
urllib2 實現簡單爬取12306網站
阿新 • • 發佈:2019-01-10
開發工具:python2.7
主要是用的庫:urllib2
爬取物件:12306購票系統
1、首先我們的任務是選取合適的網頁入口,開啟12306官網:
我們先試試進入餘票查詢:
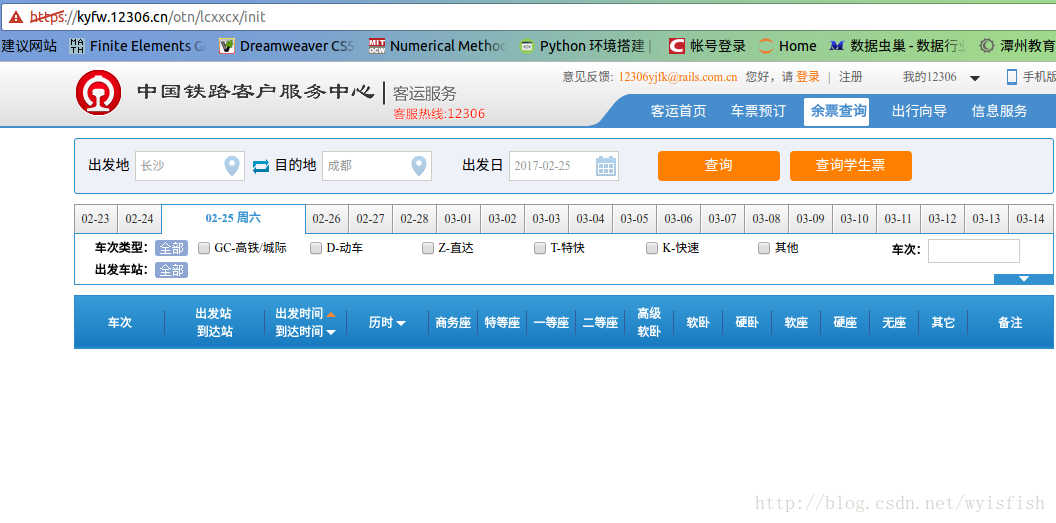
第一次進入這個網站我們發現報錯了,在網址http處紅色顯示證書不符合要求,我們暫時忽略。點選查詢按鈕,這時候我們看到頁面並沒有變化。我們按F12進入開發者工具看看:
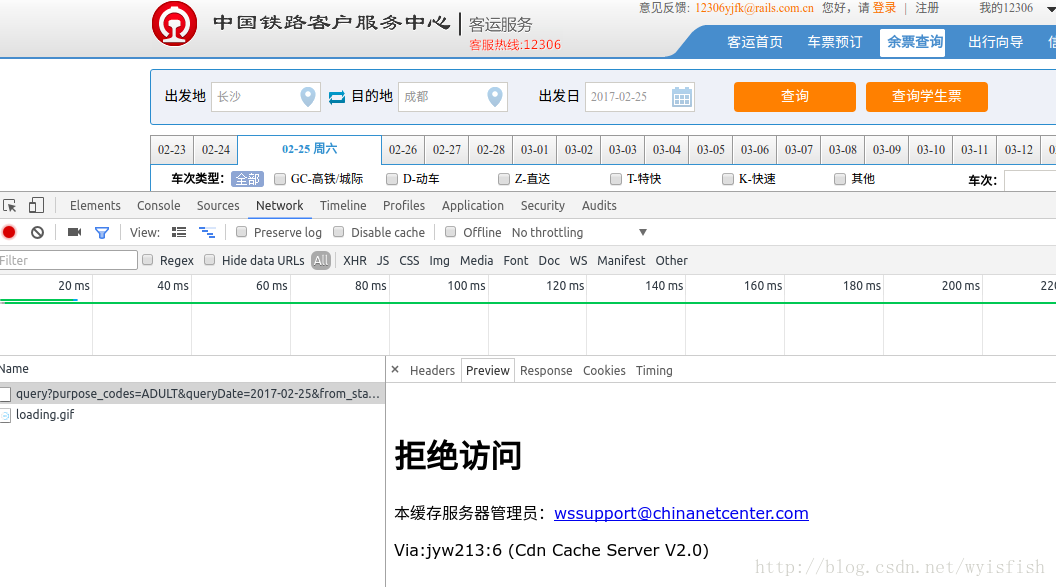
我們進入Network選項,再次點選查詢發現下方顯示拒絕訪問,看來我們無法從這個介面進入網站。
我們返回之前的頁面點選購票: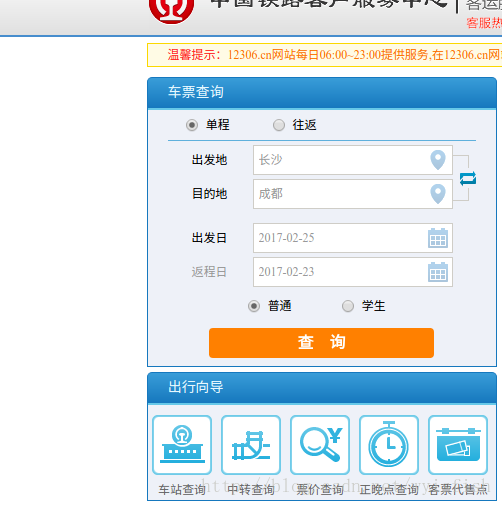
再次點選查詢,這下我們看到了我們查詢的結果,url=https://kyfw.12306.cn/otn/leftTicket/init
然後我們用程式碼來抓取一下這個url:
import urllib2
#我們定義一個函式來抓取這個網站
def getList():
url='https://kyfw.12306.cn/otn/leftTicket/init'
req = urllib2.urlopen(url)
