
「學習筆記」反向傳播Back Propagation
BackPropagation演算法是多層神經網路的訓練中舉足輕重的演算法。
簡單的理解,它的確就是複合函式的鏈式法則,但其在實際運算中的意義比鏈式法則要大的多。
背景知識
簡單表示式和理解梯度
從簡單表示式入手可以為複雜表示式打好符號和規則基礎。先考慮一個簡單的二元乘法函式。對兩個輸入變數分別求偏導數還是很簡單的:
導數的意義:函式變數在某個點周圍的極小區域內變化,而導數就是變數變化導致的函式在該方向上的變化率。
注意等號左邊的分號和等號右邊的分號不同,不是代表分數。相反,這個符號表示操作符被應用於函式
函式關於每個變數的導數指明瞭整個表示式對於該變數的敏感程度。
如上所述,梯度是偏導數的向量,所以有
。即使是梯度實際上是一個向量,仍然通常使用類似“x上的梯度
我們也可以對加法操作求導:
這就是說,無論其值如何,的導數均為1。這是有道理的,因為無論增加
中任一個的值,函式
的值都會增加,並且增加的變化率獨立於
的具體值(情況和乘法操作不同)。取最大值操作也是常常使用的:
上式是說,如果該變數比另一個變數大,那麼梯度是1,反之為0。例如,若,那麼max是4,所以函式對於
就不敏感。也就是說,在
上增加
,函式還是輸出為4,所以梯度是0:因為對於函式輸出是沒有效果的。當然,如果給
增加一個很大的量,比如大於2,那麼函式
的值就變化了,但是導數並沒有指明輸入量有巨大變化情況對於函式的效果,他們只適用於輸入量變化極小時的情況,因為定義已經指明:
。
使用鏈式法則計算複合表示式
現在考慮更復雜的包含多個函式的複合函式,比如。雖然這個表達足夠簡單,可以直接微分,但是在此使用一種有助於讀者直觀理解反向傳播的方法。將公式分成兩部分:
和
。在前面已經介紹過如何對這分開的兩個公式進行計算,因為
是
和
相乘,所以
,又因為
是
加
,所以
。然而,並不需要關心中間量
的梯度,因為
沒有用。相反,函式
關於
的梯度才是需要關注的。鏈式法則指出將這些梯度表示式連結起來的正確方式是相乘,比如
。在實際操作中,這只是簡單地將兩個梯度數值相乘,示例程式碼如下:
# 設定輸入值
x = -2; y = 5; z = -4
# 進行前向傳播
q = x + y # q becomes 3
f = q * z # f becomes -12
# 進行反向傳播:
# 首先回傳到 f = q * z
dfdz = q # df/dz = q, 所以關於z的梯度是3
dfdq = z # df/dq = z, 所以關於q的梯度是-4
# 現在回傳到q = x + y
dfdx = 1.0 * dfdq # dq/dx = 1. 這裡的乘法是因為鏈式法則
dfdy = 1.0 * dfdq # dq/dy = 1
最後得到變數的梯度[dfdx, dfdy, dfdz],它們告訴我們函式f對於變數[x, y, z]的敏感程度。這是一個最簡單的反向傳播。一般會使用一個更簡潔的表達符號,這樣就不用寫df了。這就是說,用dq來代替dfdq,且總是假設梯度是關於最終輸出的。
這次計算可以被視覺化為如下計算線路影象:
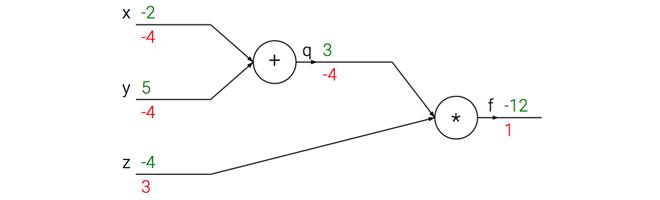
上圖的真實值計算線路展示了計算的視覺化過程。前向傳播從輸入計算到輸出(綠色),反向傳播從尾部開始,根據鏈式法則遞迴地向前計算梯度(顯示為紅色),一直到網路的輸入端。可以認為,梯度是從計算鏈路中迴流。
簡單理解
如下的神經網路

- 前向傳播
對於節點來說,
如下:

接著對

類似的,我們能得到節點、
、
的輸出
、
、
。
- 誤差
得到結果後,整個神經網路的輸出誤差可以表示為:

其中就是剛剛通過前向傳播算出來的
是節點
用來衡量二者的誤差。
這個)
展開得到

- 後向傳播
對輸出層的
通過梯度下降調整
,需要求
,由鏈式法則:
,
如下圖所示:
以上3個相乘得到梯度很多教材比如Stanford的課程,會把中間結果
記做
,表示這個節點對最終的誤差需要負多少責任。所以有
。
對隱藏層的
通過梯度下降調整
,需要求
,由鏈式法則:
,
如下圖所示:
引數
,之後又影響到
、
。
求解每個部分:,
其中,這裡
的計算也類似,所以得到
。
,
相乘得到
得到梯度後,就可以對。
在前一個式子裡同樣可以對
進行定義,
,所以整個梯度可以寫成

