時刻的狀態僅有當前狀態決定,不依賴於以往的任何狀態.
- 馬爾可夫隨機場(Markov Random Field,MRF)是典型的馬爾可夫網.每一個結點表示一個或一組變數,結點之間的邊表示兩個變數之間的依賴關係.
- 條件隨機場是判別式模型,可看作給定觀測值的馬爾可夫隨機場.
- 概率圖模型的推斷方法大致分為兩類.第一類是精確推斷,代表性方法有變數消去和信念傳播.第二類是近似推斷,可大致分為取樣(如MCMC取樣)和使用確定性近似完成近似推斷(如變分推斷).
第15章 規則學習
- 規則學習是指從訓練資料中學習出一組能用於對未見示例進行判別的規則.規則學習具有較好的可解釋性,能使使用者直觀地對判別過程有所瞭解.
- 規則學習的目標是產生一個能覆蓋儘可能多的樣例的規則集,最直接的做法是序貫覆蓋,即逐條歸納:每學到一條規則,就將該規則覆蓋的訓練樣例去除.常採用自頂向下的生成-測試法.
- 規則學習緩解過擬合的常見做法是剪枝,例如CN2,REP,IREP等演算法.著名的規則學習演算法RIPPER就是將剪枝與後處理優化相結合.
- 命題規則難以處理物件之間的關係,因此要用一階邏輯表示,並且要使用一階規則學習.它能更容易地引入領域知識.著名演算法有FOIL(First-Order Inductive Learner)等.
第16章 強化學習
- 強化學習的目的是要找到能使長期累積獎賞最大化的策略.在某種意義上可看作具有"延遲標記資訊"的監督學習問題.
- 每個動作的獎賞值往往來自於一個概率分佈,因此強化學習會面臨"探索-利用窘境",因此要在探索和利用中達成較好的折中.ε-貪心法在每次嘗試時以ε的概率進行探索,以均勻概率隨機選取一個動作.以1-ε的概率進行利用,選擇當前平均獎賞最高的動作.Softmax演算法則以較高的概率選取平均獎賞較高的動作.
- 強化學習任務對應的馬爾可夫決策過程四元組已知的情形稱為模型已知.在已知模型的環境中學習稱為"有模型學習".反之稱為"免模型學習".
- 從人類專家的決策過程範例中學習的過程稱為模仿學習.