html = req.read()#獲取網站原始碼資料
#print html
getList() #我們嘗試打印出來看看
顯示是一大長串的json檔案。
print type(html)
type ‘str’
我們現在把str轉換成python能處理的dict
import json
dict = json.loads(html)下面我們通過F12開發者工具檢視我們需要的車輛資訊在什麼地方。
通過一番查詢我們發現我們需要的資訊:
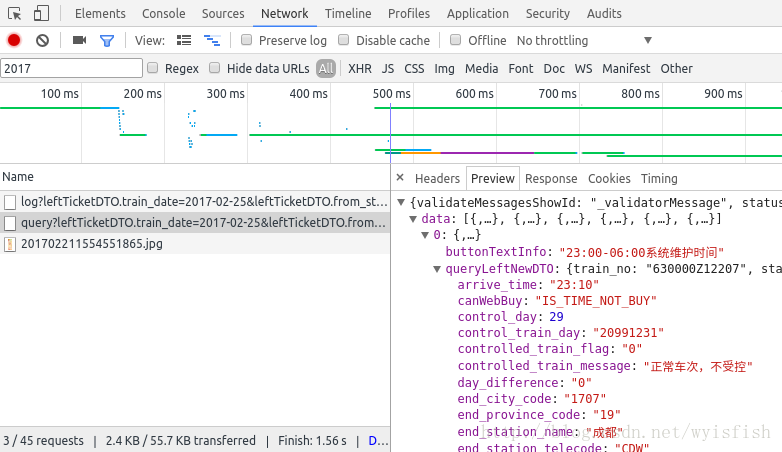
我們通過對比可以看到我們為難剛才打印出來的網頁資訊與我們在F12中找到的是吻合的。我們想要的資訊都在data裡的鍵值對裡。
2、我們提取我們想要的資訊:
import urllib2
import ssl
import json
import time
ssl._create_default_https_context = ssl._create_unverified_context
#關閉證書驗證
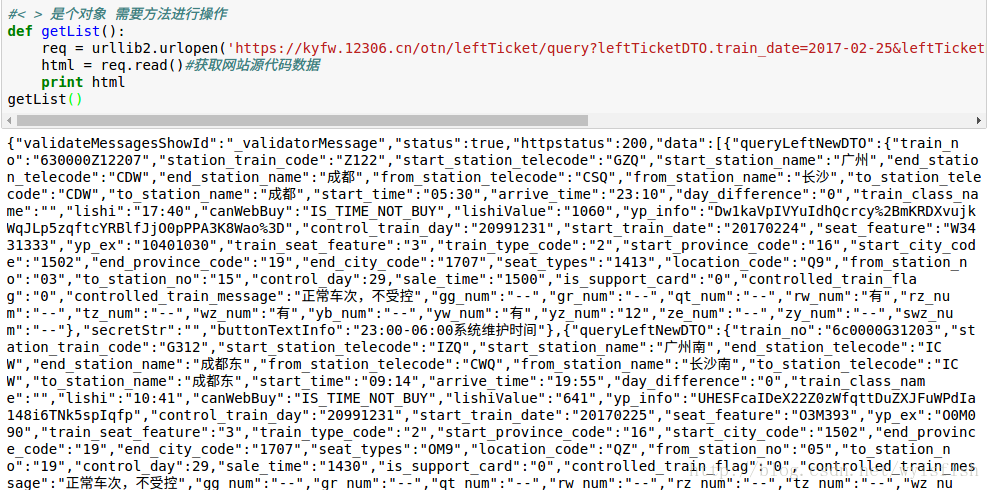
#< > 是個物件 需要方法進行操作 ps:這裡需要提到一點,我們在執行程式碼過程中可能無法開啟網頁,主要是證書無法識別的原因,我們用ssl庫關掉證書認證就可以正常訪問網頁了。
執行結果:

3、實現電話簡訊提醒
4、完成驗證登陸,自動購買車票
上面兩點還沒完成,待續。。。