
三種引數估計方法(MLE,MAP,貝葉斯估計)
以PLSA和LDA為代表的文字語言模型是當今統計自然語言處理研究的熱點問題。這類語言模型一般都是對文字的生成過程提出自己的概率圖模型,然後利用觀察到的語料資料對模型引數做估計。有了語言模型和相應的模型引數,我們可以有很多重要的應用,比如文字特徵降維、文字主題分析等等。本文主要介紹文字分析的三類引數估計方法-最大似然估計MLE、最大後驗概率估計MAP及貝葉斯估計。
1、最大似然估計MLE
首先回顧一下貝葉斯公式
這個公式也稱為逆概率公式,可以將後驗概率轉化為基於似然函式和先驗概率的計算表示式,即
最大似然估計就是要用似然函式取到最大值時的引數值作為估計值,似然函式可以寫做
由於有連乘運算,通常對似然函式取對數計算簡便,即對數似然函式。最大似然估計問題可以寫成
這是一個關於的函式,求解這個優化問題通常對
求導,得到導數為0的極值點。該函式取得最大值是對應的
的取值就是我們估計的模型引數。
以扔硬幣的伯努利實驗為例子,N次實驗的結果服從二項分佈,引數為P,即每次實驗事件發生的概率,不妨設為是得到正面的概率。為了估計P,採用最大似然估計,似然函式可以寫作
其中表示實驗結果為i的次數。下面求似然函式的極值點,有
得到引數p的最大似然估計值為
可以看出二項分佈中每次事件發的概率p就等於做N次獨立重複隨機試驗中事件發生的概率。
如果我們做20次實驗,出現正面12次,反面8次
那麼根據最大似然估計得到引數值p為12/20 = 0.6。
2、最大後驗估計MAP
最大後驗估計與最大似然估計相似,不同點在於估計的函式中允許加入一個先驗
,也就是說此時不是要求似然函式最大,而是要求由貝葉斯公式計算出的整個後驗概率最大,即
注意這裡P(X)與引數無關,因此等價於要使分子最大。與最大似然估計相比,現在需要多加上一個先驗分佈概率的對數。在實際應用中,這個先驗可以用來描述人們已經知道或者接受的普遍規律。例如在扔硬幣的試驗中,每次丟擲正面發生的概率應該服從一個概率分佈,這個概率在0.5處取得最大值,這個分佈就是先驗分佈。先驗分佈的引數我們稱為超引數(hyperparameter)即
同樣的道理,當上述後驗概率取得最大值時,我們就得到根據MAP估計出的引數值。給定觀測到的樣本資料,一個新的值發生的概率是
下面我們仍然以扔硬幣的例子來說明,我們期望先驗概率分佈在0.5處取得最大值,我們可以選用Beta分佈即
其中Beta函式展開是
當x為正整數時
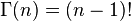
Beta分佈的隨機變數範圍是[0,1],所以可以生成normalised probability values。下圖給出了不同引數情況下的Beta分佈的概率密度函式

我們取,這樣先驗分佈在0.5處取得最大值,現在我們來求解MAP估計函式的極值點,同樣對p求導數我們有
得到引數p的的最大後驗估計值為
和最大似然估計的結果對比可以發現結果中多了這樣的pseudo-counts,這就是先驗在起作用。並且超引數越大,為了改變先驗分佈傳遞的belief所需要的觀察值就越多,此時對應的Beta函式越聚集,緊縮在其最大值兩側。
如果我們做20次實驗,出現正面12次,反面8次,那麼
那麼根據MAP估計出來的引數p為16/28 = 0.571,小於最大似然估計得到的值0.6,這也顯示了“硬幣一般是兩面均勻的”這一先驗對引數估計的影響。
3 貝葉斯估計
貝葉斯估計是在MAP上做進一步拓展,此時不直接估計引數的值,而是允許引數服從一定概率分佈。回顧一下貝葉斯公式
現在不是要求後驗概率最大,這樣就需要求,即觀察到的evidence的概率,由全概率公式展開可得
當新的資料被觀察到時,後驗概率可以自動隨之調整。但是通常這個全概率的求法是貝葉斯估計比較有技巧性的地方。
那麼如何用貝葉斯估計來做預測呢?如果我們想求一個新值的概率,可以由
來計算。注意此時第二項因子在上的積分不再等於1,這就是和MLE及MAP很大的不同點。
我們仍然以扔硬幣的伯努利實驗為例來說明。和MAP中一樣,我們假設先驗分佈為Beta分佈,但是構造貝葉斯估計時,不是要求用後驗最大時的引數來近似作為引數值,而是求滿足Beta分佈的引數p的期望,有

注意這裡用到了公式
當T為二維的情形可以對Beta分佈來應用;T為多維的情形可以對狄利克雷分佈應用
根據結果可以知道,根據貝葉斯估計,引數p服從一個新的Beta分佈。回憶一下,我們為p選取的先驗分佈是Beta分佈,然後以p為引數的二項分佈用貝葉斯估計得到的後驗概率仍然服從Beta分佈,由此我們說二項分佈和Beta分佈是共軛分佈。在概率語言模型中,通常選取共軛分佈作為先驗,可以帶來計算上的方便性。最典型的就是LDA中每個文件中詞的Topic分佈服從Multinomial分佈,其先驗選取共軛分佈即Dirichlet分佈;每個Topic下詞的分佈服從Multinomial分佈,其先驗也同樣選取共軛分佈即Dirichlet分佈。
根據Beta分佈的期望和方差計算公式,我們有

可以看出此時估計的p的期望和MLE ,MAP中得到的估計值都不同,此時如果仍然是做20次實驗,12次正面,8次反面,那麼我們根據貝葉斯估計得到的p滿足引數為12+5和8+5的Beta分佈,其均值和方差分別是17/30=0.567, 17*13/(31*30^2)=0.0079。可以看到此時求出的p的期望比MLE和MAP得到的估計值都小,更加接近0.5。
綜上所述我們可以視覺化MLE,MAP和貝葉斯估計對引數的估計結果如下

個人理解是,從MLE到MAP再到貝葉斯估計,對引數的表示越來越精確,得到的引數估計結果也越來越接近0.5這個先驗概率,越來越能夠反映基於樣本的真實引數情況。
參考文獻
Gregor Heinrich, Parameter estimation for test analysis, technical report
Wikipedia Beta分佈詞條 , http://en.wikipedia.org/wiki/Beta_distribution